LLM 救星?DeepSeek 推出 DeepSeek-OCR,Token 節省高達 90%
(硬是要學/手哥 HANDBRO 報導)
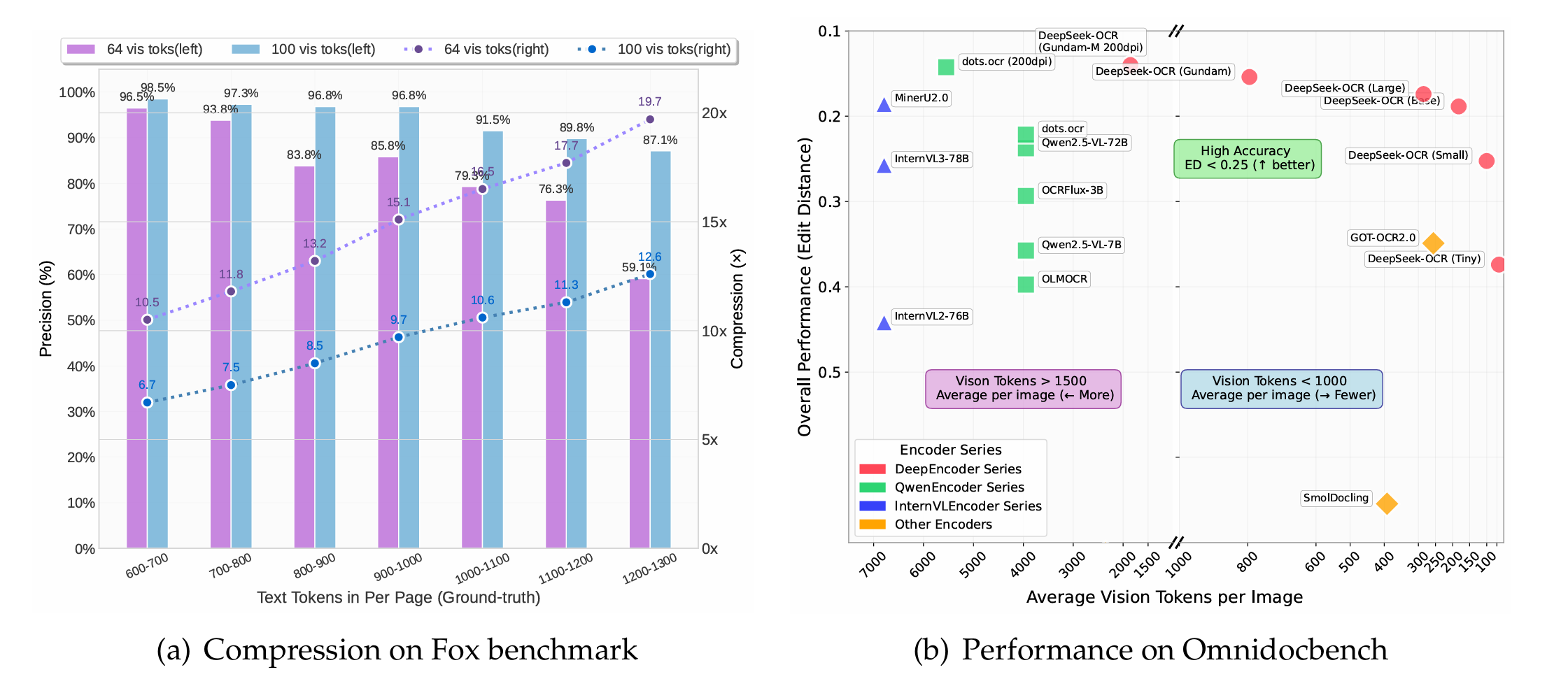
在處理長篇文本時,LLM 往往會因序列過長而消耗大量資源,DeepSeek-AI 最新發表的研究成果 —— D […]
本文 LLM 救星?DeepSeek 推出 DeepSeek-OCR,Token 節省高達 90% 最早出現於 硬是要學。
(硬是要學/手哥 HANDBRO 報導)
在處理長篇文本時,LLM 往往會因序列過長而消耗大量資源,DeepSeek-AI 最新發表的研究成果 —— D […]
本文 LLM 救星?DeepSeek 推出 DeepSeek-OCR,Token 節省高達 90% 最早出現於 硬是要學。
「阿正老師,AI 工具好多,我到底該用哪一個?」這是我這陣子最常收到的問題。老實說,光 2026 年就冒出幾百 […]
這篇文章 2026 免費 AI 工具懶人包:30 款工具依用途分類,找到你需要的那一款! 最早出現於 軟體玩家。

由中國 AI 新創「深度求索」所推出號稱最強開源模型 Deepseek V4 系列自推出以來,讓世人最驚艷的除 […]
The post DeepSeek V4 API 價格為何如此便宜?KV Cache 極致壓縮的技術揭密 appeared first on 電腦王阿達.
中美科技角力持續升溫,中國政府對核心技術的保護已從限制半導體硬體出口,全面延伸至管控「人類大腦」。據《彭博》( […]
The post 中國擴大 AI 人才出境管制:傳阿里巴巴、DeepSeek 相關高層被要求上繳護照 appeared first on 電腦王阿達.
隨著 AI 越來越強大,很多人一定會好奇,如果是用在資安的場景,能不能真的找出漏洞?國外資安研究員 Kasra Rahjerdi 最近就做了這項實驗,故意設計一款有漏洞的假 App,然後花了 1,500 美元,測試 GPT-5.5、Claude、Gemini、DeepSeek、Qwen、Kimi 等多款模型能不能找出真正漏洞。沒想到,原本以為 Claude 在這塊應該會領先,結果是 GPT-5.5 奪冠,在 10 次測試中成功 7 次,是這次成功率最高的模型,而且這次數還遙遙領先其他對手。而看成本效率的話,DeepSeek V4 Pro 相當不錯,每次成功平均只花 0.62 美元。至於 Gemini,這次表現就有點慘,跑很多幾乎一開始就因為安全理由拒絕繼續,完全不想嘗試。
The post 國外安全研究員砸 1,500 美元實測 13 款 AI 駭客能力:GPT-5.5 奪冠,Gemini 幾乎直接放棄 appeared first on 電腦王阿達.