Anthropic「蒸馏」了人类最大的知识库

2024 年初,在美国某处的一座仓库里,工人们正在做一件看起来有些奇怪的事:把书一本本送进机器,切掉书脊,扫描,然后把剩下的纸送去回收。
这些书是刚买来的,有些甚至是新的。没有人会读它们,它们存在的唯一目的,就是被销毁。
下令做这件事的,是一家叫 Anthropic 的 AI 公司。

在他们的内部文件里,这项计划有个代号:「巴拿马项目」。一份规划文件写得很直白:「这是我们以破坏性方式扫描全球所有书籍的计划,我们不希望外界知道我们正在做这件事。」
这件事最终还是被人知道了。
去年,一名联邦法官解封了一批与版权诉讼相关的文件,总计超过 4000 页。外界由此看到的,不只是一家公司的秘密,而是整个 AI 行业在数据争夺战中的真实面目。
被大模型「吃」掉的实体书
为什么这些处于技术前沿的科技巨头,会用如此原始甚至粗暴的方式对待纸质书?答案其实藏在 AI 对高质量数据的极度渴求里。
Anthropic 内部很早就意识到,训练 AI 模型光靠网络上的内容不够用。
根据《华盛顿邮报》报道,一位Anthropic 联合创始人在 2023 年 1 月的文件中写道,用书籍训练模型,可以让 AI 学会「如何写得更好」,而不是只会模仿质量参差不齐的网络语言。
书籍经过严格编辑和校对,内容结构清晰,是网络文本难以替代的高质量语料。
这个逻辑本身并不难理解,但问题是,既然承认书籍有价值,为什么不付钱?究其原因,挨个找出版社和作者谈授权,费时费力,成本也高。于是 Anthropic 启动了「巴拿马项目」。一句「不希望外界知道」,说明它也清楚这件事站不住脚。
甚至「巴拿马项目」还没启动的时候,Anthropic 已经尝试通过另一种方式获取书籍。

法院文件显示,公司联合创始人 Ben Mann 曾在 2021 年 6 月的 11 天里,从一个叫 LibGen 的网站下载了大量小说和非小说类书籍。LibGen 是个「影子图书馆」,上面的资源大多涉嫌侵权,文件中附带的浏览器截图显示,他使用文件共享软件完成了这些下载。
一年后,另一个网站 Pirate Library Mirror 于 2022 年 7 月上线,该网站公开宣称「在大多数国家故意违反版权法」。Mann 把这个网站的链接发给了其他 Anthropic 员工,并留言写道:「来得正是时候!!!」
这句感叹号背后,是一位公司高管对一个公开承认违法的盗版网站表达的真实态度。
Anthropic 事后表示,公司从未用这些数据训练过正式发布的商业模型。但这种解释多少有些勉强,下载了,存着,只是「没有用在正式模型上」,这条线究竟划在哪里,恐怕连 Anthropic 自己也说不清楚。
为了「巴拿马项目」,Anthropic 还专门聘请了 Tom Turvey 来主持这项工作。Turvey 曾参与创建谷歌图书项目,那个项目同样因大规模扫描书籍引发了长达多年的版权争议。Anthropic 选择这个人来主导这件事,很难说是一种巧合。
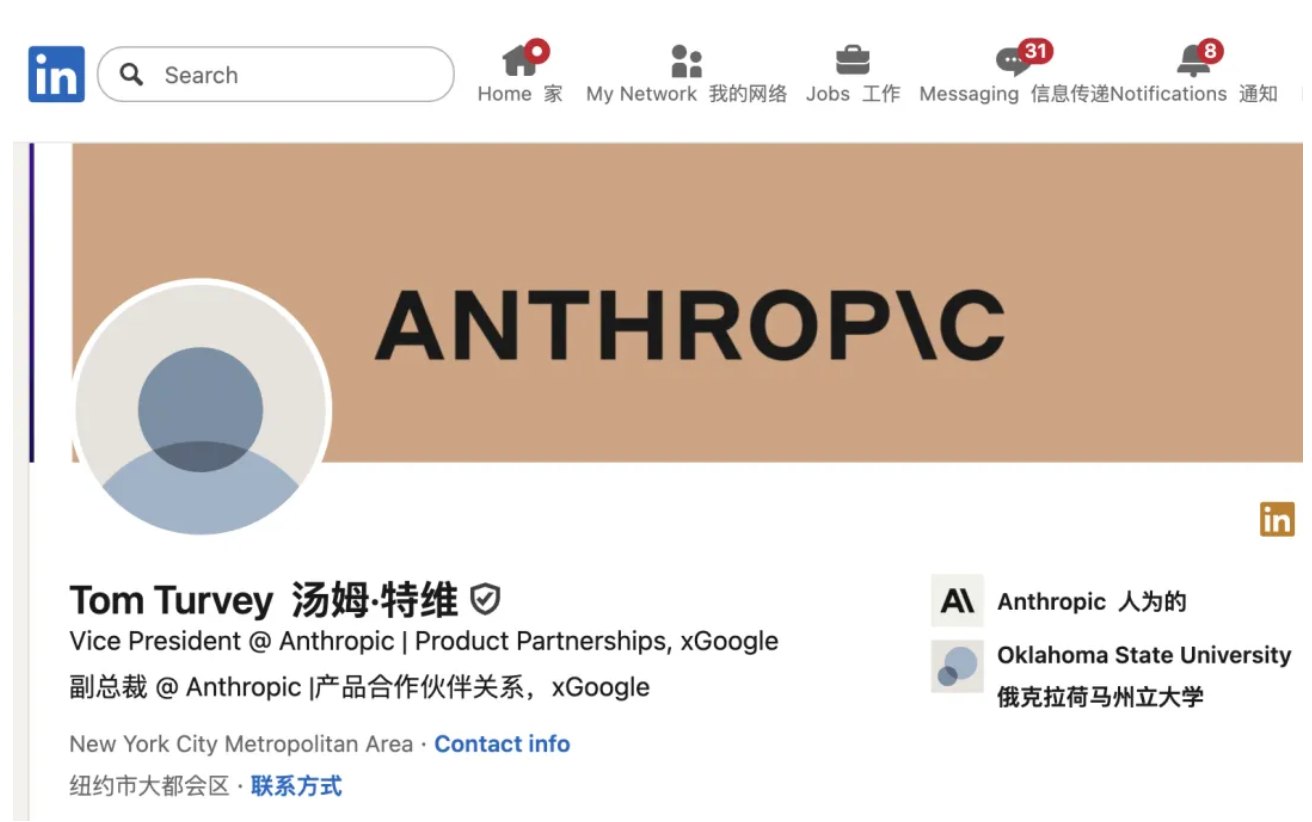
最终,Anthropic 主要依赖两家书商批量供货:
美国二手书零售商 Better World Books,以及总部位于英国的 World of Books,每次采购动辄数万册。内部文件还显示,员工曾讨论接洽纽约公共图书馆,甚至提到可以找某家长期资金不足的新图书馆。
采购完之后,整个扫描过程,就像一条工业流水线。

供应商用液压切割机把书脊整齐切掉,散开的书页随即被送进高速工业扫描仪,扫完之后,剩下的纸张交给回收公司处理。一家参与报价的扫描服务商在提案中写道,Anthropic 希望在六个月内完成 50 万到 200 万册书的数字化工作。
Anthropic 副总法律顾问 Aparna Sridhar 回应称,法院已裁定 AI 训练「本质上具有转化性」,Anthropic 选择和解的问题在于「部分材料的获取方式,而不是我们是否可以使用这些材料」。
这套说辞在法律上也许站得住脚,但它同时也揭示了一件事:这家公司从未认为自己做错了什么,只是某些手段不够干净。
拿你的书训练,再抢你的饭碗
同样的事情,也在其他公司身上发生着,而且有些细节更为戏剧性。
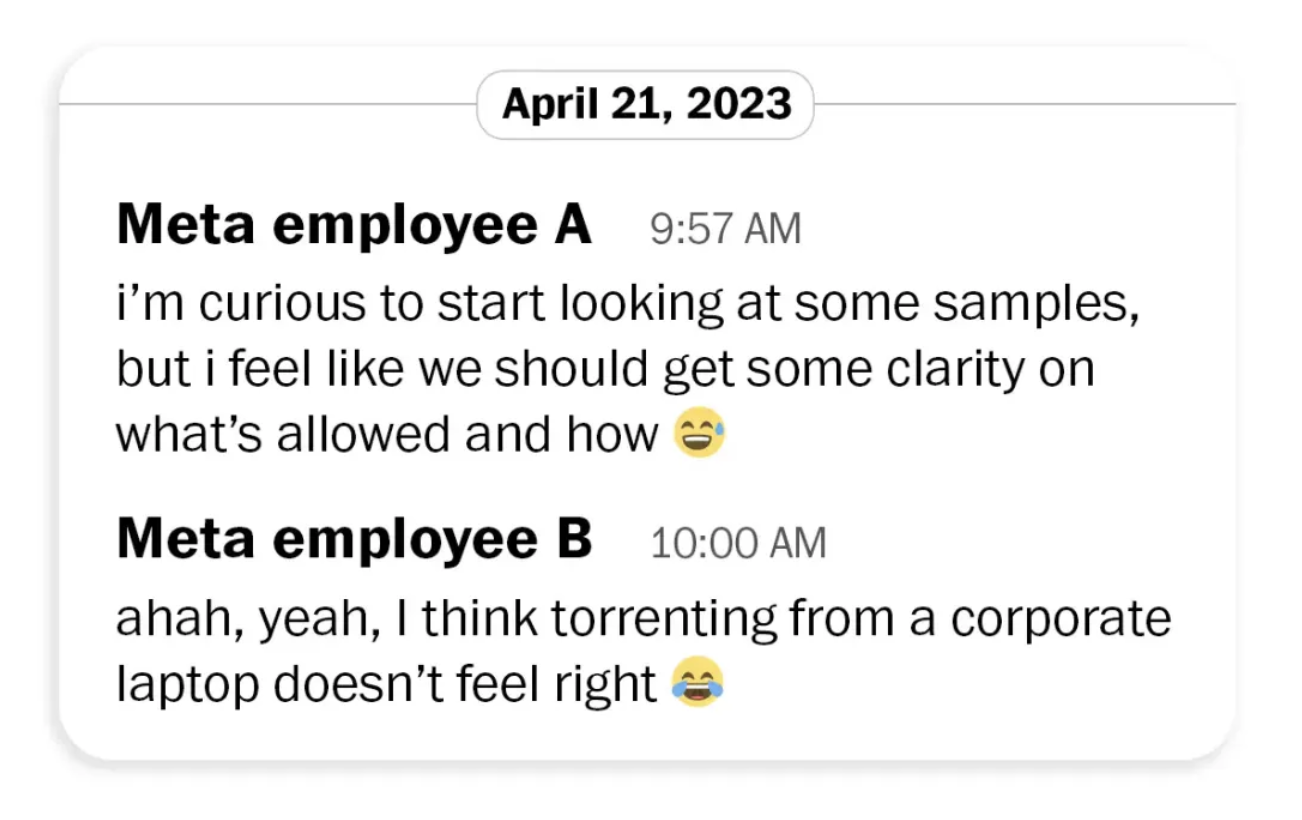
针对 Meta 的诉讼文件显示,有员工在 2023 年直接写道:「用公司笔记本进行种子下载感觉不太对劲。」他后来还专门向法务团队反映,称使用种子网站可能意味着向他人分发盗版作品,「这在法律上可能行不通。」
但这些顾虑最终没有改变任何事情。
2023 年 12 月的一封内部邮件显示,使用 LibGen 已在「上报至 MZ」之后获批,MZ 指的是 CEO 马克·扎克伯格。邮件还坦率地写明了他们自己都清楚的风险:「如果媒体报道暗示我们使用了已知为盗版的数据集,这可能会削弱我们在监管问题上的谈判立场。」
换句话说,他们不是不知道这样做不对,只是在权衡被抓包的代价。为了降低这个风险,员工们特意租用亚马逊的服务器来做种子下载,而不是用 Meta 自己的服务器,原因是避免被追踪到 Meta 公司。
OpenAI 和微软同样面临图书作者的版权指控。OpenAI 甚至承认曾下载过 LibGen,但称在 ChatGPT 发布前已删除相关文件。
而 AI 公司与创作者之间的版权冲突,并非从 Anthropic 才开始。
早在 2000 年代初,Google 就曾大规模扫描图书馆馆藏,同样引发了长达十年的诉讼。最终法院认定Google 的做法属于「合理使用」,因为它只提供片段摘要,目的是引导读者找到书,而不是取代书本身。
这个判决在当时看来合情合理,却在二十年后为整个 AI 行业提供了一块挡箭牌。
Google 图书是个索引工具,而生成式 AI 直接消化书籍内容,然后输出文字,在某些情况下与作者产生直接竞争。性质变了,但援引的法律逻辑还是同一套,这本身就值得思考。

去年 6 月,联邦法官 William Alsup 裁定,Anthropic 用书籍训练 AI 属于合法行为,他将这个过程比作教师「训练学生写好文章」。这个比喻听起来温和,但现实中的老师不会同时训练几百万个学生,也不会靠这些学生赚几十亿美元。
最终,Anthropic 选择支付 15 亿美元和解金,在 AI 版权诉讼史上创下纪录,但细看之下,账算得并不亏。按照美国版权法,每件作品的法定赔偿上限可达 15 万美元,而此次和解折算下来,每本书约赔 3000 美元,仅为上限的 2%。
赔偿金由作者和出版商平分,只是,这一安排在创作者群体内部引发了争议。
不少作者认为,出版商在保护作品不被 AI 滥用这件事上没有尽力,却拿走了一半赔偿。更关键的是,和解协议并不要求 Anthropic 承认任何违法行为,法院对「AI 训练属于合理使用」的认定照样有效。

换句话说,Anthropic 用 15 亿美元买到的,不只是和解,还有一份背书:我们可以继续这么做。有分析人士指出,随着这个先例确立,版权侵权对 AI 公司来说已经不再是一条红线,而是一笔可以提前计入成本的「过路费」。
对许多写书的人来说,这件事意味着的远不止一张支票。美国作家的年收入中位数约为 2 万美元,而市值数千亿的 AI 公司在未获授权的情况下大量使用他们的作品,事后折算的赔偿标准远低于法律上限。
更让人忧虑的是,AI 正在批量生成文字内容,这些低成本的文本涌入市场,让原本就艰难的写作谋生变得更难。训练 AI 用的是人写的书,而 AI 产出的内容,正在挤压人继续写书的空间,循环往复。
支持者自有另一套逻辑:AI 并不储存书里的内容,而是从中提取语言规律,这更像是一个人博览群书之后形成自己的表达。这个类比并非毫无道理,但却省略了一个关键差异:
人读了一本书,不会同时读一百万本;而 AI 在几个月内消化了人类几十年的写作积累,随后以极低的边际成本无限复制输出,规模改变了性质,把两件事等同起来其实并不合理。
数百万册书被切开、扫描、回收,最后换来一份和解协议。那些书,早已不在了。而 AI 还在继续写作,且会越来越快。这大概就是这件事最让人不安的地方:对于书被销毁,被肆意用来训练 AI 这件事,没有人真正付出了代价。
附上参考地址:
https://www.washingtonpost.com/technology/2026/01/27/anthropic-ai-scan-destroy-books/
#欢迎关注爱范儿官方微信公众号:爱范儿(微信号:ifanr),更多精彩内容第一时间为您奉上。