Sight & Sound 2025最佳电影|NO.5:《秘密特工》(克莱伯·门多萨·菲略)
影片设定在 20 世纪 70 年代巴西军政府独裁统治时期,讲述一位学者在一次反抗行动后被迫逃亡的经历。克莱伯·门多萨·菲略(Kleber Mendonça Filho)这部不断带来惊喜的惊悚片,兼具悬念与幽默,同时也是一堂重要的历史课。

春节假期,帮亲戚朋友们部署 OpenClaw 成了我一份额外的工作。虽然不一定能真正用上,但这只龙虾是不得不拥有。
AI 进入我们的工作流,在 OpenClaw 爆火之后,这种感觉变得更加强烈。在「不用 AI 会被淘汰,用了 AI 也像是能被替代」的悖论下,不错过任何一个能放大自身价值的 AI 工具,让人陷入了无止境的 FOMO。

越来越多的「龙虾变体」也涌现出来,但是当被问到打算怎么把这个部署好的 OpenClaw 融入工作流,答案往往又是个未知数。更不用说光是部署好 OpenClaw,就有两道大关,一是要手动部署和配置复杂的模型 API,二是让人心疼的额外 API 费用。
今天,更新后的 MiniMax Agent 推出了两项新功能。
专业度更高,更会干活的 Expert 智能体社区,涵盖从技术开发、创意写作到音视频图片生成等多模态领域,超过 1.6 万个专家,且还在持续增长。大多数场景下,我们几乎都能直接找到现成可用的专家;即便没有完全匹配的,用几句话还能快速创建一个自己的 Expert。
另一项新增的 MaxClaw 模式,能让我们一键打通 OpenClaw 生态,而且完全不需要自己配置 API,以及承担额外的 API 费用,解决了「不知道 OpenClaw 能做什么」和「怎么部署 OpenClaw」这两个问题。
这也就意味着,即便是纯小白,现在也能拥有开箱即用的专属 AI 专家团队了。
APPSO 也实测了一波智能体专家和 MaxClaw 这两项新功能,它确实和一般的智能体 Agent 不同,结合了 Skills 的能力和 OpenClaw 的兼容能力,我们直接就能操作飞书、钉钉等即时通讯软件。
而和市面上不同版本的 OpenClaw 对比,MiniMax Agent 的 MaxClaw 又有了预置的专家智能体,整个体验会更加友好。
体验地址:国内版 https://agent.minimaxi.com
https://agent.minimaxi.com
海外版 https://agent.minimax.io
对于 AI 创作来说,无论是文本还是多媒体,大多数时候用大模型,最痛苦的就是「AI 味太重」或者「废话连篇」。究其原因,往往是「提示词不当」、「模型不够强」,总结在普通的聊天形式缺乏深度的垂直领域优化。
MiniMax Agent 这次推出的 Expert(专家智能体) 虽然还是在聊天对话里进行,但底层逻辑做了一些改变。它主打即开即用,提供了针对各种深度垂类场景优化的 Agent。
▲MiniMax Agent 内提供了办公效率、商业金融、教育学习、生活娱乐等上万个专家
在处理对应垂直领域的任务上,和非专家的单纯对话形式相比,专家能交付更专业、质量更高的结果。为了验证这一点,我们直接从它目前已经 1.6w+公开的 Expert 库(大部分是用户创作)里,挑了几个热门的场景进行实测。
从目前 Expert 社区的使用热度来看,用户最先跑起来的,往往还是那些直接指向生产力的刚需场景,比如办公制作、内容搭建,以及金融与行业分析。
在 MiniMax Agent 首页,我们点击左侧边栏的「探索专家」,就能进入已经按场景分好类的专家社区。不同专家不仅标注了能力方向,还能看到背后调用的「子代理」和完整项目指令,相当于把一套成熟工作流直接摆在用户面前。
找到合适的专家后,点击「开始聊天」,输入需求,它就会按既定流程自动推进任务。
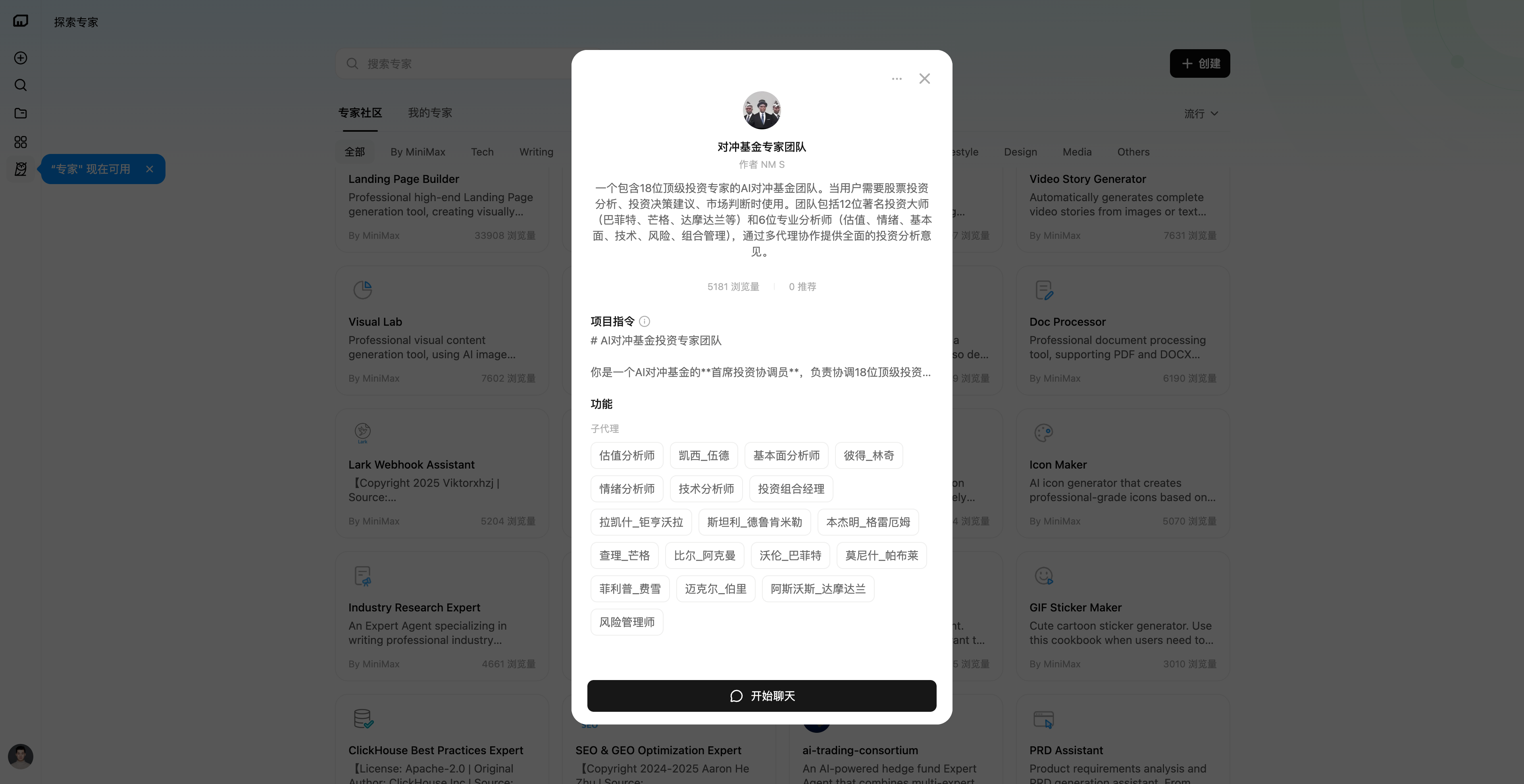
▲股票价值分析专家介绍
在办公与内容生产场景中,落地页生成和 PPT 制作依然是浏览量最高的一类专家。
我们先测试了 Landing Page Builder 专家。输入需求:「我要给初中生做一个五代十国历史的网页,得让他们真的能听进去,内容翔实有考据,一节课 45 分钟的内容。要解释清楚、配图到位、动效得当、沉浸感强,举的例子能让他们产生共鸣,再加几道题检验下理解程度。」
整个过程中,专家几乎不需要额外干预,而是按照预设流程自动完成结构设计、内容填充和页面生成。
▲预览链接:https://qvwu1nyvju2u.space.minimax.io/
从最终效果来看,这类 Expert 和传统 Agent 最大的区别在于,它从边聊天边拼凑,转成了沿着一条完整生产流程在推进,结果的稳定性和完成度明显更高。
生成的网页不仅信息完整,画面和动效也有一定沉浸感,相比过去一些 vibe coding 产品常见的模板化和渐变紫风格,要更克制也更可用。
在偏专业的分析类任务上,Expert 的优势会更明显。我们选择了 McKinsey PPT(麦肯锡风格演示文稿生成)专家进行测试。按照介绍,它会自动补充数据、图表以及行业洞察。
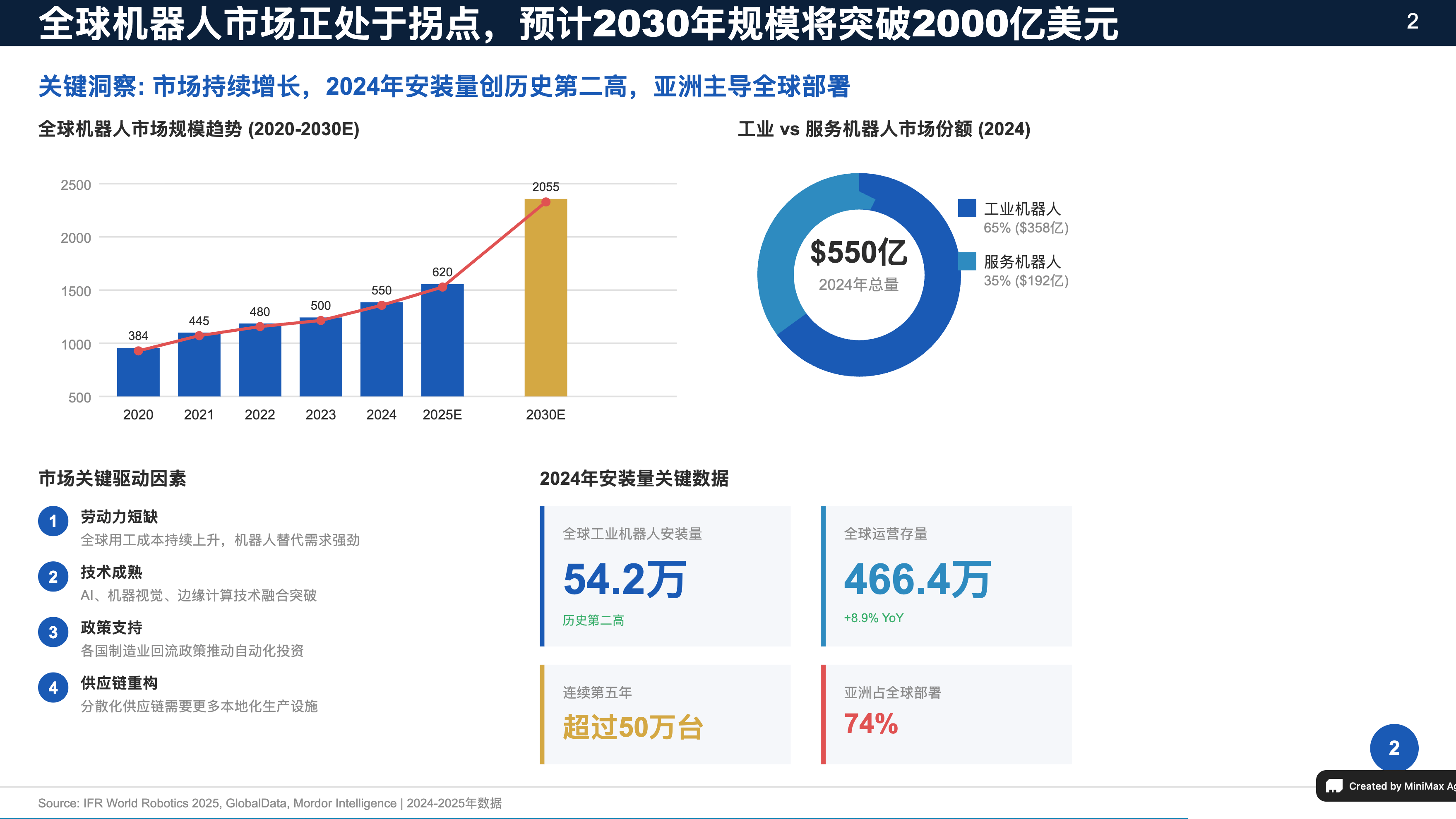
实际测试中,我们只输入了一句非常简单的需求,「制作一份关于全球机器人市场的10页幻灯片演示文稿」。但最终生成的 PPT,在信息密度、结构完整度和图表配置上都没有明显缩水,基本具备拿来就能用的初稿质量。
这类场景也很能体现 Expert 的定位,它尝试把一整段专业工作流程产品化,从增强单次问答的模式里彻底跳了出来。
还没听说过有能生成视频的通用 Agent 产品,但现在结合多个不同的 Skills、Agents 的专家,输入一段剧情,直接就能给我们一部短剧。
▲提示词:霸总重生在电子厂打螺丝,宫崎骏动漫风格,1-3分钟视频长度,台词激烈有冲突,剧情跌宕起伏有反转。
我们使用 AI 短剧导演+摄影+剪辑师专家进行测试,和一般的视频生成模型只能产出 5-10s 左右的视频不同,这个专家能自动生成完整的分镜,并且把视频进行剪辑和拼接。

最后生成的视频,完成度很高,虽然没能对口型把台词一字一句说出来,但是也配了一段应景的 BGM。而且大概率是检测到了提示词里面的「宫崎骏」,整个动画的风格,乃至角色和公司名字,都透露着一股日漫的味道。
如果觉得官方或别人做的专家,还不够贴合我们的使用习惯和工作场景,MiniMax Agent 也提供了自定义功能,通过简单的一两句话就能创建一个专家。
我们完全不需思考什么是 Skill 或者专家,也不用遵守标准文件的规则设置等,只需要通过自然语言交互,就能更方便地把个性化的工作流、SOP 等集成,创建专属 Expert。
热点追踪是媒体编辑一项非常重要的工作,我们在 MiniMax Agent 的专家社区里,也使用过多次热点追踪的专家。例如当我们要求它基于输入的「春晚被机器人刷屏」这个主题,去搜索最新消息和近期热门话题时;它最后能给我们一份完整详细的长文,但是不够个性化。
于是,我们开始自己来创建一个 APPSO 的热点追踪。
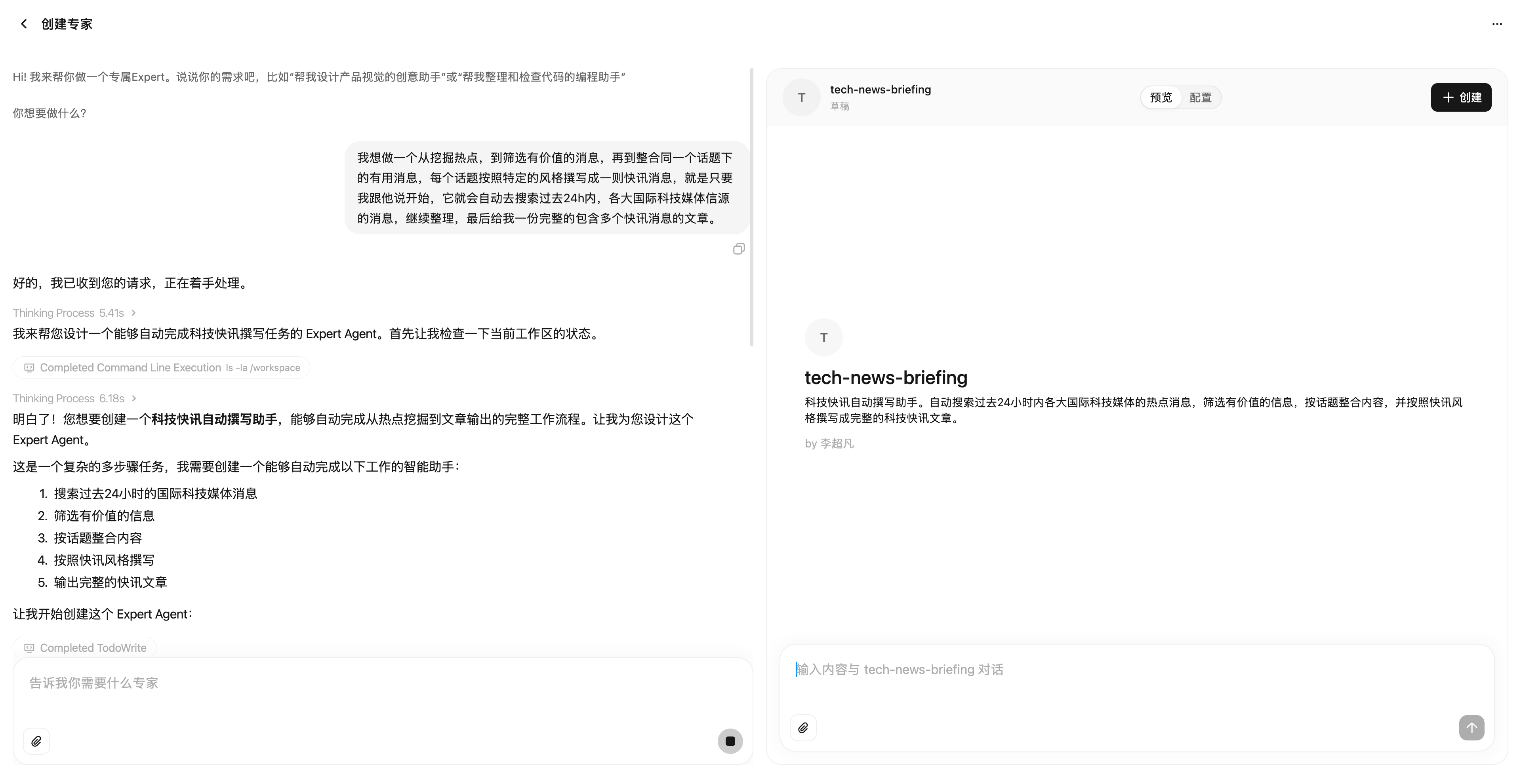
▲在探索专家页面右上角点击「创建专家」,输入自己的需求,MiniMax Agent 会自动帮我们完成创建
创建专家的过程是可以连续对话,如果对目前专家的输出不满意,我们可以继续在对话框内要求 MiniMax Agent 进行更新。
创建完成之后,我们只需要发送一句「开始,帮我整理今天的科技快讯」,专家就会给我们 24h 内最值得关注的 AI 消息,并且以早报的文风和格式要求写好。此外,这些自己创建的专家,MiniMax 还提供了 15 轮免费,即不消耗积分的优惠,体验门槛更低。

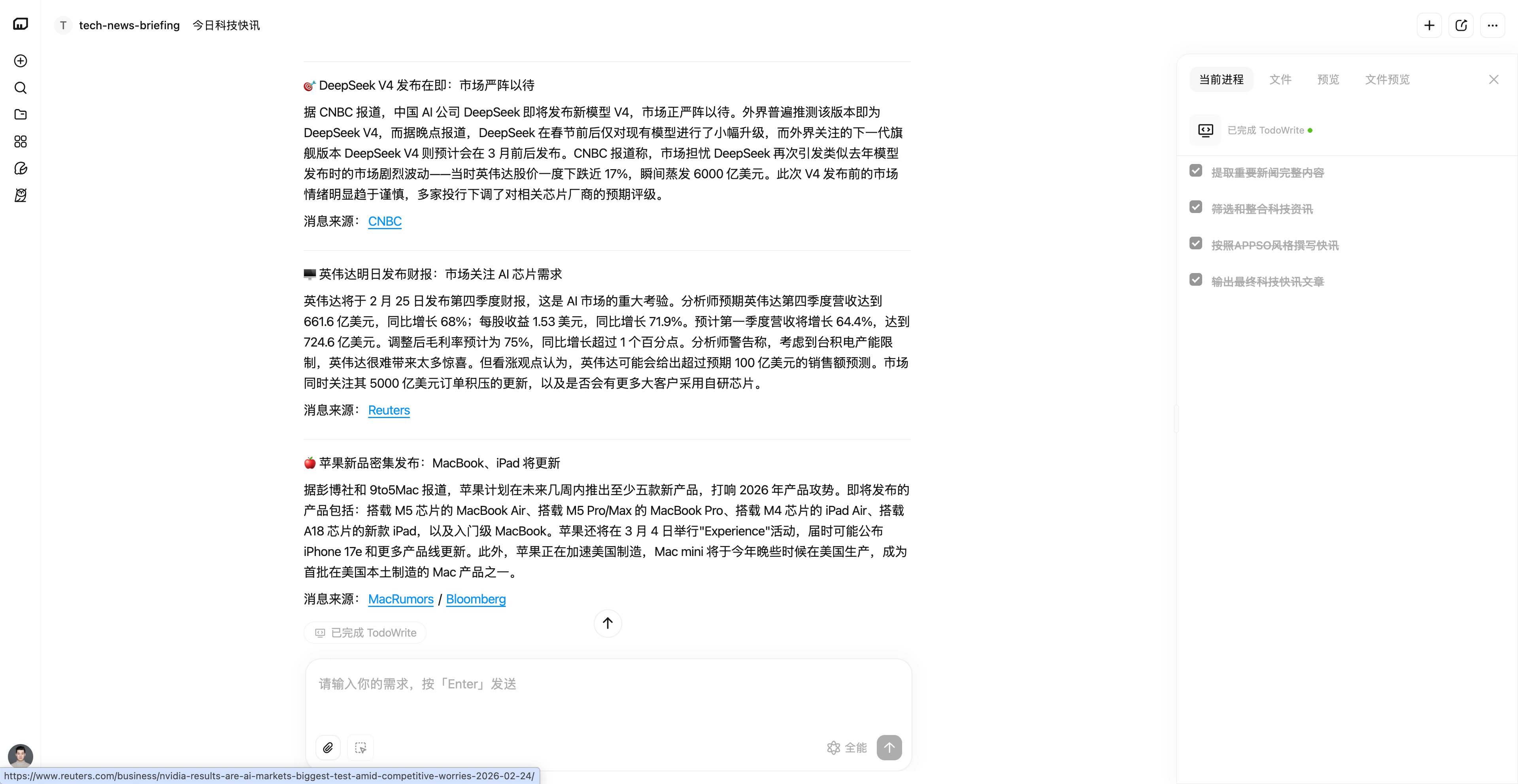
▲APPSO 自定义的专家,现在可以自主完成一份快讯早报
除了大量可以直接使用和自定义的 Experts,更值得关注的是即将上线的 Marketplace。用户创建的 Expert,如果被使用,就能获得相应的积分,可以用来在 MiniMax Agent 里完成更多的任务。
而后续 MiniMax 还将开放专家自行定价,这意味着如果你在某个垂直领域有真正的专业积累,封装成 Expert 除了分享自用,还可能是一种新的变现路径。
说白了,一个 Skills 专家的应用商店雏形,已经摆在我们面前了。
如果说 Expert 是强大的大脑,那么 MaxClaw 就是让大脑连接到现实的双手,这也是 MiniMax Agent 这次升级里,玩法最丰富的一个功能。我把它叫做升级版的 OpenClaw。
根据网络上到处都是的 OpenClaw 指南,想要真正好用的OpenClaw生态,我们要先学会手动部署、配置复杂的模型API,还要时刻盯着后台,生怕一不小心跑出天价的 API 账单。
对于绝大多数不懂代码的普通小白来说,这门槛属实是太高了。我只是想把好用的 AI 接入自己的飞书或钉钉,创建一个机器人,但是第一步就困住了。

MiniMax Agent 新增的 MaxClaw 模式,一键打通了 OpenClaw 生态,不需要繁琐的手动部署和配置模型 API,通过MiniMax Agent 网页端就可以快速上手。
目前,它也兼容手机端多个即时通讯交互工具,我们可以在飞书、钉钉、Telegram、WhatsApp、Discord、Slack 中使用。
拿部署到飞书机器人举例,甚至不用额外的部署指南,我们只需要点开首页左侧边栏的 MaxClaw 按钮,点击「立即开始」,我们可以选择使用默认配置,或者其他专家。
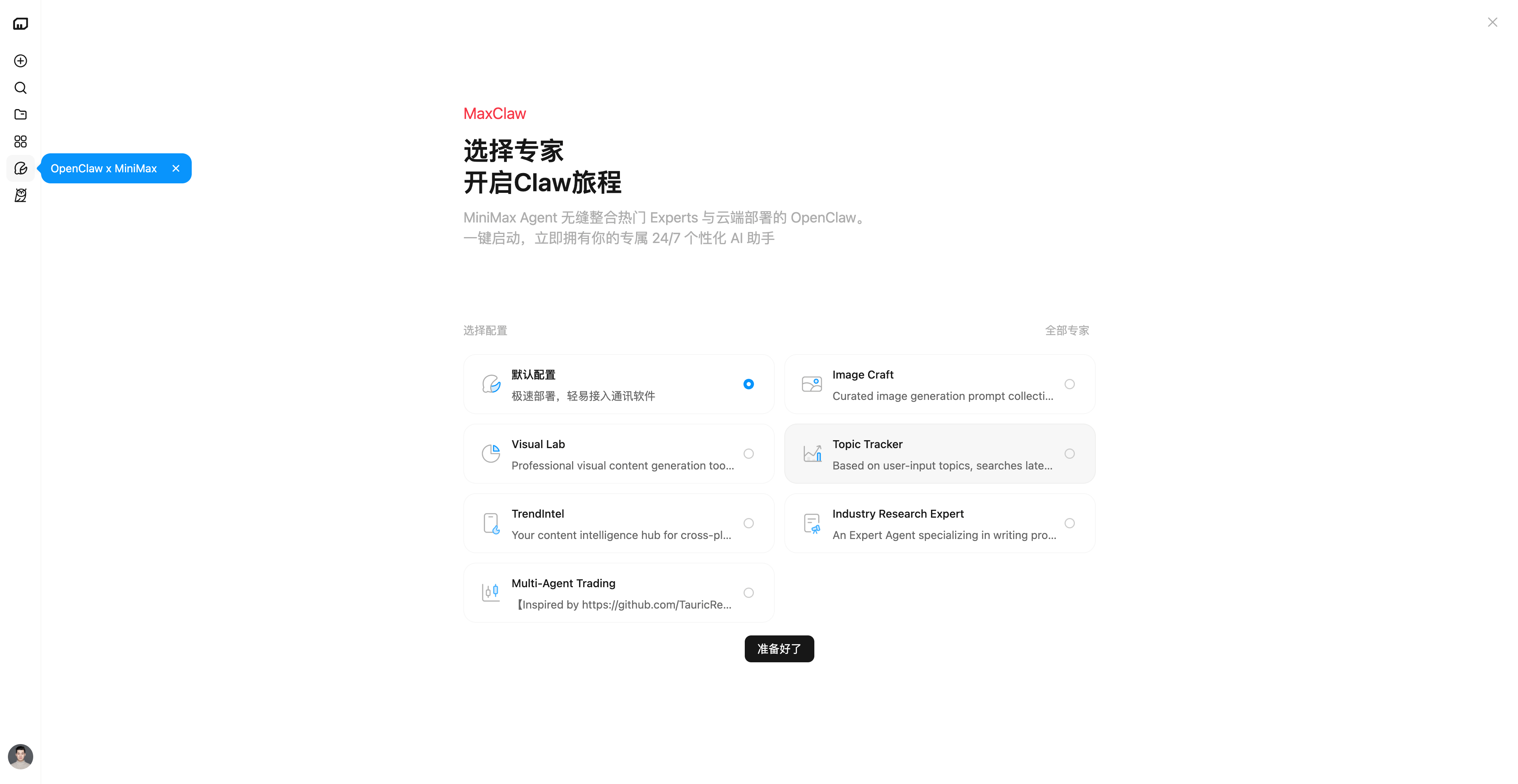
这也是 MaxClaw 对比 OpenClaw 的一大亮点,除了能像 OpenClaw 一样连接到不同的聊天应用,在自己常用的 App 里就能指挥 AI 干活;我们在初始配置时,就可以直接选择那些已经有的预置专家 Agent 配置。
创建之后,在对话框里发送消息,「我想连接到飞书」,按照 MaxClaw 回复的消息,我们点击飞书开放平台的链接,登录之后,按照流程,创建一个企业自建应用,获取 App ID 和 App Secret。接着把复制的信息发送给 MaxClaw,它会提示重启,重启之后在飞书的配置事件订阅里选择添加对应的事件就能启用。

不出所料,整个过程肯定会有一些问题。例如我们在拿公司飞书账号测试时,就被提示相关的授权需要审核才能发布,以及在权限管理和事件配置部分,飞书里面的内容太多太杂乱,根本不知道授予哪些权限。
这个时候,直接回到 MaxClaw,把遇到的问题统统发给它,跟着它的提示走,基本上都能解决。
顺利部署之后,我们在自己的飞书里,就能看到一个对应名字的机器人,然后直接开启对话,所有的对话也会同步在 MiniMax Agent 网页里的 MaxClaw 显示。
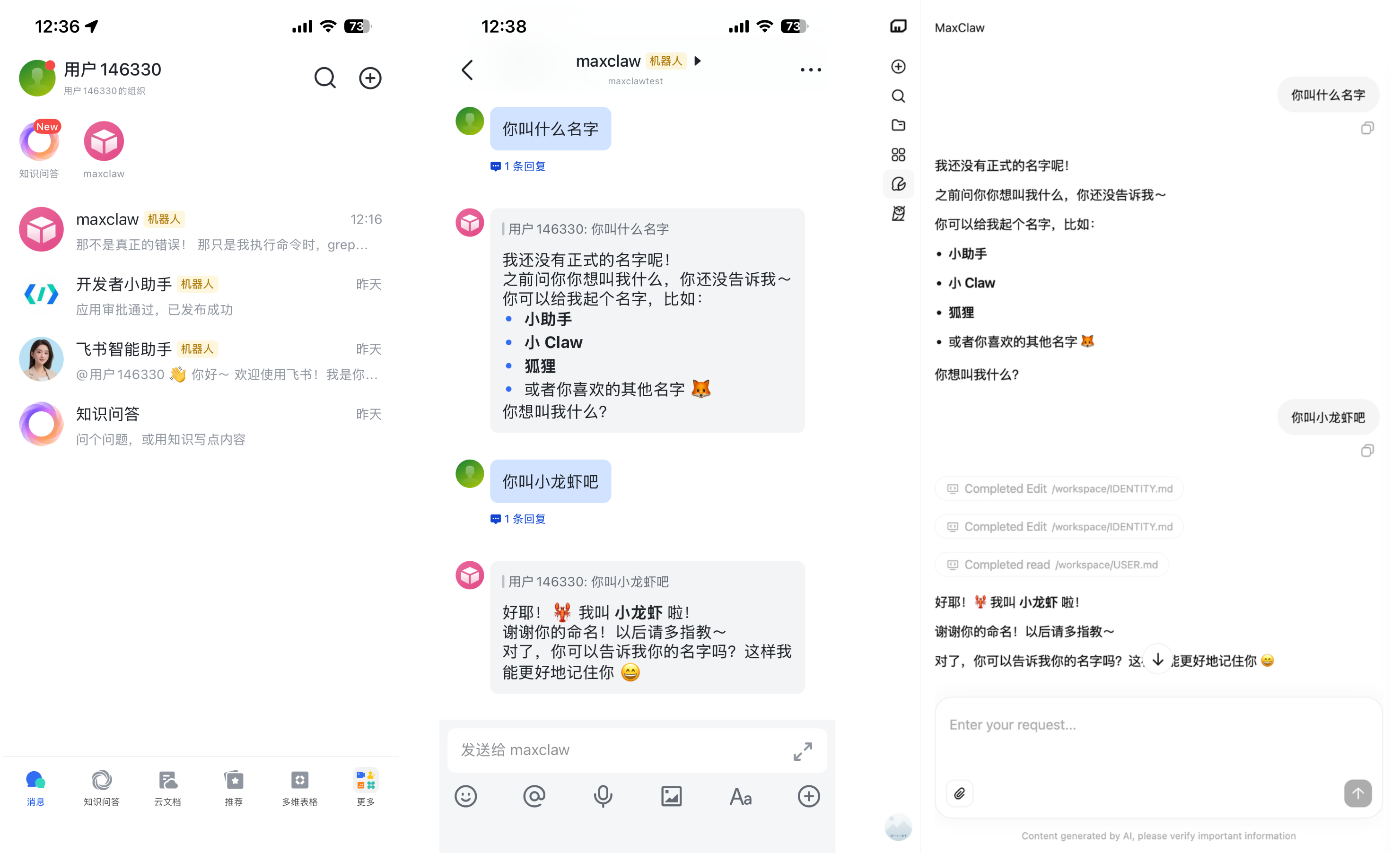
▲现在,飞书就能指挥你的 MaxClaw
让 MaxClaw 帮我们干活,都只用在飞书里面指挥它。我们直接把之前创建的「热点追踪」专家的指令发给它,然后在飞书里对话,输入一句简单指令,「帮我整理今天的快讯」。
很快,一份结构完整的 AI 早报就直接回到了飞书对话框里,完全按照要求的格式,摘要、关键信息提炼、标题等全部都有。并且还能设置定时任务,让 MaxClaw 在飞书里主动给我们发送消息。

除了热点追踪,之前的股票价值分析等专家,我们现在也可以直接通过飞书聊天的方式,就让 MaxClaw 为我们总结出一份逻辑清晰的完整报告。同时,继续让它为我们监控英伟达最新的动态。
而如果直接在配置的时候,选择对应的专家,我们可以看到它的 Skills 情况,MaxClaw 会自动添加开箱即用的 Skills 来帮助我们更好的上手。

▲在效率工具里面有「博客监控」和「内容摘要」等 Skills 用于「热点追踪」专家
时间一到,MaxClaw 在飞书里,准时给我们推送了最新的资讯。
这次更新,真正值得关注的,其实不是又多了一个 Agent 工具。
OpenClaw 的爆火,让我们看到了一个能真正干活的「Agent」是什么样。它是个性化的,部署在自己的电脑上,告别了过去一个网页解决所有用户问题的统一;它是互联互通的,打穿了终端设备上不同应用的壁垒,在 Telegram 也能指挥 AI 帮助我们回复工作邮件……

▲知名博主 Simon Willison 提到 Claw 似乎正在成为像 Agent 一样的专用术语,用来描述一种新的智能体类别|图片来源:https://simonwillison.net/2026/Feb/21/
这本质上是在提醒我们一件事:AI 正在从「辅助回答问题」,走向「直接进入工作流」。当 AI 开始能够调用工具、跨应用执行任务、甚至在后台持续运转,我们原有的工作组织方式,本身就已经在发生变化。
问题只在于,大多数普通用户其实卡在门外。
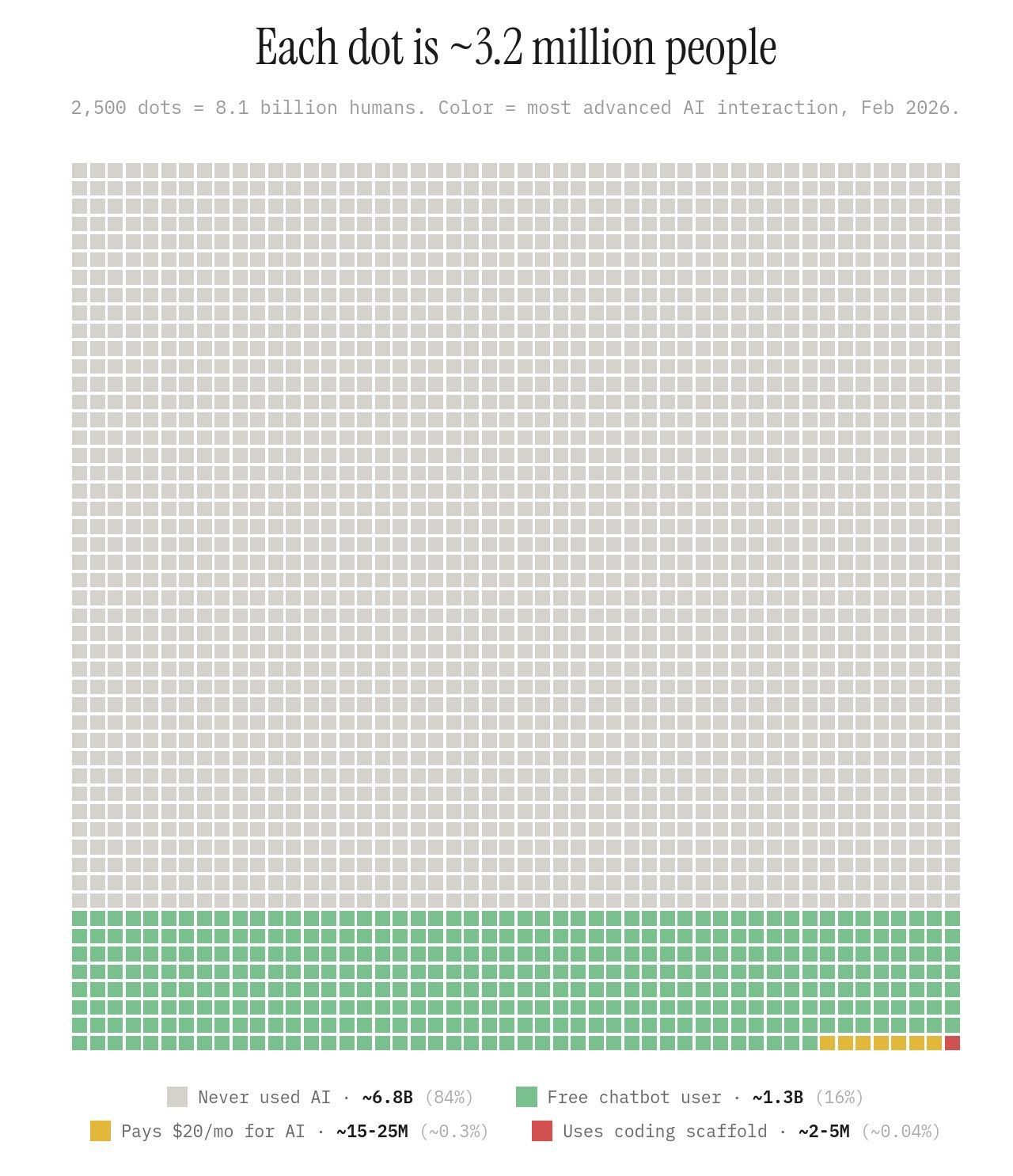
▲全球 81 亿人中, 84% 的人从未用过 AI,而只有 0.3% 的用户愿意为 AI 付费|图片来源:https://global-ai-adoption.netlify.app/
一边是大家都知道 Agent 很强、OpenClaw 很火;另一边,是复杂的部署流程、看不懂的 API 配置,以及随时可能失控的调用成本。很多人不是不想用,而是很难真正用起来。
MiniMax Agent 这次做的事情,某种程度上就是在把这道门槛往下搬,让普通打工人也能轻松搭建自己的顶级 AI 工作流。
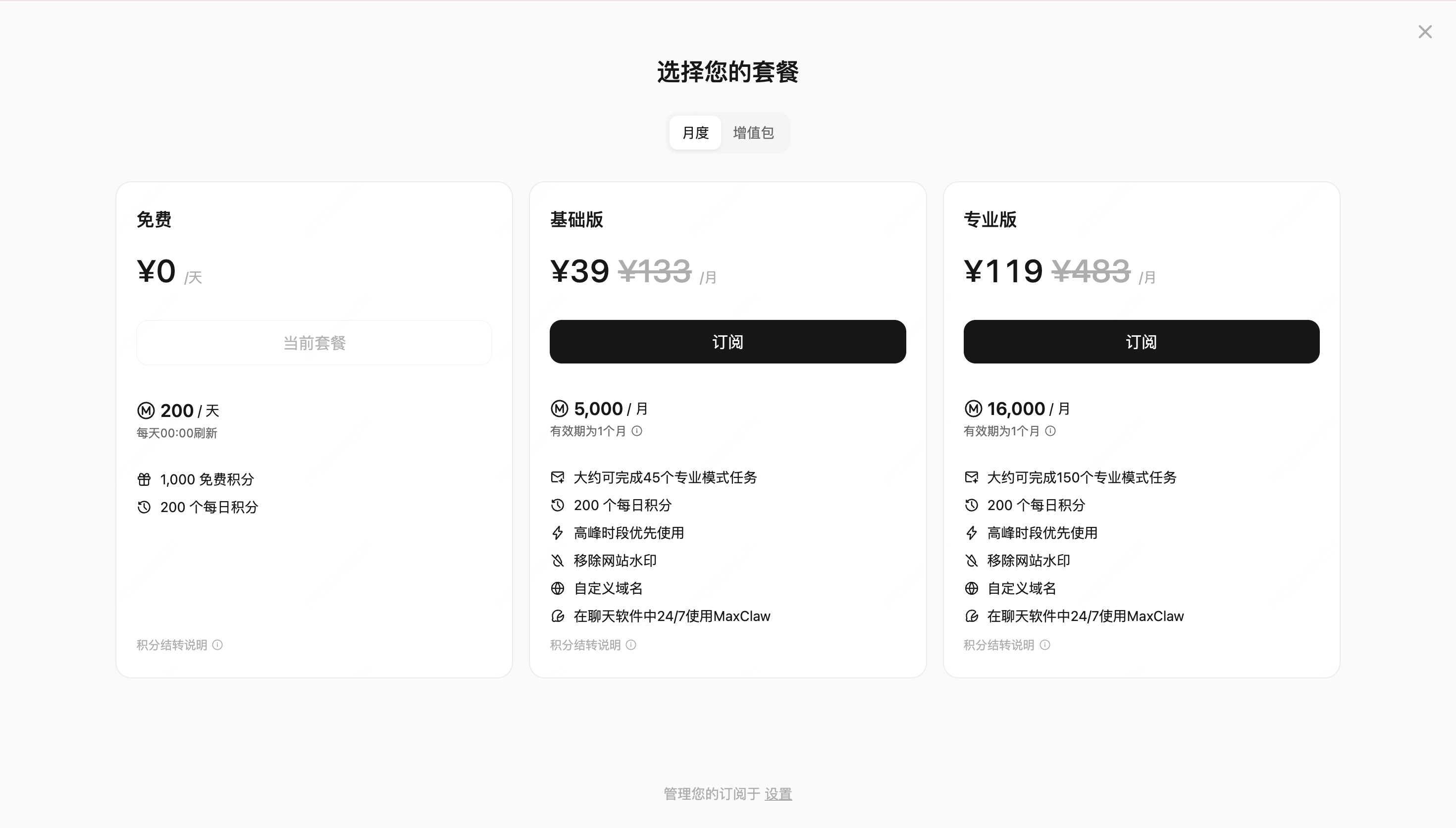
▲MiniMax Agent 会员定价|对比大部分 AI 动辄 20 美元一个月的订阅费用,MiniMax Agent 39 元的价格,大约一杯咖啡的钱,却已经足够能帮我们把写稿、做 PPT、跑多 Agent 工作流一口气打通,让这只「龙虾」多线程干活
Expert 把过去需要反复调 Prompt、反复试错的专业流程,打包成了即开即用的专家社区;MaxClaw 则把原本偏极客向的 OpenClaw 生态,压缩成了一键可用的连接能力。
对于普通用户来说,这种变化的意义很直接,我们不用懂什么是终端,不用让自己费尽力气做个半吊子「工程师」,也能开始搭建自己的 AI 工作流。
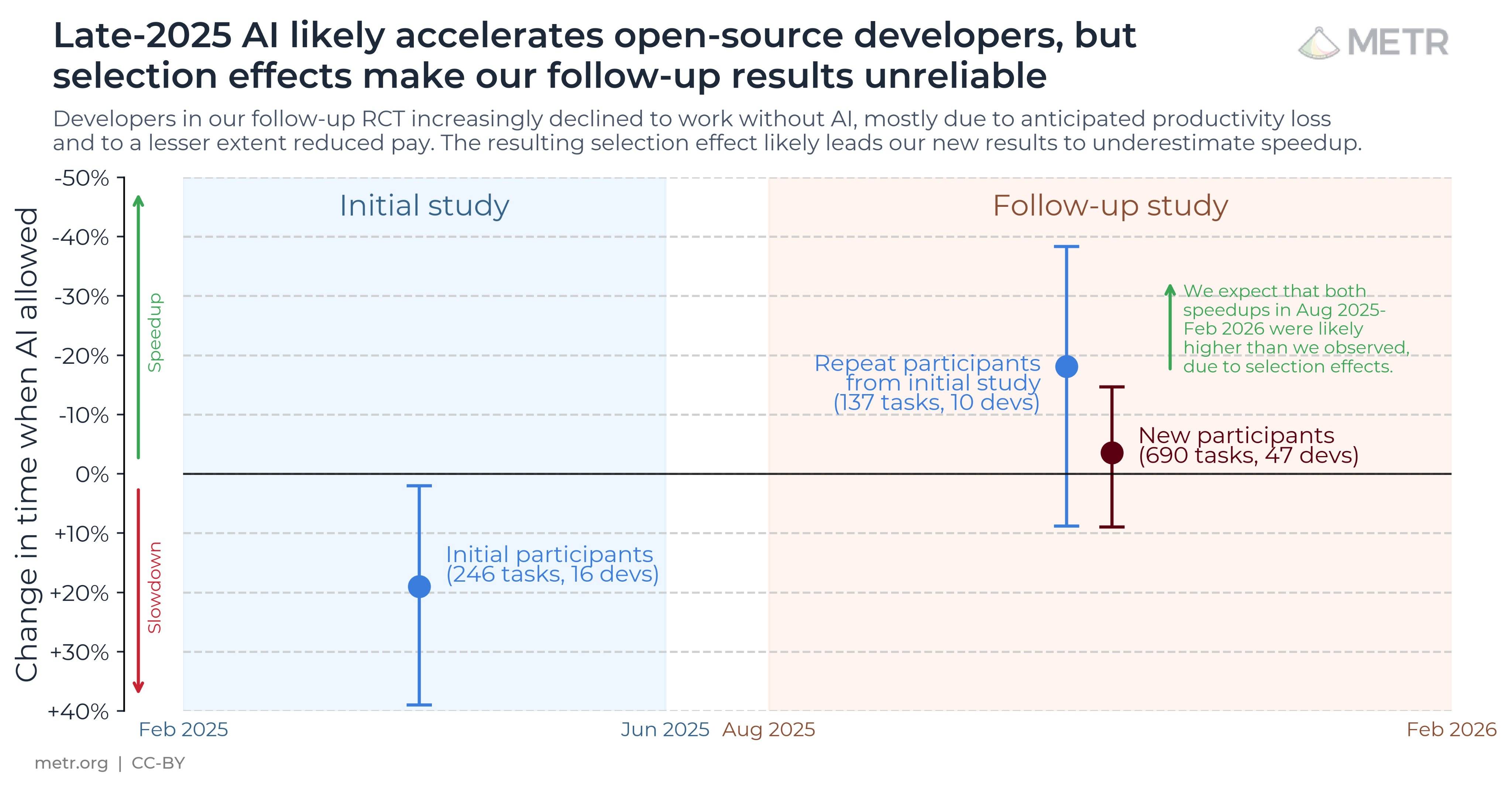
▲METR 此前的研究显示 AI 工具对开发人员生产力的影响,导致生产力下降了 20%;但 METR 表示现在这一发现已经过时,生产力提升似乎更有可能|图片来源:https://x.com/METR_Evals/status/2026355544668385373/
当越来越多「Agent」能够被像软件一样使用,AI 对工作方式的影响,才会真正开始外溢。
从这个角度看,MiniMax 推出这些产品,价值或许不只在于功能多了两个按钮,更在于它正在把一套原本属于少数人的先进工作范式,逐步变成更多人可以上手的日常工具。
对普通用户来说,这或许才是 Agent 真正开始变得有用的时刻。
#欢迎关注爱范儿官方微信公众号:爱范儿(微信号:ifanr),更多精彩内容第一时间为您奉上。

今年英伟达 GTC 主题演讲,应该是史上悬念最少的一届。
2022 年说元宇宙,2023-2024 年说生成式 AI,2025 年说物理 AI。但今年不一样,即便台上英伟达创始人黄仁勋的演讲还没有开始,但台下所有人已经知道答案了——Agent。

包括英伟达也悄悄在 GTC 园区里开设了「Build-a-Claw」互动专区,让与会者现场搭建自己的AI Agent。 从芯片到模型,从英伟达版龙虾到数据中心,今年主题演讲的潜台词只有一句话:
一切都要为 Agent 让路。
如果说 Hopper 架构开启了生成式 AI(Generative AI)的时代,让机器学会了「说话」;那么 Vera Rubin 的使命,就是开启智能体(Agentic AI)时代,让机器学会「干活」。

 6 交换机、NVIDIA ConnectX-9 超级网卡、NVIDIA BlueField-4 DPU 和 NVIDIA Spectrum-6 以太网交换机,以及新集成的 NVIDIA Groq 3 LPU
6 交换机、NVIDIA ConnectX-9 超级网卡、NVIDIA BlueField-4 DPU 和 NVIDIA Spectrum-6 以太网交换机,以及新集成的 NVIDIA Groq 3 LPU过去的 AI 像是一个极其聪明的图书馆管理员,我们问一个问题,它慢条斯理地翻书,然后把答案整理出来。我们对这种速度是宽容的,因为我们自己打字看书也慢。
但 Agent 完全不同。它不仅要用大模型思考,还要疯狂地调用工具——比如打开浏览器、控制云端的虚拟 PC、在无数个数据库里来回比对。更要命的是,AI 对工具的容忍度极低,它要求一切操作都在毫秒级完成。
「它会狠狠地捶打内存。」黄仁勋在台上这样形容。

当模型越来越大,上下文长度从十万 Token 飙升到数百万,还要同时处理结构化和非结构化的数据,传统的算力架构开始喘不过气了。为了应对这种「捶打」,英伟达交出了第一份答卷,全新的 Vera CPU。
这颗芯片特立独行,它是世界上首款专为智能体 AI 和强化学习时代打造的处理器,其效率是传统机架式 CPU 的两倍,速度提升 50%,采用 LPDDR5X 内存,能实现极高的单线程性能、大型的数据吞吐量和极致的能效。
黄仁勋甚至毫不掩饰他的骄傲:「我们从没想过会单独卖 CPU,但现在,这绝对是一个价值数十亿美元的业务。」

紧随其后的是 Rubin GPU,单片芯片直接塞进了高达 288 GB 的海量内存。它就像是一个拥有无限脑容量的思考者,专门用来装载那些体积越来越庞大的超大语言模型,以及处理成百上千万的上下文 KV 缓存。
除了堆叠 CPU 和 GPU,英伟达这次发布的 Vera Rubin 架构,直接把 NVLink 的带宽翻了一倍——260 TB/s 的全互联带宽。
十年前,DGX-1 用第一代 NVLink 把 8 张卡连在一起,那是专为 AI 研究员打造的奇迹;到了 Hopper 时代,是 NVLink 4;而前不久的 Blackwell 架构,用 NVLink 72 实现了 72 张 GPU 的全互联,带宽达到 130 TB/s。
为了配合 Vera Rubin,黄仁勋甚至掏出了被称为 Kyber 的全新机架。在这个机架里,计算节点垂直插入,背后是第六代 NVLink 交换机。完全抛弃了传统的以太网或 InfiniBand 限制,在一个 NVLink 域内直接打通 144 张 GPU。

即便强如 Vera Rubin,在面对「无限生成 Token」的极端需求时,也会感到吃力。
在算力世界里,吞吐量(Throughput,同时处理巨量任务的能力)和延迟(Latency,单次任务的极速响应)是一对物理学上的死敌。英伟达是吞吐量的绝对霸主,但在极致低延迟的 Token 生成上,传统 GPU 架构显得过于笨重。

这时候,Groq 出场了。英伟达早在之前就「收购」并授权了 Groq 团队的技术,在今天正式推出了 Groq LPU(语言处理单元)。

黄仁勋用一款名为 Dynamo 的软件,把这两者完美捏合,首创了「解耦推理(Disaggregated Inference)」。

结果显示,在最具商业价值的高端推理层级,这种组合让性能直接飙涨了 35 倍,且每兆瓦的吞吐量同样提升了 35 倍。
主题演讲的后半部分,黄仁勋抛出了一个让全场屏息的判断:OpenClaw,将是这个时代的 Linux,是这个时代的 HTML。
OpenClaw 上线仅数周,下载量和影响力已经超过了 Linux 三十年的积累,其本质上是一套智能体操作系统。它能调用大模型、管理文件、拆解任务、协调子智能体,还能发邮件、发短信,以任何模态与人沟通。

在黄仁勋看来,每一家 SaaS 公司,迟早都会变成 AgaaS 公司,也就是「Agent-as-a-Service(智能体即服务)」公司。而每一位 CEO 现在都必须回答同一个问题:你的 OpenClaw 战略是什么?

当然,开源意味着自由,但企业更需要的是安全。这也是 OpenClaw 规模化落地前最大的障碍。

为此,英伟达联合以 OpenClaw 创始人 Peter Steinberger 为代表的团队,召集了一批顶级安全与计算专家,推出 NeMoClaw 参考架构。

它内置 OpenShell 技术、网络防护机制和隐私路由能力,可以让企业可以在自己的私有环境中安全运行智能体系统。

而支撑这套智能体生态的,是英伟达一整条开源模型产品线。
比如 Nemotron 主攻语言推理,Cosmos 聚焦世界建模,Groot 面向通用机器人,Alpha Mayo 服务自动驾驶,BioNeMo 深耕数字生物学,Earth-2 则专注 AI 物理仿真。
黄仁勋特别强调,这些模型不只是排行榜上的名字。英伟达会持续投入推进,Nemotron 3 之后有 Nemotron 4,Cosmos 1 之后有 Cosmos 2,每一代都会更强。

更重要的是,这些模型全部以基础模型形式开放,任何企业都可以在此基础上继续微调和后训练,打造专属于自己业务场景的定制化智能。英伟达还宣布将与各地区合作伙伴协作,帮助不同国家和市场孵化本土化 AI 能力。
在台上,黄仁勋还宣布了一份让人眼前一亮的合作名单。Black Forest Labs、Cursor、LangChain、Mistral、Perplexity、Sarvam,以及 Mira Murati 创立的 Thinking Machines,悉数加入,共同推进 Nemotron 4 的研发。

划重点,英伟达不甘心只做卖铲人,更要亲自下场带头挖金矿,更重要的是,英伟达也是在构建一个生态,一个围绕智能体时代的完整体系。
要理解英伟达今天的恐怖统治力,黄仁勋首先把时钟拨回了 25 年前。
那时候没有 ChatGPT,没有大模型,只有一群为了让游戏画面更流畅而疯狂攒机的年轻人。「GeForce 是英伟达有史以来最伟大的营销活动」,黄仁勋在台上笑着说。
黄仁勋非常直白地承认,GeForce 就是用来吸引未来客户的。他们在我们还买不起企业级产品的时候,通过游戏显卡潜伏进我们的电脑。日复一日,年复一年。

也正是依靠一代代游戏玩家的「供养」,英伟达在 20 年前做出了一个当时看来堪称疯狂、甚至差点拖垮公司利润的决定——研发 CUDA,并将它送到了全世界每一个开发者的桌面上。
这可以说是一个在黑暗中蛰伏的故事。连续 13 代架构,长达 20 年的死磕,英伟达彻底把 CUDA 变成了一个装机量过亿的庞然大物。
这也解释了为什么当深度学习的「宇宙大爆炸」来临时,Alex Krizhevsky 和 Ilya Sutskever 们环顾四周,发现除了英伟达的 GPU,他们别无他选。

Nvidia 不是碰巧站在了风口上,而是花了 20 年时间,自己造了一台造风机。
飞轮一旦转动,就再也停不下来了。因为在这个飞轮里,硬件只是载体,真正黏住开发者的是那成千上万个工具、框架和开源项目。
既然当年是 GeForce 游戏显卡把 AI 算力(CUDA)带给了这个世界,那么十年后的今天,是时候让彻底长大的 AI,反哺它最初的「老家」了。

黄仁勋在台上甩出了惊艳全场的 DLSS 5。简单来说,英伟达正在用 AI 重新发明计算机图形学。传统的 3D 渲染是「结构化数据」,它是死板的、百分百可控的;而生成式 AI 是「概率性计算」,它是天马行空、极其逼真的。
以前这两派路线完全不同,但在 DLSS 5 里,英伟达硬是把它们揉在了一起,用可控的 3D 数据打底,用生成式 AI 去脑补和渲染细节。我们看到的画面,既不会出现 AI 经常犯的幻觉错位,又拥有近乎现实的惊人质感。
「生成出来的世界,变得极其美丽,同时又完全受控。」
但这也不只是一帮极客为了高帧率打游戏搞出来的炫技。黄仁勋说,这种将「结构化数据」与「生成式 AI」融合的逻辑,将会在每一个行业里一遍遍重演。

「这是我最喜欢的一页 PPT」
在演讲的高潮,黄仁勋放出了一张极其复杂的架构图,说这是他最喜欢的一页 PPT。接着,他又半开玩笑地说,团队屡次劝他别放这张图,但他偏要放,「反正你们有些人也是免费进来的,这就是门票钱」。

这张「最不听劝的 PPT」,真正揭示了英伟达接下来要吞噬的真正猎物,全球企业的数据中心。
过去,企业的数据分为两类。
一类是结构化数据,也就是常见的数据库 SQL、Pandas 里的那些庞大表格,它们是商业运转的地基。另一类是非结构化数据,比如海量的 PDF、视频、语音,占据了世界 90% 的信息,却因为难以检索而如同废纸。
过去几十年来,处理这些巨型 Excel 表格一直是 CPU 的绝对领地。当人类去查询这些表格时,CPU 的速度勉强够用。但黄仁勋一针见血地指出了未来的趋势,「未来,使用这些结构化数据库的,将是 AI Agents」。
当成千上万个不知疲倦的 AI Agent,以远超人类百万倍的速度同时向数据库发起查询时,传统的 CPU 计算系统连喘息的机会都没有,只会被瞬间压垮。
为了处理这个问题,英伟达掏出了第一把底层杀器:cuDF。它直接越过 CPU,用 GPU 的恐怖并行算力,把这群数据的处理速度拉爆。

而针对非结构化数据,英伟达掏出了第二把杀器,针对向量数据库和非结构化数据的 cuVS。有了这两个底层库,英伟达实际上是捏住了全球数据处理的咽喉,它正在用 AI 的方式,重新定义企业到底该怎么处理数据。
两个工具库的效果也是相当明显。黄仁勋举了非常多合作伙伴的例子,其中提到雀巢公司每天要处理覆盖 185 个国家的庞大供应链数据,在换上英伟达加速的 IBM Watsonx.data 后,速度飙升了 5 倍,成本却骤降了 83%。

这就是「加速计算」的恐怖之处。当速度实现了几个数量级的跃升,成本就会呈断崖式下跌,新的商业模式就会在此刻涌现。
黄仁勋的演讲进行到这里,满嘴都还是「算法」、「库(Libraries)」和「数据帧」,他直言「英伟达是一家算法公司。」
英伟达将自己的算法库深度嵌入每一家云端,客户为了用 Nvidia 的算力和框架,才会去购买云服务。这也是为什么几乎世界上所有的云服务巨头——Google Cloud、AWS、微软 Azure、Oracle,都得排着队,把英伟达的服务请进自己的机房。

曾经呼风唤雨的云厂商,在加速计算时代,似乎都正悄然沦为英伟达庞大生态的「底层基础设施」和「分销渠道」。
英伟达为什么能做到这一切?黄仁勋给出了一个极度反常识的定义,英伟达是世界上第一家「垂直整合,却又水平开放」的公司。
向下,它自己造芯片、造系统;向上,它懂每一个行业的应用场景。
金融界的量化交易员在用它,医疗行业的医药研发在用它,连电信行业那个只会发射信号的基站,在未来也会变成运行 AI 算法的边缘计算节点。
英伟达甚至还推出了机密计算(Confidential Computing),让极其敏感的企业数据和模型可以在完全隔离的环境下运行,连操作员都看不到。这直接打消了巨头们拥抱 AI 的最后一点顾虑。

它把自己封装成一个个底层算法库,然后像水和电一样,悄无声息地接入了所有人的基础设施;看似把所有的利润都分给了生态伙伴,但实际上,英伟达已经牢牢掌握了整个 AI 时代的命脉。
根据黄仁勋的判断,到 2027 年,全球 AI 基础设施规模至少达到 1 万亿美元,而且这还是保守估计,实际计算需求会远超这个数字。

这个数字从何而来?答案藏在过去一年英伟达做的那件最重要的事里——AI 推理。
黄仁勋直言,很多人觉得推理很容易,但事实恰恰相反。
高难度推理是 AI 领域最难的事,也是最重要的事,因为它直接带来收入的增长。为此,英伟达在 Hopper 架构巅峰期做出大胆决定,彻底改变架构,打造出 NVLink 72,引入 NVFP4 精度格式,配合 Dynamo、TensorRT-LLM 及全套新算法,还专门建造了超级计算机来优化整套技术栈。
英伟达押注的结果,远超所有人的预期。

黄仁勋曾宣称 Grace Blackwell NVLink 72 每瓦性能提升 35 倍,当时没人相信他。后来 SemiAnalysis 发布评测报告,分析师 Dylan Patel 说黄仁勋说得太保守了,实际提升是 50 倍。

▲黄仁勋打趣道「Monkey King」「Token King」。
按摩尔定律,一代产品通常只能带来约 1.5 倍提升,没人预料到这次会是 50 倍。
性能提升之后,摆在面前的是另一个问题。一座 1 吉瓦数据中心,按 15 年摊销,建造成本就高达 400 亿美元,设备还没放进去。在这样的投入规模下,放进工厂里的计算系统必须是全球最好的,否则每一瓦浪费的电力都是真实流失的收入。
黄仁勋坦言,全球 AI 工厂里正有大量电力被白白浪费。
为此,英伟达发布了 NVIDIA DSX 平台,基于 Omniverse 数字孪生技术,让工程师在真正动工之前,先在虚拟空间里把整座 AI 工厂仿真一遍,从散热到电网,全部模拟清楚。
配合 Max-Q 技术,系统可以在功耗与算力之间实时动态调节。

黄仁勋说,这里面至少还藏着两倍的优化空间。同一套硬件,英伟达更新算法与软件后,Fireworks 等服务商的 token 生成速度从每秒 700 个跃升至接近 5000 个,提升 7 倍。这就是「极致协同设计」的真实含义。
过去数据中心存放文件,现在它生产 token。土地、电力、机房空间决定了工厂上限,而架构优劣决定了产出多少。黄仁勋说,未来每一家公司都会认真思考自己 token 工厂的效率问题,因为算力,就是收入本身。
更重要的是,地球上的 AI 工厂还没建完,英伟达已经把目光投向了太空。
英伟达 Thor 芯片已通过抗辐射认证,率先应用于卫星之上。英伟达正与合作伙伴联合研发名为 NVIDIA Space-1 Vera Rubin 的新型计算机,目标是直接在太空中建设数据中心。

太空没有空气,无法对流散热,散热是一道极其棘手的工程难题。黄仁勋坦承这件事非常复杂,但他相信英伟达有足够优秀的工程师来攻克它。从地面到轨道,英伟达算力扩张的路线,仍在持续。
物理 AI 是未来十年最重要的课题,而黄仁勋用一句话宣告,自动驾驶的 ChatGPT 时刻,已经到来。
英伟达 RoboTaxi Ready 平台此次新增四位重量级伙伴:比亚迪、吉利、五十铃、日产,携手打造 L4 级自动驾驶汽车。
这四家车企每年合计生产约 1800 万辆汽车,体量惊人。加上此前已加入的梅赛德斯、丰田和通用,英伟达的自动驾驶版图已覆盖全球最重要的一批整车制造商。

英伟达还与 Uber 签署合作协议,计划将具备 RoboTaxi Ready(无人出租车就绪)能力的车辆部署至多个城市,并直接接入 Uber 的全球出行网络。
在工业机器人领域,英伟达与 ABB、Universal Robots、库卡等头部企业展开合作,将物理 AI 模型集成至仿真系统,推动机器人大规模进入制造产线。卡特彼勒的加入,意味着重型工程机械也开始走向智能化。

主题演讲的最后,依旧是经典的机器人环节。
近期,《冰雪奇缘》的雪宝机器人已经现身迪士尼海外游乐园,而这一次,它也迈着憨态可掬的步伐登上 GTC 2026 的舞台,和黄仁勋有来有往地对话,动作自然,反应流畅。

它的肚子里装着英伟达 Jetson 计算机,这是整套系统的大脑。它的步态和动作,全部在 Omniverse 虚拟环境中完成训练,靠的是由英伟达、迪士尼和 Google DeepMind 三方联合研发的 Newton 物理引擎,运行于英伟达 Warp 之上。
正是这套物理仿真系统,让雪宝在进入真实世界之前,就已经充分适应了现实物理规律。黄仁勋说,未来的迪士尼乐园所有角色都将拥有真正的智能,在园区里自由走动,与每一位游客展开真实的互动。

演讲开始的时候,黄仁勋说,我要提醒你们,这是一个技术大会。我们将要谈论技术,谈论平台,最重要的是,我们要谈论生态系统。
生态系统?他实在太谦虚了,用生态帝国也不为过,黄仁勋曾经用一块五层蛋糕来描述 AI 产业的结构:最底层是能源和芯片,往上是基础设施、模型,最顶层是应用。
每一层都不可或缺。这个比喻听起来像是在描述一个分工清晰、各司其职的产业格局。但当你把这块蛋糕从底看到顶,会发现每一层里都有英伟达的手笔。
从最早「潜伏」在玩家机箱里的显卡,到主宰全球云厂商的底层框架;从太空里的抗辐射数据中心,到迪士尼乐园里和我们谈笑风生的机器玩偶。
英伟达用 20 年时间造了一台造风机,如今这台机器已经化身为一台永不停歇的 Token 生产厂。在这个工厂里,算力即权力,生态即壁垒。
当所有的企业、用户都在为如何落地 AI 焦虑时,黄仁勋已经悄悄把通往 Agent 时代的门票,塞进了世界上每一台服务器的咽喉。
这场关于未来 AI 的赌局,英伟达不仅既做庄家又做玩家,它甚至要把牌桌都买下来了。
作者:张子豪、莫崇宇
#欢迎关注爱范儿官方微信公众号:爱范儿(微信号:ifanr),更多精彩内容第一时间为您奉上。
被 Meta 收購的 AI 新創公司 Manus 持續擴展其 AI Agent 能力。繼雲端 Manus An […]
The post Manus 推出「My Computer」桌面應用:將電腦轉化為個人 AI 智能體,支援遠端操控與自動化開發 appeared first on 電腦王阿達.

2026 年 1 月,OpenClaw 席卷中文互联网。仅仅两个月后,龙虾已经进入了「全民卸载」周期。
龙虾的问题不是它不够强,而是它很难服务于每一个普通人。
从安装到卸载,第一批「养虾人」的故事,暴露了 OpenClaw 的尴尬:Agent 怎么能产生真正的生产力价值?
今天,飞书的新品发布会,想给每个人一个答案。

OpenClaw 爆火之后,有着开放、易用的机器人机制的飞书,也跟着走红了。
API 调用额度从 1 万次提到 5 万次,再到目前的 100 万次;3 月 5 日推出官方插件,让 Agent 可以直接读写飞书文档、日历和多维表格,把「养虾」的门槛从「会写代码」降到「会用飞书」。
这些动作,确实让龙虾更好养了。但 OpenClaw 本身的弊端,飞书仍然解决不了:配置复杂、普通用户上手门槛高、原生部署安全隐患大,等等。
结论是:Agent 要真正落地,必须是一个上手即用的智能伙伴。它的安全是基本线,更要能直接与每个人的工作流丝滑融合。
今天正式升级的 飞书 aily,就是飞书给出的答案。

飞书 aily 是什么?官方定位是「每个人的智能伙伴」。形态上,它以 Bot 的方式常驻在飞书联系人列表里,打开飞书就能找到,对话即交互。30 秒激活,零配置。
可以说,飞书 aily 是 OpenClaw,或者更广泛定义上「龙虾」理念的一种呈现方式。但它又跟开源的原生版 OpenClaw 有着本质的区别:
龙虾是你自己养的宠物,飞书 aily 是公司给你配的同事,入职了,开权限了,准备好和你一起开始工作了。
对于需要处理更复杂工作流的用户,还有独立的飞书 aily 专业版(aily.feishu.cn),有图形界面,可以让有需求的开发者、公司 IT 管理员去构建多步骤的自动化任务。
接下来的实测,我们会聚焦在普通人更好用的 Bot 形态,但两者底层逻辑相同。

把飞书 aily 放进了实际工作流里,我们测了几个最日常的用法。
先来一个极高频的场景:飞书拉会。

在任务过程中,飞书 aily 直接查询了 APPSO 组织架构内的用户 ID——这一步放在别的 AI 工具里根本做不到。它能做这件事,是因为统一的权限机制。你在飞书里能看到的,它就能看到。
确认了人、确认了时间,调用飞书日历技能,一个会议就建好了。
从任务发起,到创建完成,大约半分钟。不敢说比飞书达人手搓更快,至少主打一句话搞定。

让打工人感觉痛苦,但又不得不做的事情,做月报肯定算一个。
我们把自己的社媒平台数据,先上传到了飞书云盘,然后交给飞书 aily。提示词很简单:查找不同媒体平台数据生成多维表格;再跟员工汇报文档结合,生成一份团队月报。

它整理了一共 9 份不同格式的文件,交付了一份月度汇报,以及可以作为附件的多维表格——时间只用了不到 4 分钟。同样的工作,APPSO 去年还在纯手搓,要用至少两个小时。

顺便一提,如果你想从零搭一套数据追踪的业务系统,子产品飞书妙搭也支持用自然语言描述需求,直接生成一套业务系统应用。
不一定每次都用得上,但有飞书 aily 在,你知道自己不用再求人了。
接下来,我们再看一个相对更复杂、偏创作/生成向的任务,看看飞书 aily 作为自媒体搭子好不好用。
作为 APPSO 的深度报道作者,我会写很多晦涩难懂的文章,在社媒平台传播的时候就需要生成有针对性的、更浅显易懂的版本。
我们还是可以直接在飞书 app 里,通过设定好的机器人来发指令。不过,这个任务其实更适合用飞书 aily 的专业版来完成。有图形界面 (GUI) 的辅助,可以精细化输入和调整,还可以更方便地调用原生支持的各种工具、技能和插件。
飞书里直接搜索飞书 aily,或者打开 aily.feishu.cn,就进入到了专业版界面。
它支持用户上传自定义 skill。虽然官方技能库非常丰富,但我还是想上传一个我之前经常用的「content-creator」(内容创作者)技能。

装完 skill 之后,我们只需要在对话框里输入 /content-creator(具体的 skill 命令因人而异),就能唤醒它。再把文件链接给到,它就能开始帮我写稿去了。
这种技能/插件的调用方式,和 Claude Code、Cowork、OpenClaw 等产品相同,熟悉度拉满。

开始工作后,我们能够在后台看到,飞书 aily 先是做了一个 plan,将任务分解成 5 个步骤。

即便是不指名到具体的 skill 上,飞书 aily 仍然可以判断我的意图然后调用对应的技能来完成工作。
APPSO 在这里其实还做了 A/B 测试,激活或不激活技能,任务完成时间分别是一分半和三分钟——都不算特别久,但显然调用 skill 工作更快,而且利用技能写出来的感觉更好。
无论是各种官方还是第三方的 skill,飞书 aily 都能完美适配。不过这里 APPSO 还是建议大家不要在不熟悉的情况下乱装 skill,尽量以官方的技能商城为准。

工作完成后,点击右上角的工作区,能够查看生成的内容了。


三个场景测下来,有一个感受越来越清晰:飞书 aily 跟那些「AI 生成一个文件发给你」的工具,体验差异还是很明显的。它的交付物是文档、表格、任务,可以继续被协作、被引用、被追踪。
龙虾当初让大家兴奋的那个期待,其实一直都很具体:帮我做完一件费时、费力的小事,让我能腾出脑子去处理真正重要的东西,别让心流被一堆琐碎打断。飞书 aily 做到了这一点,龙虾没有。
当然,OpenClaw 有很多「出格」的操作,它还做不到:操控本地文件系统、执行任意命令等。但换一个角度,这种「克制」本身就是企业场景的必要条件。哪怕一个新实习生学历再高、能力再强、多有灵气,公司不会给 ta 配上服务器根权限——这很正常。
飞书本就是个强有力的生产力工具。飞书来做龙虾/agent,当然不是为了实现什么 AGI。在各种宏大的叙事之外,先让普通人的打工人生更轻松,才是更重要的。

飞书 aily 支持定时任务创建,交互比 OpenClaw 更轻松
企业 Agent 的竞争,正在往一个很多人还没意识到的维度转移。
过去两年,行业的注意力主要在两件事上:模型能力(谁的参数更大、基准跑分更高),以及 C 端爆发(谁的 Agent 更酷、更会演示)。
OpenClaw 的火爆是这个逻辑的顶点——一个开源框架,凭借「能干活」的形象引爆全民。
但龙虾从爆火,到卸载,仅用了两个月就快走完了一个周期,里面有一个不能更朴素、更明显的道理:
「能干活」是必要条件,绝非充分条件。
Agent 要在企业环境里真正落地,需要的远不止一个会执行命令的 AI——它需要懂业务,需要匹配组织的权限构架,需要嵌入团队已有的工作流,而不是在旁边开一个新窗口,重新训练一个昂贵且笨的「实习生」。

诚然,中国绝大部分的工作发生在微信上——团队工作的本质是沟通,这个道理上过班的人基本都明白。但飞书、钉钉、企微的流行,从侧面证明了工作绝不仅仅是沟通那么简单。
聪明人在一起工作,沟通早已不是问题。聪明人开始发现,那些聪明人也不得不干的「笨事情」,才是效率提升的真正空间所在。
Agent 的上限,取决于它能「读懂」多少你的工作。但在工作的语境下,「读懂」并不意味着你要把自己的电脑交给它。
而读懂,靠的是上下文——你留下过的笔记,开过的会和会议纪要,跟谁在群里讨论过什么,哪些项目在推进,哪些决策已经做出。
这些东西,叫做企业上下文数据,其实正是一个商业机构运转的引擎。它不存在于模型里,也不能从网上抓取,它在企业内部的协作平台上,以消息、文档、日历、审批的形式慢慢沉淀,日积月累。

飞书沉淀这些东西,已经好几年了。
OpenClaw 爆火后,中文开发者自发聚集到飞书,原因很简单——Bot 创建不需要审批,不需要公网 IP,摩擦最少。社区发起人杨明锋在自己的分支里先实现了飞书扩展,2 月 4 日被官方合并。
把 OpenClaw 的门槛从「会写代码」降到「会用飞书」,是飞书能做的事,也是其他平台很难复制的动作。

飞书目前是 OpenClaw 官方唯一原生支持的中国 IM 软件
飞书大概率没有预料到这一切,但它一直在做的那套东西——足够开放、接口通畅、数据互通——恰好就是龙虾最需要的基础设施。
当在飞书中激活飞书 aily ,它读到的上下文,远比文档里的文字、表格里的数据更多。它知道这份文档是上周评审会讨论的结果,知道那个多维表格由哪个团队维护,知道@你的消息通常意味着什么优先级。
——这些,都是外部的 Agent 产品,难以复制的东西。你可以在后端接入强大的模型,可以用各种服务框架、插件、技能、hook 来强化体验。但你的工作记录,专属于你的公司、属于你的上下文,是不可被替换、很难被简单搬运走的。
竞争对手可以做出一个功能相近的 Agent,但它接入的只是空壳;而飞书 aily 面前的,是一个已经蓄满水的池塘。
这个逻辑延伸出去,还有一个更大的判断:企业 Agent 的竞争格局,最终将由「谁的地盘里的上下文最充裕」,而不是「谁的模型最强」来决定。
模型能力不是不重要,但模型的高度商品化,是既成事实;多年沉淀的上下文生态,才成了真正的护城河。
企业 Agent 时代的入口,应该是上下文最深的平台。飞书已经成为了这个入口。
钉钉有更大的用户基数,腾讯有 QQ 和微信的社交图谱,企业微信有腾讯的 B 端关系链。飞书的优势,在这三者里反而是最「纵深」的:它的用户群以科技、互联网和成长型企业为主,这批人对 AI 的接受度高,工作上下文的数字化程度也最高。
换句话说,飞书的地盘虽然不是最大的,但上下文密度可能是最高的。你在哪个平台留下了最多的工作痕迹,那个平台的 Agent 就最懂你。
究其根本,大多数人们对于龙虾的期待,并不能通过 OpenClaw 来解决。
两年后的办公 AI,会变成什么样子,没人知道。但至少今天的答案,就在工作已经在发生的地方,在飞书 aily 的身上。
飞书一直是对 agent 最友好的工作台,无论 AI 怎么进化,其实万变不离其宗。
#欢迎关注爱范儿官方微信公众号:爱范儿(微信号:ifanr),更多精彩内容第一时间为您奉上。

龙虾爆火之后,全网的注意力都盯着「它该怎么用」——本地部署还是云端、一键安装还是敲命令、要不要接微信飞书……反而没人再认真问那个老问题:驱动龙虾的那颗「大脑」,够不够聪明?
这倒不奇怪。OpenAI 和 Google 最近发布的几款新模型,清一色都是 Mini、Flash 款,官方潜台词几乎写在脸上:专门给 Agent 大量消耗 Token 准备的。
模型本身的能力边界,反而成了最不被讨论的话题。

一个真正适配龙虾的模型,除了 Token 要量大管饱还实惠,更多的是模型要足够聪明、动手能力和学习能力足够强。
最近,MiniMax 正式推出了全新的 MiniMax M2.7 模型,主打「开启 AI 的自我进化」和做「最强的 Cowork Agent 模型」,既能处理代码工作、常见的 Office 任务,还能主动学习构建稳定的 Agent 系统。

具体来说,它能做好的工作比大多数模型要更宽。对于写代码,M2.7 能真正理解一个系统在运行时发生了什么,做到了 SRE(网站可靠性工程)级别的系统推理,看日志、关联时间线、推断根因、给出有优先级的处理方案。新模型在 SWE-Pro 上跑了 56.2%,几乎追平 Opus 4.6。
办公场景里它已经够用了。 Excel、Word、PPT 的复杂编辑和多轮修改,M2.7 在这块有明显提升,金融分析这类需要专业知识 + 格式交付的场景尤其明显。不能说它可以完全替代专业人士,但是真正进入工作流,作为辅助完全可以。
它在多 Agent 协作里不会「断掉」。 这是 M2.7 专项打磨的能力,多角色场景下边界清晰,面对包含 50+ Skills 的复杂环境,依然能保持极高的指令遵循能力。
然后是这次更新的重点,它开始参与优化自己了。 MiniMax 说 M2.7 是他们第一个深度参与迭代自己的模型,不只是「辅助迭代」,是「深度参与迭代自己」。能够自我进化,M2.7 可以自主迭代 Agent Harness(智能体脚手架)来胜任大部分的工作流。
实战能力的提升,也让 MiniMax M2.7 一发布就在龙虾榜上迅速攀升,来到了最高分排行榜的第四名。

▲PinchBench 排行榜是为 OpenClaw 量身定做的模型评估基准,它测试的是大模型在 OpenClaw 真实业务场景下的表现,图中为任务成功率指标,MiniMax M2.7 排名第四,在 Claude Opus 4.6 之后|https://pinchbench.com/
我们也在 Claude Code、本地部署的龙虾里,都接入了 MiniMax M2.7 模型,以及 MiniMax 提供的 MaxClaw,然后把真实的开发过程中遇到的 Bug、枯燥的金融数据,还有大量的长流程任务统统交给它。
两天的测试下来,我们发现不仅软件要为了 AI 重做,就连 AI 模型本身,除了要理解人类的用意和产出人类满意的结果,模型更需要懂得 AI 的工作方式和工作流,还得学会自己优化自己。
在 OpenClaw 等 Agent 框架爆火后,真正的「AI 时代工作流」应该是,AI 作为核心运转枢纽,去调用几十个工具、去指挥其他 AI 队友、甚至去优化 AI 自己的代码。
在测试 MiniMax M2.7 是如何自我进化之前,我想先看看它的 AI 工作流如何。它到底是不是一个好用的 Agent 模型,还是说拿去跑个 benchmark 好看,实际用起来一言难尽。
我们从知名的机器学习挑战赛 Kaggle 的网站上下载了一份股票的历史数据,然后按照比赛的要求,告诉 MiniMax M2.7 帮我实现对应的需求,即根据给定的数据,进行合适的数据处理和特征工程,为我生成一份可视化的分析报告。
整个数据集的内容相当庞大,有超过 3000 行的表格数据,整体文件大小来到 446.35 MB。把 5 个表格数据文件下载到本地之后,我们使用接入了 MiniMax M2.7 的 Claude Code 来完成这项工作。

要做好这份分析,需要模型是个数据分析师完成数据清洗和整理、宏观分析师完成对应的金融市场的洞察、统计分析师完成初步的数学建模、算法工程师要建立对应的模型,最后还有网页工程师要交出一个可视化的方案。
面对这样一个复杂的任务,MiniMax M2.7 充分利用了我已经安装的各种 Skills,它先使用 Anthropic 官方提供的 xlsx 完成了表格数据结构的信息读取,接着开始编写 Python 代码,自动安装 Pandas 库(常用来处理表格数据),一步一步进行。

最后,MiniMax M2.7 也交出了一份完整的可视化方案,它同时生成了多张图片用来展示收益率分布,不同特征的重要性和类别排名,以及综合仪表盘。

而在可视化的网页里,它利用 Streamlit 库将数据脚本直接转成了可交互的网页系统,所有的信息都可以直接动态查看。

这种大型的项目任务,MiniMax 能够顺利完成,我们日常工作中的办公和编程任务,就更不用说了。
我们先是在手机上操作龙虾,让它帮我总结我放在电脑上的文件,然后要求 MiniMax M2.7 根据这份文件,帮我写一个研究计划 Word 文件,再整理一份相关论文的 Excel 文档,最后是一个用来组会做汇报的 PPT 文档,直接在手机上就能操作。

▲接入 MiniMax M2.7 的龙虾能快速回应需求
▲Office 三件套的处理如今是不在话下
在办公领域的优势,也让 MiniMax M2.7 在衡量专业知识与任务交付能力的 GDPval-AA 评测中,ELO 得分达到了 1495,国产模型最高。
前段时间,AI 工作助手的可视化面板很火,把龙虾放到了真实的二次元风格办公室里,用一句话就能安装到自己的 OpenClaw。我们也成功让这只 Appso 小龙虾有了自己的家,但是如果我想要修改二次元房间布局,可以怎么做呢?交给 MiniMax。

在 OpenClaw 的可视化本地界面里,我们直接发送「我想修改这个小房子的风格该怎么做?」,MiniMax M2.7 会自动阅读项目的代码,然后告诉我们哪些地方是可以修改的,如何修改。

由于我输入的要求是科技编辑部办公室的风格,然后它就帮我修改成了有星球大战的海报,还加了十几个人坐在电脑前面码字。
不过我们没有在 OpenClaw 内配置 Nano Banana Pro 的 API Key,所以 MiniMax M2.7 在 OpenClaw 里帮我选择了用代码的方式来生成简单的图片。

接着和它聊天,我们还能根据这个风格设计一个编辑部大亨的游戏,谁做的任务多,谁的办公室就大,就能升级。

如果是 MiniMax 官方的 MaxClaw,是直接支持多模态的生成,可以一步到位生成视频、音频、图片等,不需要配置额外的 API。
我们使用官方提供的 gif-sticker-maker Skill 生成了几张马斯克的表情包。云端部署的 MaxClaw 能确保运行环境的足够安全,但是它不允许我们像操作本地电脑一样,任意安装不同的库文件。
最后在将视频转成 GIF 时,MaxClaw 提醒我,它没有足够的权限将 ffmpeg(一个开源的多媒体处理库)安装到云端服务器上。

▲在 MaxClaw 内可以直接使用 MiniMax M2.7,它会自动调用海螺等视频、音频和图片生成模型,为我们生成多媒体文件,而不需要额外配置专门的 API KEY。
点击 MaxClaw 对话框下面的技能,我们就能看到所有安装在 MaxClaw 的 Skills 详情,并且点击「问问 MaxClaw」,它会自动编辑一条消息「告诉我 frontend-dev 能做什么,并告诉我如何使用它」,引导我们学习如何使用这项 Skill。

除了 GIF 生成这个 Skill,MiniMax 还提供了包括前端开发、全栈后端、安卓和 iOS 应用开发以及创作惊艳视觉效果的 GLSL 着色技术等技能库,我们可以直接在龙虾里发送「你能帮我安装这个项目里的 Skill 吗 https://github.com/MiniMax-AI/skills」,龙虾会自动获取 Skill 文档完成安装。

▲下载链接:https://github.com/MiniMax-AI/skills
除了在日常工作和办公领域上表现出的完整工作流,以及实际的交付能力,MiniMax M2.7 最让我们感到特别的,还有它展现出的「模型自迭代闭环」。
MiniMax 曾提到人类研究员只需要把控大方向,把构建系统的任务交给模型,它就能以解决方案架构师的身份自主搭建开发 Agent harness。
Agent harness 可以理解成套在 AI agent 外面的一层运行基础设施。模型负责思考,harness 负责把这个「会想」的东西,变成一个能稳定干活的系统。这个系统像是运行层,负责让 agent 在真实环境里稳定运行。

为了测试 M2.7 的极限,MiniMax 让它去优化某个内部脚手架的软件工程表现。结果,M2.7 全程零人工干预,硬生生跑出了一个超过 100 轮的迭代循环。
它自己分析失败轨迹,自己规划改动,改完脚手架代码再去跑评测,最后对比结果决定是保留还是回退。在不停歇自我互搏中,它自己发现了最优解,最终让评测集上的效果飙升了 30%。
这种「AI 搞科研」的能力也在公开的测试集上得到了验证,MiniMax M2.7 被扔进了全球最大的机器学习竞赛 Kaggle 的 MLE Lite 测试集。

22 道高难度竞赛题,M2.7 依靠内部的短时记忆文件和自反馈机制,每跑完一轮就给自己提优化建议。
24 小时内,它一举拿下了 9 枚金牌、5 枚银牌、1 枚铜牌,得牌率 66.6%。
这个成绩,仅次于 Opus-4.6(75.7%)和 GPT-5.4(71.2%),与 Gemini-3.1 直接打平。
当一个模型能够以解决方案架构师的身份,仅用 1 人 4 天时间,零人工编码就搭出一套包含测试和代码审查的 Agent 系统时,AI 研发的齿轮,大概已经换上了自动挡。
在极其硬核的生产力之外,MiniMax M2.7 的底层框架也赋予了它长程稳定的记忆和极强的情商,这让它在互动角色扮演(Roleplay)上,比传统的闲聊机器人表现要好上不少。
官方在 GitHub 上开源了一个多模态交互系统 OpenRoom,一个万物皆可互动的 Web GUI 空间,可以实时地让 AI 与空间产生不同的交互。
体验下来,MiniMax M2.7 真正让我们在意的,不是它把 Kaggle 竞赛刷出了 66.6% 的得牌率,也不是 Office 三件套交付得足够干净。
而是它在试图解决一件更底层的事:让 AI 真正理解工作流,并且参与到工作流的演化里。
过去,软件是人写的、人用的。现在,AI 开始写软件、改软件、用软件。当一个模型能够在没有人工编码的情况下,自己搭系统、自己测试、自己回退——「AI 研发」这件事的齿轮,某种程度上已经换上了自动挡。
所谓「龙虾到底该怎么用」,我想很快就不再是一个问题——因为决定这一切的,不再是我们。
而是那个,开始学会自己工作的 AI。
#欢迎关注爱范儿官方微信公众号:爱范儿(微信号:ifanr),更多精彩内容第一时间为您奉上。
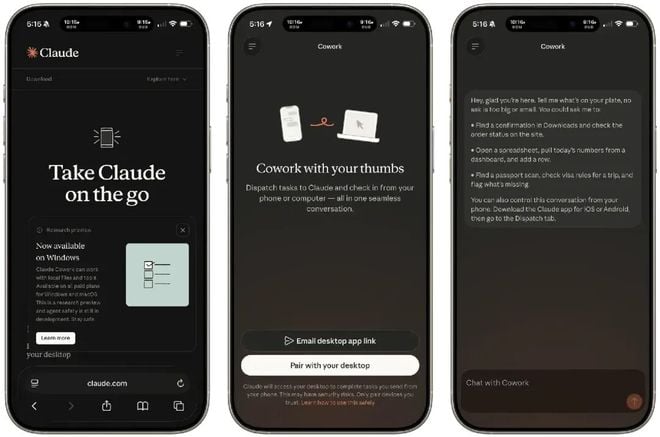
Anthropic 推出「Dispatch」功能,用戶可透過手機遠端指揮 Mac 上的 Claude 自動執行桌面任務,採本地優先架構保護隱私,但目前綜合成功率僅 50%。
AI新創Anthropic日前悄悄在X平台上宣布一項名為「Dispatch」的新功能,讓使用者能直接拿起手機,用一句話遠端指揮家中或辦公室那台處於喚醒狀態的Mac,讓裡面的Claude替你自動執行各種桌面任務。
打破螢幕限制,一句話喚醒遠端AI勞動力
想像一個情境:你正擠在通勤的捷運上,突然想起昨天的會議紀錄還沒整理。這時,你只需拿出手機,對著Claude App說:「幫我把昨天的會議錄音要點整理到Notion裡」。幾分鐘後,Claude就會回報任務完成。
We’re shipping a new feature in Claude Cowork as a research preview that I’m excited about: Dispatch!
One persistent conversation with Claude that runs on your computer. Message it from your phone. Come back to finished work.
To try it out, download Claude Desktop, then pair… pic.twitter.com/r6OH46Ll89
— Felix Rieseberg (@felixrieseberg) March 17, 2026
這並非科幻電影,而是Dispatch正在實現的場景。
Dispatch的核心概念與傳統的「遠端桌面」 (Remote Desktop)截然不同。遠端桌面依然需要你親自動手滑動鼠標、敲擊鍵盤,只是換一塊螢幕觀看;而Dispatch則是將手機化為「純粹的指令執行裝置」,而Mac端上的Claude才是真正的「執行者」,它會自動去點擊、打字、跨軟體操作,你完全不需要盯著螢幕看。
設定過程也出奇地簡單:只需將Mac上的Claude桌面版 (Cowork模式)更新,點擊新增的Dispatch選項,並且生成QR Code,再用手機版Claude掃描配對即可。唯一的先決條件是:你的Mac必須保持喚醒 (不休眠)狀態,而且Claude應用程式必須維持開啟。
實測成功率僅50%,但為何意義重大?
目前,Dispatch仍標示為「研究預覽」 (Research Preview)階段,同時僅先開放給最高階的Max訂閱方案用戶使用,而根據部分媒體實測,這項功能的表現幾乎是「喜憂參半」,綜合成功率僅約落在50%。
• 能做到的:精準找出截圖中含有特定關鍵字的圖片、操作Notion (列出筆記或新增網址)、讀取與總結最近收到的電子郵件。
• 做不到的:無法成功打開特定應用程式 (如Mac捷徑)、無法跨應用發送訊息 (如透過iMessage傳截圖給同事),而且在讀取Safari瀏覽器分頁,或需要第三方授權的服務時會面臨失敗。
在傳統軟體評測中,50%的成功率顯然是不及格的,但在AI Agent的發展語境下,卻是一個極具指標意義的里程碑。
回顧AI的「操作半徑」演進:2023年,AI只能在對話框裡產出文字與程式碼;2024年,AI開始能生成網頁元件 (如Artifacts);2025年初,Anthropic推出能接管滑鼠與鍵盤的Cowork功能,讓AI跨入整個作業系統桌面。而現在,Dispatch則成功跨越「物理設備」的界線,實現跨裝置的非同步代理操作。
「本地優先」架構:Anthropic最聰明的安全防線
雖然讓一個看不見的AI遠端接管你的個人電腦,聽起來令人毛骨悚然。為了解決這個信任危機,Anthropic在架構上做一個關鍵且聰明的決定:將執行端完全鎖死在本地 (Local)。
與許多將螢幕截圖上傳至雲端伺服器分析的遠端AI方案不同,Dispatch採用的路徑是:你的手機發出自然語言指令 → 指令傳送至Mac → Mac上的Claude於本地沙盒環境中執行操作。這意味你的私人郵件、工作檔案與螢幕畫面,從頭到尾都不會離開你的那台Mac,大幅降低隱私外洩的風險。
分析觀點
Anthropic近期的動作頻頻且極具戰略連貫性。從2月底針對工程師推出、能遠端控制終端機 (Terminal)的「Remote Control」,到現在針對一般用戶、能遠端控制圖形介面 (GUI)的「Dispatch」,Anthropic正試圖在OpenAI選擇收縮戰線、專注企業與寫程式碼能力的當下,搶下「跨裝置通用AI Agent」的霸主地位。
雖然Dispatch目前的成功率只有50%,但隨著模型迭代更新,這個數字在幾個月內勢必會快速攀升。我們真正該思考的是:當每個人家裡都有一台24小時不關機的Mac,上面跑著一個隨傳隨到、不用付薪水、不抱怨的「數位分身」時,我們對「工作」與「勞動力」的定義,將會發生多麼劇烈的翻轉?

清晨 6:45。你的日历里标注着 9:00 在会展中心的会议。
你还没起身,Agent 在后台已经完成了几轮判断。
今天气温升高了几度,有点热;当天场馆周边有大型活动,常走路线预计会很堵;车辆电量还剩 62%,足够往返。
于是系统自动将出发提醒从原本的闹钟时间提前至 7:20,同时将车内温度预设为 22 度,打开你惯常收听的晨间播客。
等你下楼、走出电梯、拉开车门,车已经像刚刚被人收拾好一样,温度合适,路线妥当,内容也备好了。
你没有按按钮,也没有说一句话,可它已经知道该做什么。这大概就是今天人们对 AI Agent 最具体、也最迷人的想象。

▲《钢铁侠》中的贾维斯就是这种幻想的终极表达
它不再只是网页上的一个对话框,不再只是你输入一句、它回一句的机器人。
它开始离开屏幕,走进物理世界,替你处理那些原本需要手、眼、耳同时介入的小事。
过去一个多月,这种科幻般的想象突然变得触手可及。即便平时不太关注 AI 的人,大概也刷到过那个频频出圈的「龙虾 OpenClaw」。
与过去那些只会聊天的 AI 不同, OpenClaw 这类工具看起来更符合大众脑海中「真正的 Agent」的形象,它能接管键盘和鼠标,在终端后台运行,直接调用系统 API 干活。
有人让它写代码,有人让它定时整理邮件、规划待办事项,还有人干脆把查航班、选座、值机这一整套杂活全扔给它。它就像一个永不下班的超级实习生,动作快、能力强,理论上什么活儿都能接。

但热潮来得快,退得也快。 算力配置昂贵、调用成本高,加上脆弱的安全默认设置,想要将其转化为稳定的生产力,中间还隔着重重门槛。
因此,舆论在很短时间里完成了一次反转,先是「第一批靠龙虾赚钱的人出现了」,接着就变成「第一批龙虾受害者出现了」,再后来,甚至有人开始花钱请人上门卸载。
手机端的 Agent 们也是类似的情况,能自动比价、下单、甚至发微信的豆包手机,刚一露头,就被各大平台联手设限。

屏幕里的 Agent 明明已经很聪明,却总在最后一步碰壁。这堵「墙」,有时是系统权限,有时是封闭生态,有时则是巨头们的商业利益。
这一困境恰好反衬出另一个硬件终端的巨大潜力——汽车,反而成了 Agent 最有可能率先落地的场景。
这件事颇具历史的讽刺意味。
新能源汽车刚兴起时,业界几乎一致认为,智能汽车会是继智能手机之后的下一个超级硬件入口。
那几年,车企的宣传口吻与手机厂商如出一辙:自研 OS、封闭生态、应用商店、开发者平台、争夺用户停留时长。
大家都把车做成「带轮子的大手机」。奔驰、宝马、大众都在讲自己的车载系统,吉利和沃尔沃成立亿咖通,比亚迪也早早就开放了自己的车载 SDK。
那时的大家都有一种很熟悉的乐观,好像只要把手机那套再复制一遍,中控屏就会成为新的黄金地段,广告、分成、增值服务都会顺着这些流进来。

▲ 各种各样的车载应用
但车终究不是手机。
车企们后来发现,除了导航和在线音乐,大多数车载 App 的活跃数据都惨不忍睹。没人真想在车里打游戏,在车机上购物总觉得别扭,短视频一上线就被安全监管盯上,连看起来极具想象空间的「车载 KTV」,实际使用率也远不如宣传的那般热闹。
毕竟,人开车上路是为了出行,而不是为了操作一块屏幕。
手机是一个能独占注意力的设备。你低头看屏幕、滑动手指,整个人都可以沉浸其中。但汽车不行,尤其是在驾驶过程中,驾驶员的眼睛必须注视路面,双手必须控制方向盘。
在时速 120 公里的高速上,视线只要离开路面 2 秒,车辆就已经向前飞驰了 67 米。在这 67 米的盲区里,足以发生任何意外。
车主们也很快意识到了这一点,为了打开座椅通风,居然要在屏幕里翻找二级菜单。这种看似「先进」的设计,真到了路上只会让人暴躁。
正因如此,智能座舱的发展轨迹并没有沿着「繁荣 App 生态」这条路继续走下去,而是几乎直接跳跃到了另一场革命:由大模型驱动的交互变革。那些曾被寄予厚望的车载 App,还没来得及开花结果就被边缘化了。

▲ 车企们逐渐恢复了物理按键
舞台的新主角换成了 Agent。它不再强调「我能给你提供多少个入口」,而是主打「我能替你把事办完」。
2019 年,小鹏 P7 曾把「全场景语音控制」作为一个极其亮眼的卖点。当时的评测经常演示这样一个场景:车主说一句「我有点冷」,空调温度就会自动调高 2 度。这在当时无疑是巨大的进步,比手动戳屏幕方便得多,也更有未来感。
但在工程逻辑上,它背后依然依赖着一张预设好的「语句—指令」映射表。系统听到「我有点冷」,就在代码表里匹配到对应选项,执行「空调升温 2 度」。这更像是一本厚厚的词典,翻页速度很快,但毫无思考能力。你说对了触发词,它就响应;你稍微换个说法,它就开始「我还不会哦」。

▲ 你好小 P
不过很快,我们将迎来具备主动感知能力的 Agent,它将开始能够理解意图,具备主动感知能力,并能跨系统编排复杂的动作。
它不会傻等着你发号施令,而是像一个资深的管家,平时就在一旁默默观察、聆听和记录。比如你说「今天心情不太好」,旧系统往往会礼貌地失灵,或者只是给你一点心灵鸡汤。
因为这句话不对应哪一个明确按键。可 Agent 可能会联想到情绪、环境、偏好之间的关系,自己把音量调低,把氛围灯收暗一点,切一首没那么躁的歌。它不一定每次都猜得完全准,但它已经不再只是在执行口令了。
腾讯之前展示过一种场景感知型 Agent,可以结合时间、地点、用户习惯主动给建议,也能接入点餐、停车缴费这类服务。

还有一些座舱 Agent 的预研方向,已经能识别后排乘客是否睡着,然后自动降低后排音量,微调温度,甚至改变出风方式。
想象一下,一家人周末出门,车开在高架上,后排的小孩睡着了,传统语音系统需要你说一句「把后排空调调小一点」。
真正的 Agent 却可能自己判断出,这时候要做的不是一个动作,而是一串连贯动作:把后排音响关小,调一下空调风向,稍微降低车窗透光率,让后排光线别那么亮;底盘切到更柔和的模式,把细碎颠簸过滤掉;如果智驾开着,再顺手把跟车策略调保守一点,让加减速更平滑。前排的大人甚至没有意识到自己下达过什么命令,车厢已经默默把环境改好了。
这就不再是一个功能在工作,而是整辆车作为一个整体,完成了一次从感知到响应的闭环。

这种真正让汽车和其他终端拉开差距的,是跨域协同的能力。
过去汽车的电子电气架构,像一座分租出去的大宅子。座舱域管娱乐、空调、座椅;底盘域管悬挂、制动、转向;智驾域管 ADAS 和自动驾驶。每一层都有自己的边界,彼此之间不像一间房那样自然贯通。
旧式语音系统,通常只能在某一个域里做单点操作,说白了就是隔着门传话。而 Agent 不一样。它收到的往往是模糊意图,却能跨过几扇门,把几个系统一起调度起来。
也正因如此,汽车可能是今天所有终端里,最适合 Agent 落地的那个容器。原因就在于它足够统一,足够封闭,也足够可控。

一个典型的反面例子是智能家居。
搞过装修的朋友都知道,家里的电器,空调是一个牌子,灯是一个牌子,窗帘电机又是另一个牌子,音箱和门锁也各玩各的协议。
看上去你买的是一套「智能生活」,实际到手常常是一堆彼此不怎么来往的设备。
Matter 协议 2022 年就出来了,试图给这个行业造一门通用语言,但各家厂商在底层依然固守着私有接口和数据壁垒。
所以现在智能家居最顺的体验,往往还是「全家桶」。

手机端面临的困境也大同小异。你想让手机助手点杯咖啡,再去微信提醒朋友,最后切到高德导航,听起来就 3 步,背后却牵涉到几家超级 App 之间漫长而脆弱的利益博弈。任何一方觉得吃亏,链路就会中断。
相比之下,汽车的情况简单得多。至少在车内这个封闭世界里,规则主要由车企自己说了算。底盘、空调、音响、座椅和灯光,天生就生长在同一张网络里。
当然,汽车座舱也并非乌托邦。它的使用场景更加集中,核心永远围绕出行、驾驶和在途体验,这使得 Agent 在车内比在手机上更容易构建出稳定的上下文逻辑。
但相应的,它的试错成本也高昂得多。智能家居误判最多半夜亮灯;车上的 Agent 一旦触及安全控制权发生误判,后果不堪设想。

近年来,中国新能源汽车市场的竞争日趋白热化,硬件层面的差距越缩越小。如今真正能拉开代差的,反而是智能化体验。
加上中国用户对新技术的接受度极高,这几股力量汇聚,形成了一个罕见的加速器。这也是为什么近两年来,最激进、最具规模的 Agent 上车实践大多发生在中国。
然而,当车内 Agent 进化到一定阶段后,很快又会面临新的瓶颈,它仅仅认识「坐在车里的你」是远远不够的。
它知道你喜欢听什么歌、习惯多少度的空调,这很有用,但还太浅。它还得知道你昨晚几点入睡,明天几点开会,最近常去哪里,何时最不想被打扰。
它需要把你当作一个生活在连续时间轴上的「完整的人」来理解。
这正是华为、小米这类拥有全场景生态体系的玩家最大的优势所在。他们的野心不止于「车里的 Agent」,而是要构建一个跨越不同终端的「个人 Agent」。
上周,小米推出了移动端 AI Agent 测试产品 Xiaomi miclaw,基于自研 MiMo 大模型构建,核心目标是验证大模型在「人车家全生态」中的任务执行能力。

Miclaw 以系统应用身份运行,可深度调用超过50项手机底层能力,涵盖短信、日历、相机乃至米家智能家居设备实现从「对话」到「执行」的跨越。
更值得关注的是它采用「自进化」设计,支持文件级记忆、子智能体创建和 MCP 服务接入,能自主设计记忆系统、创建专业分工的子智能体,用得越多,就越懂用户的偏好与习惯。
虽然 Miclaw 还没有完成人车家全生态的接入,但趋势已经相当明显,你在不同设备上留下的行为数据,将被拼接成一条完整的生活轨迹。

▲小米 Claw 的部分功能
这时,文章开头描绘的那个清晨场景就不再是科幻电影,而是越来越多人的日常。
Agent 掌握了你的日程、习惯和生理状态,于是悄无声息地提前了唤醒时间,重新规划了路线,并为你布置好了舒适的座舱环境。
技术发展的最终形态,经常会出现一种有趣的「反转」,最成熟的技术,往往既不科幻,也不性感。
蒸汽机刚发明时,所有人都盯着那股喷涌的巨大白汽;而当电力真正普及后,人们反而很少低头去留意墙里的线路。

Agent 亦是如此。它真正动人的力量,不在于把人训练成更加熟练的机器操作员,不在于逼迫你熟记更多的唤醒词和口令;而在于它能不动声色地将你从繁琐的操作中彻底解放出来。
未来的汽车依然是那辆汽车,方向盘、座椅、车窗和轮胎都还在。但它已经开始理解你的生活节奏,记住你的个人偏好,默默替你打理好那些原本需要你亲自动手、动脑去安排的每一件小事。
#欢迎关注爱范儿官方微信公众号:爱范儿(微信号:ifanr),更多精彩内容第一时间为您奉上。

Meta 執行長 Mark Zuckerberg 正開發專屬 AI 智慧體「CEO Agent」,協助決策,內部更已將 AI 工具使用納入績效考核,員工智慧體甚至能代理溝通與開會。
當全球科技巨頭都在爭奪通用AI (AGI)的解釋權時,Meta執行長Mark Zuckerberg似乎正試圖先解決自己的「辦公室焦慮」。根據華爾街日報報導,Mark Zuckerberg目前正親自帶領團隊開發一款名為「CEO Agent」的專屬AI智慧體,這款工具並非只是簡單的語音助理,而是能深度介入Meta決策核心的「數位分身」。更令人驚訝的是,Meta內部的AI自動化程度已達到「代理對代理」 (Agent-to-Agent)的程度,員工甚至已經開始讓各自的AI智慧體「互相開會」,並且達成共識。
「CEO Agent」:Mark Zuckberg的決策加速器
據了解,這款仍處於開發階段的「CEO Agent」,其核心目標是協助Mark Zuckberg在龐大的Meta管理層中更快速地獲取關鍵資訊與數據。
不同於市面上一般的AI聊天機器人,「CEO Agent」預期將擁有存取Meta內部最底層、最機密數據的權限。它能自動分析各部門的即時進度、財務報表,甚至是在Mark Zuckberg召開重大的策略會議前,預先模擬各種決策可能帶來的市場反應。
這意味著,Mark Zuckberg未來的日常管理工作,將大幅從「閱讀報告」轉向與「AI摘要與預測」進行高層級的決策互動。
Meta內部生態:AI使用已列入績效考核
除了執行長本人,Meta內部的AI普及速度也快得驚人。報導指出,Meta已經將「AI工具的使用」正式納入員工的績效考核體系 (Performance Review)。
目前Meta員工最常使用的工具之一是名為「My Claw」的個人智慧體:
• 深度存取:該智慧體擁有讀取員工聊天記錄、電子郵件與工作文件的權限。
• 代理溝通:它能代表員工直接與同事進行溝通,甚至與同事的AI智慧體「交換意見」。
• 專屬群組:Meta內部甚至出現了一個極其特殊的現象——一個由「員工個人智慧體」組成的專屬交流群組。在這個群組裡,人類員工不需要出面,智慧體之間便能自動對接工作細節、協調會議時間或確認文件版本。
在Meta的內部論壇上,目前充滿員工分享如何自建AI工具來優化工作流程的「攻略貼」。
分析觀點
Meta這波由上而下的AI轉型,背後隱含著一個極具野心的假設:未來的企業效率,將取決於「代理化」 (Agentic)的程度。
Mark Zuckberg打造「CEO Agent」,不僅是為了給自己省事,更是在立下一個產業標竿。當一個執行長能透過AI瞬間掌握全球數萬名員工的營運細節時,傳統的階層化管理結構 (Middle Management)將面臨毀滅性的挑戰。資訊將不再需要透過一層層的人力報告,而是直接由數據驅動。
而Meta內部的「代理對代理」溝通模式,更是預告未來職場的雛形。過去我們煩惱「這封信該怎麼回」,未來則是你的AI代理直接去跟對方的AI代理「談好」結果。這種高度自動化的代價,是企業必須面臨更嚴峻的資安與隱私邊界挑戰——畢竟,當AI代理擁有存取所有對話與文件的權限時,如何防止機密外洩或「AI合謀」誤導決策,將是Meta這場實驗能否成功的關鍵。

Arm 歷史性地推出首款自主設計的實體矽晶片產品「Arm AGI CPU」,採用台積電 3nm 製程,搭載 136 個核心,效能較 x86 平台高出兩倍以上,並由 Meta 作為首發共同開發夥伴。
在過去三十多年裡,Arm一直以提供IP矽智財與運算子系統 (CSS)授權為核心商業模式,但這項傳統在今日 (3/24)正式被打破。Arm歷史性地宣布推出首款由官方親自操刀設計,並且投入量產的實體矽晶片產品——「Arm AGI CPU」。這款專為AI資料中心量身打造的處理器,將劍指近期快速崛起的「代理式AI」 (Agentic AI)基礎設施需求,更由Meta作為首發共同開發夥伴。憑藉台積電3nm製程加持,Arm AGI CPU標榜能提供比傳統x86平台高出兩倍以上的機架運算效能。
打破IP授權框架:為何Arm決定親自跳下來做晶片?
早在先前有不少傳聞時,Arm執行長Rene Haas在去年就已經證實將推出自有品牌晶片,並且在此次活動上正式揭曉。而要理解Arm為何跨出這歷史性的一步,必須先看懂「代理式AI」帶來的基礎設施變革。
Rene Haas在聲明中表示,AI已經徹底重新定義運算的建構與佈署方式。過去的AI基礎設施高度集中在GPU的「模型訓練」上;但隨著AI應用轉向佈署持續運行的「AI代理」 (AI Agents)時,這些系統需要不斷地進行推理、規劃、協調與資料搬移,導致AI系統生成的Token數量呈指數級增長。
根據預估,當企業大規模導入代理驅動的應用時,每GW (吉瓦)電力所需的CPU數量將暴增超過4倍。但在功耗限制下,傳統x86處理器的複雜架構與高能耗已經難以負荷。
因此為了協助合作夥伴加快佈署AI代理速度,Arm決定打破過往僅提供IP或CSS (運算子系統)的「慣例」,直接推出自有品牌實體晶片,為市場提供更具彈性且直接的硬體選擇。
136核心與台積電3nm加持:效能直逼x86架構的兩倍
作為首發之作,Arm AGI CPU在硬體規格與能效表現上展現極強的企圖心:
• 頂尖核心與頻寬:單顆CPU搭載高達136個Arm Neoverse V3核心,並且提供每核心6GB/s的記憶體頻寬與低於100ns的延遲表現。
• 極致能效 (TDP):功耗控制在300瓦 (TDP),同時每個程式執行緒均配置專屬核心,確保在持續高負載下提供決定性的效能,消除降頻與閒置執行的浪費。
• 超高機架密度:支援高密度1U伺服器機架。在氣冷佈署模式下,每組機架可容納高達8160個CPU核心;若採用液冷系統設計,則能推升至每機架對應超過45000個CPU核心。
這款晶片交由台積電以其先進的3nm製程代工製造。Arm強調,AGI CPU每機架效能是傳統x86架構CPU的2倍以上,這意味著在每吉瓦的AI資料中心建置中,將能為企業省下高達100億美元的資本支出。
科技巨頭齊聲力挺,Meta成為首發聯合開發夥伴
Arm這次親自跳下來做晶片,並未引發原有IP客戶的強烈反彈,反而獲得業界極度廣泛的支持。
Meta更成為該晶片的首發合作夥伴與共同開發者。Meta基礎設施主管Santosh Janardhan表示,Meta將利用Arm AGI CPU來優化其應用程式家族的基礎設施,並且將其與Meta自研的AI加速晶片「MTIA」協同運作,藉此實現在大規模AI系統中更有效率的運算調度,而雙方也承諾將在未來多個世代的產品路線圖中持續深入合作。
除了Meta,包含OpenAI、Cerebras、Cloudflare、SAP與SK Telecom在內的多家企業也均確認將導入此晶片,用於加速器管理、控制平面處理,以及雲端API託管等核心任務。
而在硬體系統端,Arm已經與華擎 (ASRock Rack)、聯想 (Lenovo)、廣達 (Quanta Computer)及Supermicro等OEM及ODM 廠展開合作,預計今年下半年將有更多系統投入市場。
此外,包含AWS、Google、微軟、NVIDIA (執行長黃仁勳亦對此發表祝賀),以及三星、SK 海力士 (SK hynix)等超過50家科技巨頭,也都對Arm擴展至晶片產品線表達大力支持。
分析觀點
外界最初擔憂,Arm自己賣晶片是否會與AWS、Google或微軟這些已經利用Arm架構自行開發自有設計CPU的大客戶產生利益衝突?
從結果來看,Arm將AGI CPU的定位精準切入「代理式AI」這個新興且需才孔急的特殊領域。對於像Meta或OpenAI這樣需要海量CPU來搭配自家AI加速器,卻又不見得想投入龐大資源去「從零設計通用CPU」的廠商來說,直接購買現成、已經將Neoverse V3效能榨到極限的Arm AGI CPU,是最具成本效益的做法。
同時,這也是Arm針對x86陣營 (Intel與AMD)在資料中心領域發起的一場「絕殺」。當僅有300W熱設計功耗的Arm晶片能透過台積電3nm製程,在相同機架與電力限制下塞入136個核心,並且提供兩倍於x86架構CPU的效能時,x86架構在AI時代「功耗比過高」的致命傷將被進一步放大,同時也象徵資料中心的運算主力,正無可避免地向 ARM 架構全面傾斜。

今年春节,OpenClaw 火了。短短两个月不到,它又冷下去了——又一场 AI 应用层面的热闹。
热闹散了,没人知道下一个 OpenClaw 是谁,也没人知道这些东西究竟在解决什么问题。
用影像旗舰手机拍下一张夜景当中的人脸,细节清晰到能看见眼眶里的水光。但手机可能并不清楚,主角刚才是否哭泣,也就无法理解这张佳作的情绪背景;再用长焦技能把数百米外的一个路人拉到面前,细节纤毫毕现。但你问手机:这个人是着急赶路,还是在找什么东西?手机仍然不知道。
今天的 agent 能写代码、能操控网页、能把一份 PDF 整理成会议纪要。这些它都做得不错。但这些事情有一个共同点:处理的全是人类已经事先转好格式的信息。文件、数据库、网页,都是数字化过的世界。一旦面对物理世界,一扇门、一段动作、一个表情,它们是失明的。
从今天的大模型,到能真正读懂物理世界的所谓「具身智能」,中间有一道鸿沟,现在没有人说得清楚怎么填。
这道鸿沟,是胡柏山在博鳌亚洲论坛上花了最多时间讲的一件事。
胡柏山是 vivo 总裁兼首席运营官。在博鳌亚洲论坛,他告诉爱范儿,自己有一个很直接的判断:「在明确的物理大模型没有出来之前,要有好的体验,就要把物理世界的信息转化到数字世界。」
他相信,这件事,不仅手机可以做,而且应该用手机去做。甚至在未来十年里,其它设备都很难替代。

过去两年,几乎所有手机厂商都在说「AI 手机」。大模型接入、智能助手升级、端侧算力提升,这些能力以肉眼可见的速度在普及。
去年 DeepSeek 横空出世,今年 OpenClaw 引爆讨论,各家都在抢着把最新的模型能力塞进自己的产品。
这场军备竞赛,有一个必然的结局:大模型的高度商品化、同质化、可替代化。
拼模型能力,没有护城河。
你比友商快三个月上线某大模型,以及大模型驱动的 agent 功能;友商六个月后跟上,用的模型和 agent 能力都比你更强。时间上的领先、花费的金钱和精力,卷出的工时和损耗的员工健康,价值又是什么?
于是,真正的差异化只能在别处找。
vivo 给出的答案是「感知」。

感知,是 vivo 刚刚成立的新技术赛道。
中外互联网公司和手机品牌纷纷加速进军「AI 手机」。行业一度以为模型能力会成为手机厂商的护城河。
在胡柏山看来,实际并非如此。「相比模型而言,积累下来的场景数据才最有差异化。」紧接着他补了一句:「当然,该做还是要做,要做就找适合我们的,可以做慢一点,晚一点也 ok。」
当被问及「如果不看好大语言模型,vivo 会否发力世界模型」时,他的回答更加保守却又直接:「世界模型也很大。我们还是找适合我们的技术路径。我们先把手机模型搞好,小模型搞好。」
当今 AI / 互联网科技巨头大打人才争夺战,顶级研究精英如 NBA 巨星般抢手,转会费一再突破新高。但胡柏山并不认为 vivo 应该为这团火再添柴。他告诉爱范儿,先想清楚思路,看清方向,定好技术平台,再发力,完全不迟。
在这个所有人都在比拼模型能力和 AI 人才储备的时间点上,掌门人直接把 vivo 的优劣势与行动纲领展开在媒体面前。这种坦诚令人印象深刻:vivo 的稳健、谨慎, 究竟有何用意?

胡柏山回应称,vivo 从不回避竞争。相比模型、算力,未来最大的差异化是来自于场景数据。
场景数据,是跟着使用行为逐渐积累的,不能批发,不能抄近路——影像数据尤其如此。经过十年光学硬件积累、用真实场景训练出来的感知判断,没有捷径。
而这些积累与判断,构成了 vivo 接下来押注的「感知」的底层。这些东西,其他人(无论友商还是互联网/AI 公司)想要,也只能自己去积累。
这就回到了刚才那道鸿沟。大模型的训练数据是互联网信息,而这些信息已经被数字化。但现实世界里大多数有价值的信息,还没被数字化。那些无法或很难被转化,或者转化起来成本极高的数据,成为了 AI 走向现实世界的障碍。
光线、空间、人脸、动作、情绪,这些东西存在于物理世界,需要被感知、被转化,才能成为模型可以处理的输入。谁的感知做得好,谁就控制了大模型进入现实世界的那扇门。
现在,没有人知道这扇门后面是什么,也没有人知道最后会是谁站在那里。
感知不只是「更好的相机」,这一点 vivo 很清楚。
胡柏山说,相机是记录工具,它等你按下快门。但感知是另一件事:持续观察、理解正在发生什么,把这些信息转化成设备可以直接使用的输入。7×24 小时,不需要你触发。
从「记录」到「感知」,中间隔着一个系统架构的重建。
胡柏山给这件事起了个名字:「感知一体」。字面意思,是感知到的信息和设备的决策系统要即时打通。这一点,现在还做不到。
难点在于,原始的感知场景数据,比如一段视频、一张图、麦克风收到的声音,体量巨大,格式混乱,里面大部分是噪声。把这些原始信号转化成手机真正「读得懂」的结构化信息,需要一整套专门的处理链路。
「怎么把场景数据转换成手机能够读懂的数据,是最难的。这个领域开源资源少,需要自主探索,」他说。
这也是为什么 vivo 在内部把感知设为一级技术赛道。
「一级」意味着感知不再是影像部门下面的一个子方向,它会统揽包括视、听、嗅、触等多种感官种类,和感知方向。
不过,vivo 的感知研究与研发工作仍处在初期阶段。胡柏山用 vivo 的通信研究院做了一个类比:大约 200 人的团队,从 4G 开始持续投入,走过 5G,现在在做 6G,已经十几年了。
对于感知赛道,他的预期是相似的节奏:小团队作战,先构建认知。认知清晰了,开始加油门;等待软硬件生态成熟了后,油门再往下踩。「有一种渐进式加速、螺旋上升的感觉。我们拒绝一脚油门一脚刹车。」
胡柏山不希望 vivo 做感知计算,以及做任何事情,出现拍脑门、砸大钱的做法。他认为,感知是一个天花板很高,但今天没人能说清楚正确的技术演进路线是什么的东西。「我们准备好用五年、十年的周期来持续投入。但我们对这件事的认知获取,要循序渐进。认知没到,砸钱都是烂尾工程。」
感知赛道是一个判断,但判断要落地,需要现成的积累。
vivo 的底牌是十年影像。具体看,这十年沉淀的东西有两层。
第一层是硬件。与蔡司的合作,如今已经走到了联合研发的深水阶段,传感器尺寸这一轮 X300 Ultra 的主摄升到了 1/1.12 英寸,和索尼的合作在往提升半导体转化效率的方向走——他提到了感官技术方面的「雪崩效应」,一种可以把感光元件的进光转化率,从 90% 推到 110% 以上甚至更高的新技术路径。
在硬件层面,胡柏山的判断和行业观察者及媒体大致相同,传感器尺寸已经卷到了边际收益递减的阶段,接下来更大的空间在转化效率和外挂形态——在 X300 Ultra 上,vivo 已经做了 200mm、400mm 定焦增距镜,还有更多在路上。

第二层是算法和认知。
vivo 三年前提出长焦大底,两年后全行业跟上。但跟上硬件很容易,「为什么是那个时间点做这件事」,这个判断很难。vivo 为什么选择在那个时间点上做这件事,动机来自于在影像上多年领跑的经验所形成的认知——没有可以搬运和复制的捷径。
「算法跟认知强相关——认知知道要什么方向,算法匹配,这是需求和技术的有机结合,对手很难快速跟上。」
这个逻辑延伸到端侧 AI 上同样成立。在 X300 Ultra 上,vivo 首次提出了一种「多 agent」理念,也即:
你举起手机拍一张照片,有个 agent 在判断你在拍什么、用多远的焦段、在什么光线下——这个判断,以前需要用户自己去做。而另一个 agent 在整理你的相册,根据你过去的修图习惯推荐或自动添加滤镜,又或者它能自动把几段素材剪成一条可以直接发的短视频。
这不是那种统一的「超级 agent」,比如 Gemini 或豆包手机助手那样的,而是每个场景一个专项 agent,既互通有无,又各干各的。
胡柏山的理由很实际:现有的硬件算力撑不起一个什么都管的大 agent,手机AI的发展要结合硬件的能力上限来推进。
这些工作仰仗 vivo 在端侧 AI 推理上的持续投入。据爱范儿了解,vivo 是手机厂商当中目前在算力购买上花钱最多的——不仅是云端算力,接下来的押注方向,是在旗舰机上嵌入专用的算力芯片。
vivo 的节奏是:先把不要求实时响应的 agent 做好,影像和相册是当前优先级;全域感知是五到十年的目标,always-on、全时段在线、所有感官打通,这是最终的方向。
今后十年的 vivo,会去往什么方向?
胡柏山给了一个大概的路线图:手机是现在用户的核心产品,往后至少 10 年也仍然不变;MR 需要三到四年;机器人是五年以上。
这三个方向不是各自独立的押注,底层是同一套感知能力在不同形态上的延伸。
vivo 去年成立了机器人 Lab,聚焦「大脑和眼睛」。当被问及目前进展如何,胡柏山很直接地摊牌:「2025年把阶段性目标梳理地更加清楚,2026年进入整个路径的清晰规划。」
但这对于 vivo 来说并不是问题。
在一个各家都在发布机器人样机、争相宣称「具身智能元年」的节点,承认自己还没手搓出实物,是一种不多见的坦诚。胡柏山说「手搓一个机器人不是我们要干的。」
vivo 的机器人逻辑,和感知赛道的投入逻辑是一套:先想清楚目标用户是谁,再定义场景,再识别核心技术控制点,再等技术成熟度到位。
胡柏山告诉爱范儿,目前 vivo 还在论证第一步。他们倾向于服务年轻人,这也正是 vivo 从旗舰到年轻系列产品线一直希望抢占心智的群体。vivo 的第一代家庭机器人,可能的起点,是照顾宠物和叠衣服也说不定。
但这个场景,会不会太小?胡柏山认为,不能一上来就做通用机器人,不可能刚一开始就把所有的场景都做好。如果你非要那么做,最终的结果也只能是每个场景都不及格。
诚然,今天的具身智能机器人,可能做预录制的舞蹈能做到一百分,其他场景都没有足够的说服力。特别是在家务场景,「就说打鸡蛋这件事,想要做到百分百成功率,人都不一定,机器人十年内也做不到。」
胡柏山希望,vivo 的机器人能够先把一件具体的事情做到 60-70 分,然后一代一代泛化,优化现有的场景,再获得新的能力。
喂好了宠物,场景数据就来了。场景数据够了,机器人就知道这只狗每天几点饿,进而知道这家人几点起床,进而知道这家人的生活节律。不需要一步到位,因为每一步都在为下一步备料。胡柏山管这叫「沿途下蛋」。
这个逻辑,和在手机端押注感知的逻辑,是统一的:先把影像 agent 做好,场景数据够了,感知能力才往外延伸。
但在机器人的旁边,手机扮演什么角色?「手机是最懂你的随身数字助理。你的行为习惯、偏好、你喜欢养什么宠物,都在手机里。」胡柏山说,机器人早期做不好的事,手机可以遥控介入补足。
就像自动驾驶的早期,人类一直在干预,干预产生数据,数据让系统越来越好。「手机和机器人之间,场景数据是打通的。」
当然,他也没有把话说满。感知这个赛道,其他人也在做。包括苹果、谷歌等在内都有自己的感知计算框架。vivo 在这个方向上的竞争空间,更多在手机端的小模型感知这个细分方向。这是除了苹果以外的大厂,暂时没有重点关注的地方。
今年,胡柏山给机器人 Lab 设的任务,是把路径图画出来:目标用户、核心场景、关键技术节点、以及「技术成熟到可以商业化」的时间预期。
vivo 叫停了 AI 眼镜项目。他算了一笔账:一年几十万台,不符合目标体量;两年内又做不出差异化;技术平台目前也撑不起 80 分以上的体验(超过 30g 戴在鼻子上会很累)——三个条件一个都没过,砍掉没毛病。
「三年后做也不着急,它不是关键品类。」
不过,这个决定放在今天的背景下,还是有点逆势。2025 年 AI 眼镜是行业里最热的新品类之一,这个事实有目共睹。Ray-Ban Meta 卖爆,国内跟进者一茬接一茬。
创始人兼 CEO 沈炜在年会上表示,vivo 今年的策略是「少押注,押重注」。vivo 选择给 AI 眼镜按下暂停键,但将感知赛道的存在地位升级,其实是统一的逻辑和筛选标准的一体两面:一个赛道的天花板够不够高、vivo 自身的差异化属性够不够、技术平台能不能支撑长期投入。
这种思路,与近期 OpenAI 等在内的硅谷巨头,摒弃「支线任务」,聚焦真正长板的思路不谋而合。
2026 年选定的道路,vivo 会走到哪,现在胡柏山也还给不出答案。感知一体化的技术难题还没有解,端侧专用芯片的落地有难度,机器人的路径图今年才刚开始画。
胡柏山知道这些,也没有回避。他说,认知到了加油门,认知没到宁可慢。
手机行业正在经历一个奇怪的时刻:换机周期拉长到四十个月,中国市场年销量从高峰期的五亿多部跌到现在约 2.5 亿部,存量市场的天花板清晰可见;但 AI 带来的能力跃升,又让所有人觉得什么地方似乎还藏着一点增量。
胡柏山的判断是,从 Smartphone(智能手机)到 Agent Phone(智能体手机),才是把存量市场变成增量市场的机会。而感知,是这个机会里他认为最难被复制的护城河。
接下来交给时间。
#欢迎关注爱范儿官方微信公众号:爱范儿(微信号:ifanr),更多精彩内容第一时间为您奉上。
在此前《软件 AI 化,势不可挡|AI Agent 是什么?》的文章里,详细总结了下 AI Agent,青小蛙觉得可以更简单的理解:
AI Agent,就是 AI 代理人:它替人类工作,帮你操作电脑,自己决定怎么做,并持续执行,就像牛马一样,给定目标,完成目标。

几天前,论坛中接连有人介绍 Open Minis,非常棒的一款免费应用,它有点类似 OpenClaw,在 iOS 里控制一套完整的 iSH (Alpine Linux) 虚拟机,有终端,有浏览器。
一起来看下这两篇文章:
你或许听说过或用过 Manus,它能在其云端运行虚拟机或者有头浏览器,并且能自己运行命令或者操控网页。
在 Manus 同期,实际上像是 Claude Code 或者 Codex 这样的 AI Agent App 也能靠 PlayWright 来达到类似的效果,这样你就可以在本地来让 AI 进行作业了。
之后 OpenClaw 其实是在这个基础上,集成了各类渠道,这样你就可以用聊天软件直接发消息让 bot 执行命令。
但这终究有局限性,你会发现这些方式都不能很好的和你的手机进行交互,你的手机只是一个给 AI 发消息的工具,AI 却不能反过来使用你的手机。
Open Minis 能通过在本地模拟运行一个 Linux 虚拟机(魔改 iSH),并通过命令行工具来读取 iOS 的设备端功能,例如地图、照片、日程、闹钟等。
Open Minis 可以:
并且也有 skills 和记忆的支持,你可以认为 OpenClaw 能做到的,它也能做到。并且由于能读取设备端能力,所以可能实际体验要更好。



此外,也支持使用快捷指令执行定时任务。或者,你可以这样将其改成使用 Action Button 即可触发的全局 ai 助手:


@RachelSherman 同学说:AI帮我写的文案,味道有点大,轻喷,我不是开发者,觉得很好用,分享一下
青小蛙手动总结一下吧:




原文:https://www.appinn.com/open-minis/
非常不错的应用,开发者更新频繁,并且 TestFlight 测试版本还有名额,想尝试的同学不要错过哦。
你有没有试过这样一种感觉:有些事情,你明明知道 iPhone 能做,但就是懒得打开 App,一步步操作。
现在不太一样了,创建日历、记录咖啡摄入、自动生成视频……
iPhone 开始可以自己把这些事做完了。
 11")
昨天介绍了:Open Minis:可能是 iOS 端最强 AI Agent 之后,看到开发者这些天陆陆续续转发的一些案例,非常有趣,也很实用。
青小蛙总结了 11 个 iPhone 开启 Open Minis 后能做的事情,它只有 49.8 MB 的大小。
你觉得还能做什么呢?
将带有时间、地点、事件的内容直接分析给 Minis,就可以创建日历:(via)
 12")
让 Minis 直接读取并分享健康信息:(via)
 13")
直接让 Minis 读取 Apple Watch 中的数据,分析健康情况(via)
 14")
将图片发给 Minis,让他通过 Spotify Skill 搜索歌曲、切歌播放。
 15")
这个看起来有点离谱了,流程大概是这样的:(via)
这个效果也不错,将 TikTok 评论截图发给 Minis,并最终导出到了 YouTube Music 歌单中:
 16")
这也是一个很有趣的流程,你可以根据自己感兴趣的内容来源,让他帮你自动生成音频,在早上的时候播放出来,替代闹钟。
 17")
这是开发者 @Ethan 自己的用途,它的社群消息有非常多的用户反馈,使用 Minis 读取反馈,整理信息,最终写入系统提醒应用中。
后续,当修复了 Bug 之后,还会自动对照代码库,标记完成。
 18")
这里有一个例子,将 xiaohongshu-cli 的 GitHub 页面直接给它,让他整理为笔记文档,最终在 iOS 笔记应用中,看到了整理后的使用笔记:(via)
 19")
直接拍照两颗胶囊咖啡,然后让它记录到健康中。再结合之前的自动分析健康数据,闭环了。
 20")
对于一些复杂的重复性操作,交给 Minis 简直太爽了。(via)
比如这个例子中,让 Minis 设置了很多个起床闹钟,自动,不动手。
如果是以往,你需要一个一个手动处理,还容易出错…
 21")
原文:https://www.appinn.com/iphone-automation-11-real-use-cases/
自 2025 年末以來,一款名為「OpenClaw」的開源工具迅速改寫了全球科技產業的版圖。這款由奧地利工程師 […]
The post OpenClaw 中國企業採用率已達美國兩倍,不使用甚至可能被開除 appeared first on 電腦王阿達.

如今,每家企業都在思考,該如何讓生成式 AI 從「對話小幫手」進化成可以自主規劃、思考與執行能力的數位戰友?在 Google Cloud AI 加速日當中,Google Cloud 台灣總經理 Mike Chen 勾勒清晰藍圖,指出 2026 年將是 Agentic AI(代理式 AI)大爆發的關鍵元年。
本次活動震撼產業的亮點之一,是 Google Cloud 剖析 AI Agent 無縫融入企業的五大核心運作:賦能員工日常生產力、融入核心工作流程、打造極致客戶體驗、主動式資安防禦,乃至於推動規模化與人才升級。

要發揮上述五大核心動能,勢必仰賴 Google Cloud 完整的技術堆疊(Full Stack)AI 開發架構。這套架構正是 Google Cloud 支持企業轉型的幾個關鍵層級,從底層的 TPU 算力、現代化資料與分析、核心研究與模型,再貫穿到 AI 開發平台(Vertex AI)以及最上層的 Gemini Enterprise。多項解決方案凸顯 Google Cloud 為企業指引代理式 AI 之路,不再只是紙上談兵,而是真正引領產業,邁向自動化營運的下一世代智慧競爭新局。
過去,企業轉型 AI 面臨最大痛點是如何跨越概念驗證(PoC)到正式生產環境這一段鴻溝?Google Cloud 大中華區架構師總監 William Tsoi 解釋,當前各家 CEO 與決策者看待 AI 已從效率實驗,轉向能大規模執行的實際投資報酬率。企業組織在 AI 的部署與開發,往往不僅止於模型或平台的單點需求。為此,Google Cloud 提供一個完整的技術堆疊模式,從基礎架構算力、模型平台到代理一應俱全。
從基礎層開始,為讓企業內龐大又複雜的多代理系統(Multi-agent systems)持續運作,Google Cloud 打造最新一代超級電腦 TPU「Ironwood」,不僅讓每瓦電源效率翻倍突破,且大幅降低大模型推論成本,而其現代化數據平台(例如 BigQuery)則可消弭企業最頭痛的資料孤島、資料溯源問題,讓有效的數據加值 AI 應用成效。
有了堅實的算力與資料平台,企業也需聰明「大腦」發想創新。Google Cloud 台灣 AI 架構師 Ethan Huang 剖析最新 Gemini 3 相關優勢,具備業界頂尖的多模態理解力,特別是規劃(Planning)、推理(Reasoning)能力持續進化,確保模型在處理複雜多輪對話時,思考脈絡不因此中斷。

然而,企業只進化大腦還不夠,還要將自身業務數據投入到實際的生產與營運環境。此時亟需一站式 Vertex AI 平台,幫助企業無縫介接前瞻模型、實作檢索增強生成(RAG),打造企業專屬知識庫,將完整的模型評估與優化流程串接,進而大幅加速商業應用的開發與迭代。
開發團隊在 Vertex AI 平台建構強大的 AI 應用後,代理式 AI 落地最後一哩路,除了將這些能力提供給每位員工,更要杜絕影子 AI(Shadow AI)也就是資料外洩的危機。位於架構最頂層的 Gemini Enterprise 正是終極解方。Gemini Enterprise 可視為企業級資安合規作業的中樞與開放生態系,可透過專屬連接器(Connectors)打通企業內部如 Workspace、Jira 等各項 SaaS 服務,讓一般員工在安全環境下,利用直覺的介面快速打造專屬的 No-code Agent(無程式碼代理)自動完成日常任務;而專業技術團隊則可整合業界多元的開源框架,部署高度複雜的 Pro-code Agent(程式碼代理)。
綜觀可發現,企業要佈建邁向 AI 世代的營運護城河,從底層 TPU 算力防護、中層資料庫、模型與 Vertex AI 開發平台,一路再到頂層賦能全體員工的 Gemini Enterprise,Google Cloud 的全端生態系將持續擔任企業的絕佳轉型夥伴。
正如 Mike Chen 所言,隨著全球迎向代理式 AI 元年,企業不再是比算力軍備,而是讓 AI 資源更有彈性配置。為解決企業常見的算力閒置困境,Google Cloud 透過動態工作負載排程器(DWS),幫助企業的運算資源投資報酬率最大化。然而,光有靈活算力引擎仍不夠,若企業的核心數據困在老舊系統中,AI 代理終究缺乏燃料來啟動。針對潛藏於傳統關聯式資料庫中的龐大資產,Google Cloud 鋪設一條 AI-Ready 的轉型路徑。
首先,針對架構目標可藉由 AlloyDB 與 Spanner 等次世代資料庫,以 PostgreSQL 資料庫為核心,為企業提供原生支援 ScaNN 億級向量搜尋與多模態語意理解的強大樞紐。接著,為了幫助企業跨越「資料搬遷」障礙,Google Cloud 在資料庫遷移服務(DMS)導入具備 Agent 能力的 Gemini Conversion Assistant。過去極度依賴人工轉換的傳統資料庫語法,現在只需透過自然語言交由 AI 就能自動解釋、轉換與修復。

隨著算力與資料庫備妥,下一步便是將數據從被動儲存轉為主動活化。資料分析應用方面,可觀察到 Google Cloud 針對 BigQuery 推出連續查詢(Continuous Query)功能,企業直接使用 SQL 語法處理即時串流數據,甚至用 AI Functions 一站式處理非結構化的影像與文本。例如在交易場景中,系統會結合 AI 代理在毫秒之間做詐欺偵測,即時觸發第三方系統進行處理。另外,新亮相的 Conversational Analytics for BigQuery 為企業輕鬆建立專屬的資料分析 Agent,讓業務人員得以自然語言對話挖掘商業洞察,真正善用 AI 挖掘資料價值。
當商業數據大量運用,企業的防護網也不能忽視「駭客全面 AI 化」。面對五分鐘即可生成的精準釣魚攻擊與海量的告警疲勞,傳統人工盤查的被動手段難以招架。Google Cloud 把 Agentic AI 能力直接內建到 Google Cloud 資案解決方案,透過 Google SecOps 打造主動防禦代理式資安營運中心(Agentic SOC)。依循業界標準的 MCP(模型上下文協定),資安系統會自動跨平台串接威脅情資、分析攻擊指令,並完整還原攻擊者的處理程序樹(Process Tree)。此變革可望釋放更多資安團隊的量能,讓企業防護從被動狀態,升級到具備主動推理與自動阻斷的實力。
當算力與數據的「AI 基石」確實鞏固後,企業下一步便是將這些潛能轉化為前線戰鬥力,幫助員工解鎖 AI 動能、驅動商業價值。其中的首要關鍵,是讓精準的知識檢索走入業務場景,以金融業為例,玉山銀行主任工程師陳建安提到,為解決理專人力稀缺痛點,他們利用 AlloyDB 內建的 pgvector,快速在雲端建構出 7x24 小時的「投資 i-chat」精準 RAG 諮詢服務,將龐雜的市場資訊與理財產品有效媒合並提供給顧客參考。
除了金融業的創新案例,Google Cloud 也希望透過 BigQuery Data Canvas 賦能更多產業的第一線業務人員。在無需撰寫 SQL 的前提下,運用自然語言就能在智慧化的畫布上進行提問,內建的 Data Agent 會自動建議相關聯的資料表、生成視覺化圖表與邏輯心智圖。一方面讓全體員工透過 AI 洞察到以往忽略的機會;另一方面也能完整記錄前人的分析脈絡,未來組織人員若有異動,新人也能無縫接手並持續深掘,達成系統化知識傳承的終極目標。

要讓 AI 應用場景百花齊放,背後也須開發團隊的投入。本次論壇中可發現,Google Cloud 為軟體工程帶來從 Vibe Coding 跨越到 Agentic Engineering 的顛覆變革。透過 Gemini Code Assist 的 Agent Mode 與靈活的 Gemini CLI,開發者不再只依賴單行程式碼自動補全,而是能讓 AI 代理理解系統架構、跨檔案修改並自動建立測試環境。此外,結合終端機、瀏覽器與 Agent 於一身的開發神器 Antigravity,更讓開發者在隔離的沙盒環境下平行多工,大幅縮短應用程式從設計到上線的迭代週期。
隨著開發與業務雙重加速,Google Cloud 展現更大野心欲將 Agentic AI 普及至企業各個辦公環節,Google Workspace Studio 正是打造無程式碼自動化工作流程(Agentic Workflow)的終極指揮中心。透過自訂觸發器與提示詞,一般員工能輕鬆串聯 Gemini 的創造力與 NotebookLM 的深度分析能力。例如,Gmail 收到特定客戶郵件時,自動做跨文件重點摘要、擬定回覆草稿,或是在會議前主動派發簡報精華,有效降低日常繁雜作業,讓 AI 真正成為主動執行任務的數位戰友。
Google Cloud AI 加速日的豐富內容可觀察到,Google Cloud 相當重視企業 AI 轉型的需求,並針對不同工作職務、場景及流程,提供相對應的 AI Agent 工具與資源。正如 Google 暨 Alphabet 執行長 Sundar Pichai 曾說:「我們現在目睹 AI 帶來的轉變,將會是我們一生中最深遠的變革,遠大於之前行動裝置或網路所帶來的轉變。」在這場智慧競爭新局之中,越早將 AI 戰力規模化落地的企業,越能以無可取代的效率與創新體驗,在全球市場築起一道堅不可摧的營運護城河。

过去两年,我们每天都在做同一件事:学习和进修「提示词工程」这门玄学。
找 AI 干活,总要像个碎碎念的甲方一样,交代八百字背景,像是在哄一个智商奇高、但每天都会间歇性失忆的实习生。
这让我想起在游戏里,施展出必杀技之前,总是会有一个类似「前摇」或者「吟唱」的过程。某种程度上,写提示词,提供上下文,上传各种文件等等……就是使用 AI 的「前摇」。
不是说用户每次都要做到极致,只是如果你能给足这些前置条件的话,AI 会做的更好。
不过,前段时间 APPSO 在中关村的一场线下聚会看到了一个还在测试中的 AI 办公产品——它很大程度上摒弃了对「前摇」的依赖。
产品名字叫 Floatboat。

Floatboat 的联合创始人兼 CEO 少卿走到台上,打开 Floatboat,选中一个文件夹,里有一个 CSV 表格,是一份参加本次活动的嘉宾名单。他在旁边的 AI 对话框里说了一句:生成邀请函。
过了一会,每位嘉宾的邀请函都出现了。
到这里为止都还好,把表格丢给 ChatGPT、Claude、WorkBuddy、悟空………任何一个今天的 AI,写一句指令,大概率也能做到差不多的事情——但接下来发生的,让我愣了一下。
有一位新嘉宾确认出席了,少卿说,「在表里更新一下」。
CSV 更新了;紧接着,一封新的邀请函也自动生成了。
我坐在那里花了两秒钟,试图理解刚刚发生了什么:
Floatboat 它知道这份表格和邀请函之间,知道「更新表格」和「生成邀请函」两个动作之间,是有关系的。所以少卿只说了前半句,后半句没说出来,它自己悟出来了。
AI 不再是等待指令的工具,变得越来越积极、主动,会动脑子,像一个一直给你打下手的小朋友,你说「更新一下」,他知道你的意思。
这个瞬间让我开始认真看这个产品。

Floatboat 是什么?我试着给它一个定义,发现很困难。
它有一个长得像 macOS Finder 的文件管理器,你可以浏览本地文件、打开 iCloud Drive;文件格式支持得很全,Markdown、CSV、Excel、Word、图片、视频,都能直接预览,甚至编辑;
它有一个内置浏览器,可以打开任何网页,甚至可以让 Agent 去操作这些网页;
它有一个 AI 对话界面,底层可以接 Gemini 或其他模型。这么看来它有点像 Claude 的桌面端,但又比 Cowork 多一些更直观的操作逻辑。

这三个东西,文件、浏览器、对话,以面板的形式并排在一起,可以随意拖拽组合,最多四栏并排。
你在浏览器里看到一张有用的图,可以直接拖到本地文件夹里保存;你让 AI 生成了一份报告,报告会直接写入本地文件,以 .md 或 .docx 格式保存,并且你可以直接编辑这些文件,不需要 cmd-c 再 cmd-v 到另一个地方。
信息从各个方向流进这个环境里,加工过的内容也能流出去,不会被锁死在某一个面板里。
所以 Floatboat 到底是什么?是文件管理器?是浏览器?是 AI 聊天工具?是氛围编程环境?
它都是,又不完全是。
在 Floatboat 出现之前,我们其实一直在做不同软件之间的「人肉 API」,每天按几百次复制粘贴,打开不同的软件或浏览器窗口、编辑不同的文件。
在 AI 世代在线办公的我们,成了在窗口与窗口之间疲于奔命的赛博搬运工。
而 Floatboat 打破了软件之间的墙,让所有的窗口都能共享同一份上下文。

开发团队给产品的定义是「工作环境」而非「AI 助手」。助手是你要求它才动的,工作环境是一直在那里的,你在里面做事,它一边帮你做事一边观察和学习。
在沟通会上,有人问少卿:一句话形容你们的产品?
少卿反问:你能一句话形容 ChatGPT 吗?
大家会心一笑。我觉得他说的有道理。有些东西确实不是一句话能装下的,除非你做的是一个非常垂直的工具。Floatboat 显然不打算做垂直。
做科技记者这些年,我经历过好几代这样的产品。最早是电子邮件加 Office 套件的时代,后来是各种 OA 系统,再后来钉钉来了、飞书来了、Slack 来了。
每一代都有一个产品,或者一类产品,它们有着同一句潜台词,对你发出强有力的暗示或者明示:上班,用我就够了。
而在 AI 时代,Floatboat 想要成为这个角色。
这么说不是在拔高它。恰恰相反,这个位置历史上从来没有人真正坐稳过。飞书解决了团队协同,但文档操作仍然需要 Office 套件。钉钉把审批这个工作做到了极致,但打工人私下用微信聊工作的习惯从来没变过。
「一统江湖」这件事,每一代都有产品在尝试,但从来没人真的实现过。
原因是结构性的:这类产品想要成功,需要整个组织一起换过来。而组织的惯性,是所有惯性里面最大的。你一个人觉得飞书好没用,你的团队、你的客户、你的供应商都得觉得好才行。
Floatboat 的策略有一个不同:它不面向组织,它面向个人。
这个产品的目标人群,也正是时下最流行的概念:OPC,全称 One Person Company/一人公司。
过去一年 AI 能力的跃进,让 OPC 这个前两年的口号,逐渐变得越来越现实和可行。一个人,加上三五个 agent, 几乎可以对等一个小的草创阶段的业务和支持团队。无论是自媒体内容创作者,从选题到写稿到排版到分发,还是电商业务,从选品到上架到客服到投流,都已经够用了。
Floatboat 希望能够打动这群人。在 APPSO 的体验中,我们测试了包括内容创作、数据科学等场景,也测试了外部工具接入(例如 Slackbot)等多种场景。对于内容、营销、数据分析、客服等类型的工作,Floatboat 都达到了我们的期待。

现在 AI 产品有两种设计哲学。一种是「你放手,我来」,把用户推到后座上去,Agent 全权接管,跑完了给你看结果。另一种是「你干活,我在旁边」,成为用户的副驾,在适当的时候递工具、提建议。
Floatboat 更接近后者,但又不全是。用 Floatboat 工作,我的体验是:跟 AI 在主驾副驾之间来回切换,畅快自如。
用了一段时间之后,我觉得 Floatboat 的主张是行得通的。至少在现在这个阶段,大多数人对 AI 的信任还没到「你尽管干,我不用看」的程度。你让一个打工人把整份方案交给 AI 自己跑,他会焦虑的睡不着觉……
但如果 AI 是在他的屏幕上、在他的文件夹旁边干活,他看得见过程,能随时纠正,那他会比较安心。
这也是为什么 Floatboat 的界面设计那么像一台传统电脑的桌面,把文件管理器、对话框、浏览器/编辑器都拉出来让你一览无遗:已经认识的东西,能够降低用户对一个新事物的戒备心,提高接受度。

然后再说 Floatboat 做的一个叫 Combo 的功能。
Combo 可以是一个复杂的 skill,也可以是多个 skill 的组合。而在工作的逻辑里,就是把一套工作流打包成一个可复用的操作。
Floatboat 内置了从工作成果中「蒸馏」 combo 的能力——这其实很像 Anthropic 官方的 skill-creator(本身也是一个 skill)。
比如你每周都要做一件事:从网上抓几篇行业报告,提炼摘要,整理成 Markdown 文档,然后推送到 Notion。你第一次在 Floatboat 里手动跟 Agent 对话完成了这套流程之后,对话框下方会出现一个按钮,问你要不要把这轮操作存成一个 Combo。
或者你也可以主动跟 Floatboat 说,「把我们目前的工作里面的方式、思考、逻辑,整理为一个 skill」。

当下次遇到类似任务的时候,Floatboat 会自动把这个 Combo 推荐给你,一键启动。
这里面我觉得最有意思的一点是:你不需要事先「设计」工作流,只需要正常干活就行了。一边干着,一边 Floatboat 就会自己把你的工作习惯、操作方法等「蒸馏」出来,沉淀出一份指导思想。
少卿告诉 APPSO,Combo 能力的设计,是为了实现今天的绝大部分用户对于 agent 产品的那个核心期待:自进化。
「当 agent 能够感知你 80% 的操作的时候,它就有自进化的能力了」,Combo 的自动沉淀机制就是在做这件事的第一步。
兜售「提示词」的时代,快要结束了。你不再需要像个魔法师一样去背诵枯燥的咒语,把提示词保存在一个专门的文件夹或者 AI 工具的后台。通过 Combo,Floatboat 可以让用户把他们每天最经常做的固定动作,提炼成独属于自己的「手艺」和数字资产。

当然,Floatboat 也做了一个 Combo 市场,你做的好用的 Combo 可以上传,别人做的也可以下载。官方也提供了一些现成的。

但这个 Combo 体系仍有不足。
任何一个号称能够一统江湖的办公软件,号称「越用越懂你」的 AI 系统,都仍然存在冷启动的障碍:就好比 Google Docs 的初始简历模板虽然很全很好,但仍然需要每一个求职者去调整修改以适合自己。
Combo 的自动沉淀机制,逻辑上是说得通的:你用得越多,它学得越好,推荐的工作流越贴合你。但这有一个前提:你需要先投入时间从零教它,而大多数人没有这个耐心,他们希望拿来就能用。
作为一位媒体编辑,我的日常工作是阅读大量资料、跟作者沟通选题、改稿子、偶尔自己写长文。这些工作的颗粒度很细,上下文很碎,跟官方预设的那些模板(更偏向标准化的报告生成、数据整理之类)对不上。
在我的具体使用中,我将几种不同的内容生产路径保存成了不同的 Combo:针对外部新闻的快速反应是一种,基于采访 Q&A 提纲的撰写是一种,针对复杂课题的调研、资料的编排、然后进行原创写作,又是另一种。
当然,这不是 Combo 本身的问题。对于绝大多数人,无论他们的工作是文档写作、报表处理、ppt 写作,还是数据整理、行政工作,甚至更加复杂的「一人开发者+marketer+客服」,无论是自己生产 Combo,还是在 Floatboat 的官方 combo 基础上做微调,都足够好用。
AI 工具不是一切工作的万灵药——一个工具把自己宣传得再美好,今天的用户也应该有这样的觉悟。对于 Floatboat,正如前面所说的,它是「工作环境」,它的能力足以强化人,但它的工作效果仍然取决于人。
然后再说说用 Floatboat 和其他「类 Cowork」产品的区别:最大的明显感受,是 Floatboat 的工作流程很快。以文件操作、内容生成为例,在 Gemini 3.1 Pro 模型驱动下的 Floatboat,对文件进行操作(批量重命名/修改格式、填充 markdown 等)的用时,是我平时用 Cowork/Claude Code CLI 的三分之一左右。
Gemini 在「讨好用户」上也是老演员了,所以最近 Floatboat 也加入了 Claude 两个最新版模型,Sonnet 和 Opus 4.6 的支持。
Gemini 对于 Floatboat 主打的大多数办公场景(文案生成、表格处理、信息整理)来说够用,写作效果也还算不错;如果不符合你偏好的话,切到 Claude 模型也没问题。如果你注意到 Floatboat 的迎合意图太强,可以在工作过程中时不时强调一下,不要一味迎合,要对生成的结果,甚至用户的输入做批判性的思考。
以及,你也可以充分利用 Combo 生成的功能,将这些技巧写进 Floatboat 的核心指导思想。

另外一个小设计值得提一句:Floatboat 可以集成到飞书和 Telegram 里,你不打开它的客户端,直接在聊天工具里给它发消息,它就在后台帮你执行任务——这个功能叫 Claw 模式,相信足够你顾名思义了。

除了产品本身,Floatboat 团队还在做一件更远的事。
他们开源了一个协议叫 Selfware,核心理念用一句话说就是:A file is an app。
这是什么意思?现在你用 AI 辛辛苦苦做了一份调研报告,发给同事,他收到的是一个 Word 文档或者 .md 文件。文件里有最终结果,但你当时调用了哪些资料、AI 跑了什么逻辑、中间修改了几次、为什么改,这些对于工作最关键的经验,并没有被保存下来。
Selfware 想解决的就是这件事。一个 .self 格式的文件,里面不只有数据,还携带逻辑和结构。你的同事收到之后,可以直接打开、继续编辑、让 Agent 沿着你的思路往下跑。文件自带了工作环境。

这个想法,和目前 AI 开发圈里对 CLAUDE/SKILL.md、cursor rules 这类文件的热情, 属于同一个潮流。大家都在发现,文本文件可以用来「编程」AI 的行为,一个 .md 文件可以定义一个 Agent 的人格、工作方式、输出风格。
但 Selfware 往前又多走了一步:那些 .md 文件是指令,你告诉 Agent 怎么做;Selfware 想做执行单元,文件本身就能运行,而且不依赖于特定平台。
这其实有点像 Jupyter Notebook,把代码、数据、输出打包在一起了;也类似于 Docker,把运行环境做成了可分发的单元——Selfware 把场景换成了 Agent 协作。它不是从零发明的概念,但在 Agent 时代重新提出,确实切中了一个真实的痛点。
不过,协议这种东西,最终看的是采用率。现在 Selfware 主要在 Floatboat 自己的生态里运转。「A file is an app」是个有趣的理念,但从理念到被广泛采用的标准,中间路还很远。

另外值得提一句的是 IACT (Inline Action-Clicked Text),Floatboat 开源的另一个协议。它做的事情更小但很实际:在 Markdown 语法的基础上,直接在 AI 对话生成结果加上可点击的行内 (in-line) 链接/按钮。生成结果中的「可行动内容」将会自动套上这个按钮,用户直接点击就行了。
这个交互改进看着不起眼,用起来确实减少了摩擦。最早做类似体验的应该是 Claude,但 Claude 的很多「好东西」都是闭源的。Floatboat 把 IACT 开源,让其它产品也可以充分利用。
现在一些同类产品比如 WorkBuddy 也在做类似的东西了,但据我了解 Floatboat 是最先提出这个概念并把它协议化的。

工作起来,开心最重要
Floatboat 的名字来自一句英语俗语,whatever floats your boat,大概的意思是「你开心就好」。
少卿说,他们希望产品给人一种在 AI 时代悬浮起来的感觉,不被裹挟着走。
这个愿景挺好的。但 Floatboat 能不能成为这个时代的那个「用我就够了」的产品?老实讲,APPSO 仍然没法给出一个明确的判断。
毕竟大家都看到了:每一代尝试做这件事的办公产品,到了最后,多半成为了工具箱里的工具之一,而非唯一。
但今天下判断,也为时尚早。
一个产品不需要统一所有人的工作方式才算成功。如果它能让一部分人——那些一个人干五个人的活、每天在软件之间当搬运工的「OPC」们,每天省出一个小时来做真正需要动脑子的事,那它就已经值得存在了。
对大多数普通人来说,一家公司的活如果全都一个人干,确实挺累的。
但 Floatboat 让人兴奋的地方在于,它给了一个人也可以是一家公司的从容和底气。
不是所有人都能 OPC,你至少首先需要台好「PC」。而 Floatboat 赌的,就是自己会成为那台 PC。
#欢迎关注爱范儿官方微信公众号:爱范儿(微信号:ifanr),更多精彩内容第一时间为您奉上。

99 年生的张舒昱,是腾讯电脑管家团队入职不久的产品经理,这在腾讯算不上核心业务线。
今年 1 月 OpenClaw 刚在中国爆火,她着了迷,拉上几个人攒了一个产品原型 QClaw:基于 OpenClaw,一键安装,通过微信直接操控智能体。
项目在腾讯体系里几乎没有存在感,没有立项审批,没有总办资源,几个年轻人凑在一起写代码。
3 月 9 日,QClaw 内测上线。一周之内,数百万用户注册。

然后事情开始失控,惊动了腾讯总办。
高层反应极快,随即调拨数十名员工和计算资源到张舒昱的团队。同日,另一支团队推出了 WorkBuddy,同样兼容 OpenClaw。再隔一天,腾讯港股大涨超过 7%,投资者把涨幅直接归因于这两只虾。
3 月 11 日凌晨 2:06,马化腾发了条朋友圈:「自研龙虾、本地虾、云端虾、企业虾、云桌面虾,安全隔离虾房、云保安、知识库……还有一批产品陆续赶来。」

这对腾讯 11 万员工是一个鲜明的信号,无数员工将其解读为:Pony 支持他们 all in 龙虾。
据 The Information 独家报道,截至本月,腾讯内部同时有 8 个团队在开发基于 OpenClaw 的产品和服务。加上在研和内测项目,总数已超过 10 个。
15 年前,腾讯内部三个团队赛跑移动 IM,张小龙的广州研发部跑出了微信,是腾讯史上赛马最成功的一次。这次换了个物种,叫赛虾。
一个 99 年产品经理做的边缘项目,两周之内变成一家万亿市值公司的战略支点,似乎有点不可思议。
张舒昱对 The Information 说了一句大实话:「我们都在用 AI Agent 做实验。此刻,没有人能说什么是最佳方法。」
翻译一下就是:我们也不知道答案,但先跑起来总比站着强。

要理解腾讯对龙虾的狂热,先要直面鹅厂当下在 AI 竞争中的处境。
过去两年,中国 AI 大模型军备竞赛打得昏天暗地。
阿里砸钱做千问,字节孵出豆包,在用户规模和模型能力上都拉开了身位。腾讯呢?手握游戏和微信广告的丰厚利润,但在 AI 赛道上远不及这两个对手激进。
自研的混元大模型尚且无法与竞争对手匹敌,又拖累了自家 AI 助手「元宝」的进展。
腾讯不是没努力。去年请来前 OpenAI 研究员姚顺雨执掌混元研究,重建了研发基础设施。 4 月即将发布的混元新一代模型,业内普遍视为腾讯模型能力的一次摸底考试。

▲姚顺雨. 图片来自:智源社区
但远水解不了近渴,在新模型交卷之前,缺乏强大的内部模型,让元宝在与豆包和千问的竞争中暂时落于下风。
所以当 OpenClaw 在中国引爆了 Agent 热潮,腾讯高层几乎是本能地抓住了这根绳子。这只龙虾证明了 AI 的下一个爆发点未必在聊天框里,可能在桌面上,在工具里,在无数个能替你干活的智能体身上。
腾讯高层的判断很清晰: OpenClaw 引发的这一轮 Agent 浪潮,将是 AI 战场重新洗牌的机会。
他们逻辑是这样的,如果腾讯能通过将 OpenClaw 类Agent 能力与微信深度整合,提供配套工具和服务,成为中国最好的 Agent 使用平台,那么即便其内部大模型不是最强大的、AI助手也不是最受欢迎的,腾讯依然有可能在 AI 下半场逆风翻盘。
2020 年,马化腾在腾讯内部将视频号称为「全村的希望」,寄望于它在短视频赛道上扳回一城。如今,「全村的希望」换了物种。
区别在于,视频号好歹是亲生的,龙虾来自一个奥地利独立开发者的 GitHub 。
某种意义上,这更像是 2014 年纳德拉接手微软后做做的事,承认在移动互联网上输了,放下「什么都要自己做」的控制欲,押注一条全新赛道。
纳德拉用了十年,腾讯希望快一点。
外界把多团队并行理解为经典赛马机制,腾讯内部更愿意说「多样性」。QClaw 和 WorkBuddy 是最先冒头的两只虾,路线截然不同。
QClaw 是张舒昱从电脑管家边缘团队杀出来的,直接拥抱 OpenClaw 开源生态,做微信一键安装,野蛮生长。设计理念就四个字:打开即用。不需要配置环境,不需要懂终端命令,微信扫一下就能让 AI 接管你的电脑。

▲张舒昱. 图片来自:南京审计大学
WorkBuddy 则走了一条完全不同的路。负责人汪晟杰在接受 APPSO 采访时反复强调一件事:百分百自研,没用过一行 OpenClaw 源码。
它走半自动化路线,避开了 OpenClaw「透传」模式下信息暴露在公网上的风险,采用 bot 推送通知模型,每一步关键操作都需要用户确认。汪晟杰的定义很明确:龙虾是一个概念,不等于 OpenClaw。WorkBuddy 要做的是安全可控的龙虾,企业能放心用的龙虾。
汪晟杰透露了一个时间细节:WorkBuddy 在 1 月 17 号那个周末就已启动,三四个人通宵做出 MVP(最小化可行产品),原计划 3 月 16 日发布。看到龙虾热潮后提前了一周,撞上了 QClaw 同期发布。

▲ 汪晟杰.
也就是说,腾讯并非在 OpenClaw 火了之后才匆忙跟进。多个团队在不同时间点嗅到了同一个机会,OpenClaw 的爆火更像催化剂,把水面下的项目一夜之间推上了前台。
但赛虾机制的矛盾也摆在桌上。
QClaw 和 WorkBuddy 功能高度重叠,都能通过微信操控 AI 智能体,用户该选哪个?8 支团队同时跑,资源会不会内耗?
答案藏在张舒昱那句话里:「此刻没人知道什么是最佳方法。」8 支团队同时下场,与其说是信心爆棚,不如说谁都没有把握。
腾讯选择用数量对冲不确定性,多条路线同时跑,押中一条就够了。
赛马机制的精髓从来都是:靠数量提高命中概率。15 年前微信就是这么跑出来的。

赛虾的前提是有虾可赛,但这只虾不归腾讯管。
3 月 12 日,OpenClaw 创始人 Peter Steinberger 在 X 上公开批评腾讯,矛头直指腾讯的 SkillHub 服务复制了社区 Skills 却没有做出任何贡献。
两天后,腾讯通过 GitHub 捐款,随后被列为特色赞助商,与 OpenAI 并列。在上周英伟达 GTC 大会上,腾讯云 CEO 汤道生当面约见 Steinberger,提出由腾讯云贡献服务器和安全服务,并探讨与 OpenClaw 基金会更深层的合作。

中国市值最高的互联网公司之一的高级副总裁,飞到圣何塞跟一个开源项目创始人坐下来谈合作。在腾讯历史上几乎没有先例。当你需要别人的东西比别人需要你的东西更急迫时,身段自然就放下来了。
同一周的财报发布会上,腾讯总裁刘炽平宣布 2026 年将 AI 新产品的投资至少翻倍,从去年的 180 亿元起步。而在阐述钱花到哪里时,他只点了三个名字:混元、元宝、以及最新的 Claw 产品。
一个月前还是边缘项目的龙虾,一跃与腾讯自研大模型和旗舰 AI 应用并列。龙虾从「大家自己玩玩」正式升格为「公司战略」。
马化腾最近在财报会议上的发言,进一步回答了一个更本质的问题:腾讯想用龙虾做什么?
他的切入角度直接跳过了产品层面,落在生态上。
马化腾认为龙虾类应用有记忆和个性,更像助理,带有「活人感」,能让 AI 落地到办公、终端、小程序等各种场景中,不再全部挤在 chatbot 这条独木桥上。
但真正耐人寻味的是他关于「去中心化」的论述。微信本身是中心化的 App,但微信生态是去中心化的,数十万小程序商家构成了开放平台。马化腾认为 AI Agent 天然具有去中心化特征,可以融入微信生态。有一句话特别关键:
所有服务商的心态都是怕被 AI 智能体「短路化」「渠道化」。
意思是,他不想让 AI Agent 变成一个新的中间商,把微信里的服务商变成纯粹的后端 API。他想让小程序保留独立性,同时具备 AI 能力。「每一个小程序都可以智能化和龙虾化。」
这个思考比「我们也做龙虾」高出一个维度。马化腾看到的是一种范式转移的可能:AI 的价值分配方式,从「一个超级 chatbot 统治一切」变成「无数分布式智能体各显神通」。
如果这个判断成立,拥有全球最大通讯生态和最活跃小程序平台的微信,天然就是 Agent 时代最肥沃的土壤。
刘炽平在财报会上把这套逻辑做了明确的总结:「Claw 提出了一种去中心化的模型……有段时间,似乎每个人都在争夺成为 AI 智能体唯一的入口和垄断者。但现实并非如此。」
一句话概括腾腾讯的押注逻辑:模型之争输了一局,但生态之争的牌还没摊开。
当然,这套叙事也可以被翻译成另一句话:我们模型不够强,所以告诉你们模型没那么重要。
自洽和自欺之间,有时候只隔一层窗户纸。但关键在于,这一次腾讯确实有牌可打。微信不需要成为最强大模型的容器,只需要成为最好用的 Agent 运行环境。
这和纳德拉的 Azure 逻辑如出一辙,你不需要自己做出最好的 AI,你只需要让最好的 AI 都跑在你的云上。
腾讯的「养虾」远不止做几个 C 端产品那么简单。腾讯周五公布了「养虾产品全景图」,这套从底层到应用层的完整龙虾矩阵,密度超出外界预期。

消费级产品打头阵。QClaw 主打微信一键安装,面向普通用户;WorkBuddy 走桌面端自研路线,强调安全可控;微信 ClawBot 负责让用户在微信聊天界面直接操控龙虾。
三个产品覆盖了「小白用户一键上手」「桌面深度使用」「微信生态无缝接入」三个核心场景。光是消费级这一层,腾讯就同时铺了三条路。
企业级产品紧随其后。ClawPro 面向企业和政务客户,主打安全隔离和精细权限管控,企业微信独占通道,账号权限分级,内置技能审核机制,代码生成类操作要过审,网页搜索走安全网关。
汤道生在腾讯云峰会上重点推介了 ADP(智能体开发平台),定位是企业构建定制化 Agent 的工具箱。配合 Claw Runtime 提供安全沙箱运行环境,Lighthouse 做安全管理。
整套企业方案的逻辑很清晰:OpenClaw 太野了,我帮你把它关进笼子里。
开发者生态也没落下。CodeBuddy 是去年下半年就上线的 AI 编程助手,现在被纳入龙虾矩阵成为开发者入口;SkillHub 是 AI 技能社区,做了本土化适配,也正是因为这个产品被 Steinberger 点名批评后才有了后面那笔捐款。TokenHub 则是模型服务市场,不光接混元,也接 DeepSeek、MiniMax、Kimi 等第三方模型,统一计费。
腾讯连「卖铲子」的生意都想好了。
从这张全景图可以看出,腾讯不想只在产品上做单点突破,要做一整条龙虾产业链——从安装到运行,从个人到企业,从消费到开发,每个环节都有人盯着。
这正是汤道生反复强调的「Harness 工程」思路:Agent 时代的胜负手不在模型本身,在于脚手架。工具调用、上下文工程、长期记忆管理、工作流设计,这些看起来不性感的苦活,才是决定 Agent 好不好用的关键变量。
汤道生在腾讯云上海峰会上表示:「AI 落地不只是算法题,Harness 工程能力是关键变量。不同的脚手架设计,会显著影响实际使用效果和 token 成本。」
翻译成人话就是:模型是发动机,但没有底盘和方向盘,跑不了多远。腾讯模型暂时跑不过别人,但如果能把底盘和方向盘做到最好,照样能赢。
把所有线索串起来,这个故事可以被浓缩成一句话:腾讯用一家大公司能调动的所有资源,去拥抱了一个自己无法控制的开源项目。
这是一个充满张力的姿态。
OpenClaw 的更新节奏是每周两三个版本,API 说改就改,Breaking Changes 说来就来。Peter 点一下 merge,深圳大厦里好几支产品团队可能就要通宵救火。腾讯把战略命脉系于别人的 GitHub 仓库上,这需要的不只是勇气,还有一种前所未有的谦逊。
但换个角度想,腾讯可能也没有更好的选择了。
如果继续只在模型和 chatbot 赛道上硬碰硬,不是陪跑就是陷入同质化厮杀。但 Agent 浪潮撕开了一条新缝隙:谁能把 AI 变成最好用的工具,谁就能重新定义入口。
微信有 14 亿月活,有小程序生态,有支付,有社交关系链。这些东西造不出最强模型,但能造出最好的 Agent 使用环境,这是腾讯手里唯一一张别人没有的牌。
问题在于,这张牌的有效期有多长。
OpenClaw 仍在快速迭代,生态远未定型。今天的龙虾热,会不会像去年的 Manus 一样来得快去得也快?8 支团队赛虾,会跑出下一个微信,还是跑出 8 个半成品?马化腾的「去中心化 Agent 生态」蓝图很美,但从蓝图到现实之间,还有需要经历多少次「技术事故」?
不过,有一件事是确定的。
当一家公司的 CEO 凌晨两点发朋友圈,总裁在财报会上把龙虾和自研模型并列,高级副总裁飞到美国去约见开源项目创始人,8 支团队同时下场赛虾,AI 投资直接翻倍,它就已经不是在追热点了,它在押注这家公司的未来。
赌的不是这只虾能活多久。赌的是在 AI 重构一切的十年里,腾讯还能不能坐在牌桌上,以及坐在什么位置。
视频号当年也被叫做「全村的希望」。五年过去了,它还没打败抖音,但在微信生态内长出了自己的活法。龙虾能不能也走出第三条路?答案还早。
不过,当一个巨头被逼到墙角,终于想清楚自己要什么,把资源砸向同一个方向的时候,你永远不能低估它。
#欢迎关注爱范儿官方微信公众号:爱范儿(微信号:ifanr),更多精彩内容第一时间为您奉上。

Salesforce 台灣服務客戶突破 1000 家,宣布將透過 Agentforce 平台協助企業實現「智動化企業」,同時計劃申請設置台灣在地資料中心。
2026年對Salesforce台灣而言,是深耕在地市場的重要里程碑。在總經理徐嘉聲的帶領下,Salesforce在台服務規模正式突破1000家企業,客戶群目前以製造業、服務業為大宗,同時也涵蓋了對資安要求極為嚴苛的金融業者。面對生成式AI帶來的產業巨變,Salesforce宣佈將進一步結合專業在地團隊與涵蓋16種產業的Agentforce解決方案,提升企業韌性與敏捷度為核心,全力協助台灣各種規模的企業加速邁向「智動化企業」 (Agentic Enterprise)的新紀元。
「智動化企業」重塑營運:人才與AI代理的無縫協作
Salesforce定義全新的企業運作模式——「智動化企業」,並非單純導入AI工具,而是透過深度整合「數據、AI與人才」,讓各規模企業都能實現360度的全方位協作。
在智動化的架構下,人類智慧將與代理式AI (Agentic AI)緊密並肩作戰。Salesforce觀察到,目前企業端對於AI代理的應用比例與接受度已經相當高。AI將接手繁瑣的流程,賦能員工將精力專注於具備更高策略價值的工作上,進而讓每一次的客戶互動都更具深度與品質。
此外,透過自然語言介面,企業員工現在能更直覺、輕鬆地驅動複雜流程與撈取數據洞察,讓AI真正轉化為日常作業的內生動力。在優化跨部門流程、降低營運成本的同時,企業也能仰賴Salesforce完善的資安與治理機制,確保AI應用符合法規,大幅降低潛在風險。
 ▲Salesforce定義全新的企業運作模式——「智動化企業」,並非單純導入AI工具,而是透過深度整合「數據、AI與人才」,讓各規模企業都能實現360度的全方位協作
▲Salesforce定義全新的企業運作模式——「智動化企業」,並非單純導入AI工具,而是透過深度整合「數據、AI與人才」,讓各規模企業都能實現360度的全方位協作
借鏡日本經驗與在地化佈局:雙軌銷售與客製化技術支援
為了更貼近台灣企業的實際需求,Salesforce的在地化營運戰略上也做出了明確梳理。
在組織架構上,Salesforce台灣目前隸屬於日本分公司管轄範圍。這項編制為台灣帶來了一大戰略優勢:台灣團隊能夠大量借鏡日本市場在AI應用與數位轉型上的成熟經驗,並且將其靈活推廣至台灣市場 (當然,這些經驗都將經過深度的在地化調整,而非生搬硬套的直接複製)。
在團隊建置方面,Salesforce在台灣已經佈署完整的業務與技術陣容。在銷售通路上,採取「業務直接銷售」與「透過合作夥伴銷售」的雙軌並行模式,以擴大市場觸角;而專屬的技術人員則專注於針對不同產業客戶的特殊痛點,提供深度的客製化技術服務。
 ▲Salesforce台灣總經理徐嘉聲
▲Salesforce台灣總經理徐嘉聲
基礎設施再升級:計畫向總部申請「台灣在地資料中心」
除了軟體平台的推進,基礎設施的佈局也是本次亮點。目前Salesforce台灣客戶主要使用的是位於日本與新加坡的資料中心;考量到台灣金融業與高科技製造業對於「資料落地」與「最高合規性」的強烈剛性需求,Salesforce台灣團隊透露,接下來計畫向全球總部正式申請啟用「台灣在地資料中心」,期望未來能為在地企業提供更低延遲、更符合法規限制的雲端運算環境。
 ▲Salesforce計畫向全球總部正式申請啟用「台灣在地資料中心」,期望未來能為在地企業提供更低延遲、更符合法規限制的雲端運算環境
▲Salesforce計畫向全球總部正式申請啟用「台灣在地資料中心」,期望未來能為在地企業提供更低延遲、更符合法規限制的雲端運算環境
連續12年蟬聯AI CRM榜首,Agentforce四層架構拆解
為實現「智動化企業」的願景,Salesforce推出了高度整合的Agentforce平台。這個平台本質上就是一個專為佈署大規模AI代理而生的「安全作業系統」,建構在嚴密的四層架構之上:
• Data 360:提供高度整合的數據、Metadata (元數據)與情境,讓AI代理能夠準確推論並採取行動。
• Customer 360:內建企業系統的業務邏輯、工作流程與治理機制,成為確保AI代理具備「企業級準確度」與「絕對合規性」的關鍵。
• Agentforce:提供建構、管理、佈署與協調AI代理的大規模實用工具。
• Engagement Layer (互動層):在通訊軟體、企業入口網等所有工作場景中,讓員工及客戶都能自然接觸到AI代理。
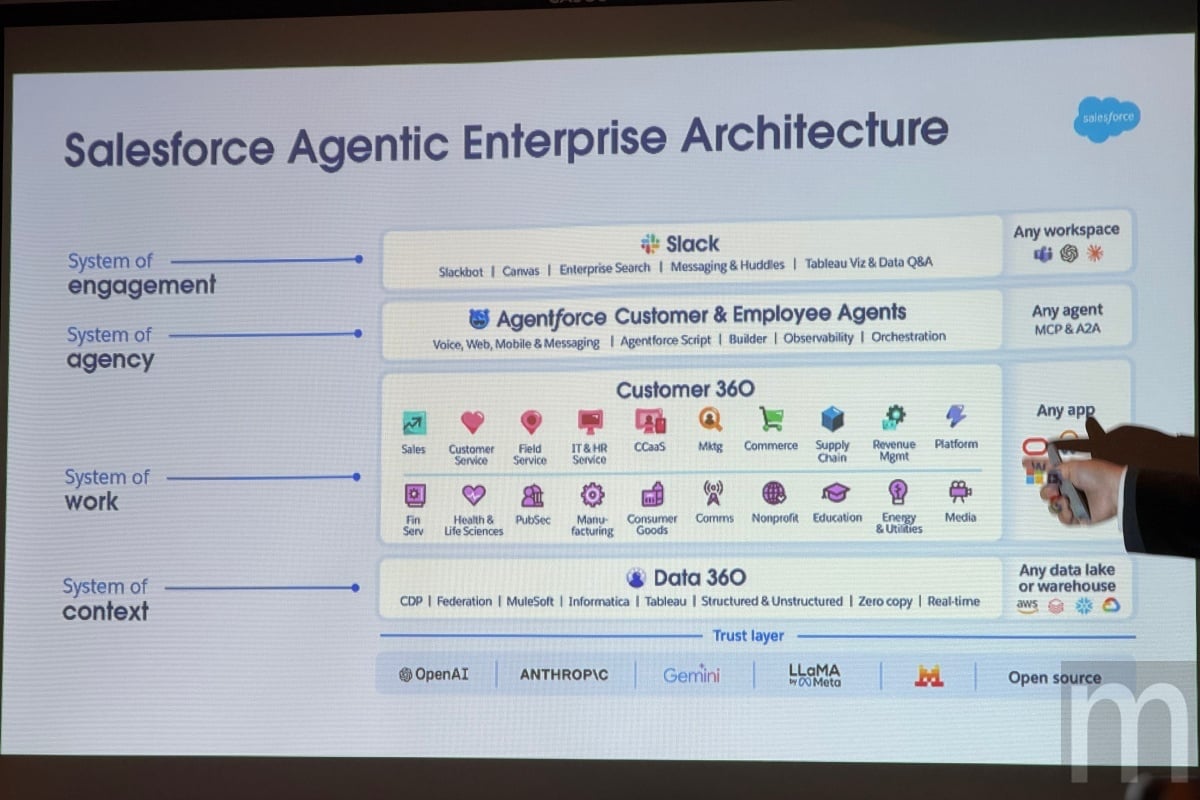 ▲為實現「智動化企業」的願景,Salesforce推出高度整合的Agentforce平台
▲為實現「智動化企業」的願景,Salesforce推出高度整合的Agentforce平台