让 Anthropic 破防的「蒸馏」风波,美国 AI 大牛泼冷水:中国 AI 成功不靠走捷径

Anthropic 昨天点名 DeepSeek、月之暗面、MiniMax 三家中国 AI 实验室「蒸馏」Claude 模型,全网炸锅。
对于此事件,RLHF (基于人类反馈的强化学习)领域最知名的研究者之一,《RLHF》一书的作者 Nathan Lambert 指出,这件事没有人们想象的那么严重,但也没有那么简单。
他认为,中国 AI 公司的基础设施非常好,取得了很多创新,也在攻克各种技术难题,但它们取得这样的结果,靠的并不是「走捷径」。
在讨论蒸馏这件事之前,先看看 Lambert 的话为什么值得听。
Nathan Lambert 是 Allen AI 研究所的科学家,博士毕业于加州大学伯克利分校,师从机器人领域的著名学者 Pieter Abbeel。他并非 RLHF 技术的发明者,但他写的《RLHF》这本开源书籍,如今是 AI 从业者理解大模型训练流程的标准参考材料之一。
和到处都是的 AI 网红不一样,他是真正上手训练过大模型的人。
在 Anthropic 博客发出的当天,Lambert 就发布了一篇详细分析文章《蒸馏对于中国大模型到底有多重要?》。他的核心论点,和主流媒体的解读方向截然不同,也比一般网友更加深入和全面。
蒸馏是什么,Anthropic 又说了什么?
首先我们来看 Anthropic 指控的核心:「蒸馏」(distillation)。
它指的是让弱模型学习强模型的输出,从而快速获得相似能力。
Anthropic 指控三家公司通过约 2.4 万个虚假账号,在违反服务条款和地区访问限制的情况下,用 Claude 生成了超过 1600 万次对话,用于训练各自的模型。
博客还附上了安全警告:非法蒸馏出来的模型可能缺失原模型的安全护栏,一旦被用于网络攻击、生物武器研发或大规模监控,后果难以预测。
Anthropic 把这套基础设施叫做「九头蛇集群」(hydra cluster)——多达数万个账号的分布式网络,流量同时分散在 Anthropic 自己的 API 和多个第三方 API 聚合平台上。
在最极端的案例里,一个代理网络同时管理超过 2 万个虚假账号,还把蒸馏流量混入普通用户请求流里,用来规避检测算法。这种网络没有单点故障,封掉一个账号,马上换一个。
海外媒体随即跟进,复述了 Anthropic 的话术。然而这套叙事逻辑很快就翻车了:毕竟「蒸馏」这件事美国 AI 公司训练的时候也会做,更何况 Anthropic 自己也有类似行为:
但 Lambert 更加冷静,他认为要先把这三家中国 AI 实验室分开来看
Lambert 指出,Anthropic 把三家公司并排列在同一篇博客里,掩盖了一个关键差异:它们做的根本不是同一件事,量级天差地别,动机也各有侧重。
按照 Anthropic 的指控,DeepSeek 的蒸馏数量最少,只有 15 万次,但手法更精准。与其直接收集答案,Anthropic 指控 DeepSeek 在做的是批量生产思维链 (chain-of-thought)训练数据。
要的不是「你得出了什么结论」,而是得到结论的过程。
但 15 万次是个什么体量?Lambert 认为,这点数据对 DeepSeek 传闻中的 V4 模型或任何模型整体训练的影响可以忽略不计,「更像是某个小团队在内部做实验,大概率连训练负责人都不知道。」

月暗的规模就不是「可以忽略」了:340 万次交互,目标集中在智能体推理、、工具调用、代码与数据分析、computer-use 开发、计算机视觉等方向——这些方向当中,大部分都是 Claude 近期最受企业客户欢迎的能力组合。
Anthropic 指出三家里流量最大的是 MiniMax,约 1300 万次,目标是代理编码、工具调用和复杂任务编排。
月暗和 MiniMax 相加约 1650 万次,按对话平均 token 量估算,总量大约在 1500 亿到 4000 亿 token 之间,折合数百到上千万美元的 token 成本。
但问题是,只盯着蒸馏看,其实有很大问题。
蒸馏的天花板在哪里?
这才是 Lambert 真正想说的部分,也是整件事里最被忽视的地方。
把强模型的输出喂给弱模型,弱模型能快速获得类似能力——这个逻辑本身成立,Lambert 没有否认。但他指出了一个没人说清楚的问题:蒸馏的天花板到底在哪里,取决于你想要的是什么类型的能力。
作为 RLHF 方面的专家,Lambert 认为,当前最顶尖的模型训练,已经高度依赖强化学习(RL)。而 RL 和蒸馏在本质上是两种不同的事情:
蒸馏是模仿,学强模型的输出,把它的「答案形状」复制过来;RL 是探索,模型必须大量自己推理、自己生成、在错误里反复迭代,从试错中提炼能力。
换言之,真正强大的模型,需要的从来不只是正确答案,而往往要靠模型自己摸索出来的解题路径,这是依靠蒸馏别人 API 的输出,得不到的东西。

以 DeepSeek 自己做的蒸馏尝试为例:基于隔壁千问蒸馏自家的 R1 模型后得到的 DeepSeek-R1-Distill-Qwen 1.5B 这个小模型,仅靠 7000 条样本和极低的计算成本,就在 AIME24 数学竞赛基准上超越了 OpenAI 的 o1-preview。
但关键在于:这个提升等多仰仗强化学习的结果,而非来自蒸馏这个行为本身。
换句话说,蒸馏能帮你更快「热身」,要真正到达顶级水平,还是得靠自己跑 RL。
不同模型之间的数据分布差异
Lambert 还指出了一个技术层面很少被外界提及的问题:不同模型之间存在微妙的数据分布差异。
把 Claude 的输出直接喂给另一个架构的模型,不一定有效,有时甚至会产生干扰。两个模型内部表征空间的差异,会让「老师」的回答在「学生」那里引发意想不到的偏差。
这意味着蒸馏从来不是「拿来用就行」的事,而是需要大量工程工作才能真正发挥效果。这本身就是一个研究课题。
这也是为什么 Lambert 将 Anthropic 所指控的「蒸馏」行为,看作是一种创新的做法,可以理解为试图攻克这一研究课题的努力。

Anthropic 的杀手锏,恰恰最难蒸馏
Anthropic 点名的三家公司,抓取的重心都落在代理行为 (agentic behavior) 这同一个方向上,包括 AI 自主规划、工具调用、分解复杂任务并逐步执行的能力等。
这是 Claude 目前最突出的方向,也是 Anthropic 最不想被复制的能力。
但 Lambert 的判断是,这些能力恰恰也是最难通过蒸馏获得的。
正如前面提到,一个强大的 AI agent,强大之处从来不在于知道或者训练过正确答案,而是「在面对没见过的情况时能自主探索出解决路径」,可以理解为一种 0-shot 或 few-shot 实现 SOTA 效果的能力。
这个过程中产生的价值,体现在推理轨迹,而推理轨迹是很难通过蒸馏习得的——至少现在是这样。
DeepSeek-R1-Distill(蒸馏模型)和 DeepSeek-R1(蒸馏对象)之间的差距,是 Lambert 论点最直接的例证。
在格式化的数学推理任务上,前者表现不错;但在需要自主探索、动态规划的复杂代理任务上,两者的差距是真实存在的。

为什么 Anthropic 现在公开说?
Lambert 有一个判断,很多人可能都有同感:这次 Anthropic 公开点名中国 AI 公司,「技术防御」压根不是首要动机。
在 Anthropic 这篇博客发出的几天前,美国国防部刚刚威胁 Anthropic 配合提供「不受限制的使用权限」,否则就将做出对后者不利的安排,比如将其标记为「供应链危险」,也即无法进入国防/政府供应商名单。
Anthropic 现在处于一个「既要又要」的两难境地:既想维持安全、不反人性的模型定位和公司形象,又不愿意错过美国政府的大单。
Lambert 指出了一个根本矛盾:美国的学术界和开源模型开发者也在做蒸馏行为,但包括 Anthropic 在内的大厂并没有对它们做出实质性的打击。如果仅因为对方是中国公司,未免地缘的意味太重了。
结果就是,Anthropic 这篇博客与其说是报告一个重大技术风险事件……其实更像是一封「投名状」。

双标
关于 Anthropic 在这件事上的立场,有一个绕不开的背景。
APPSO 在昨天的文章里也有提到:Anthropic「蒸馏」了人类最大的知识库
2024 年年初,美国某仓库里,工人们把一本本新书送进机器,切掉书脊,扫描,然后把纸送去回收。下令做这件事的是 Anthropic,项目内部代号「巴拿马」,目标是以破坏性方式扫描全球所有书籍——Anthropic不希望外界知道他们做了这件事。
2021 年,Anthropic 联合创始人 Ben Mann 在 11 天里从盗版网站 LibGen 下载了大量侵权书籍;次年,另一个公开宣称「在大多数国家故意违反版权法」的网站 Pirate Library Mirror 上线,Mann 把链接发给同事,留言:「来得正是时候!!!」
在后来的书籍版权诉讼中,Anthropic 被迫支付 15 亿美元和解金,折算下来每本书约赔 3000 美元。
斯坦福和耶鲁的研究者发现,Claude 3.7 Sonnet 在特定条件下会以 95.8% 的准确率「近乎逐字逐句」地输出《哈利波特》等受版权保护的作品——这不仅与 Anthropic 长期以来关于「模型只是学习了语言规律」的说法背道而驰,更让该公司对任何人的「蒸馏」指控显得缺乏底气。
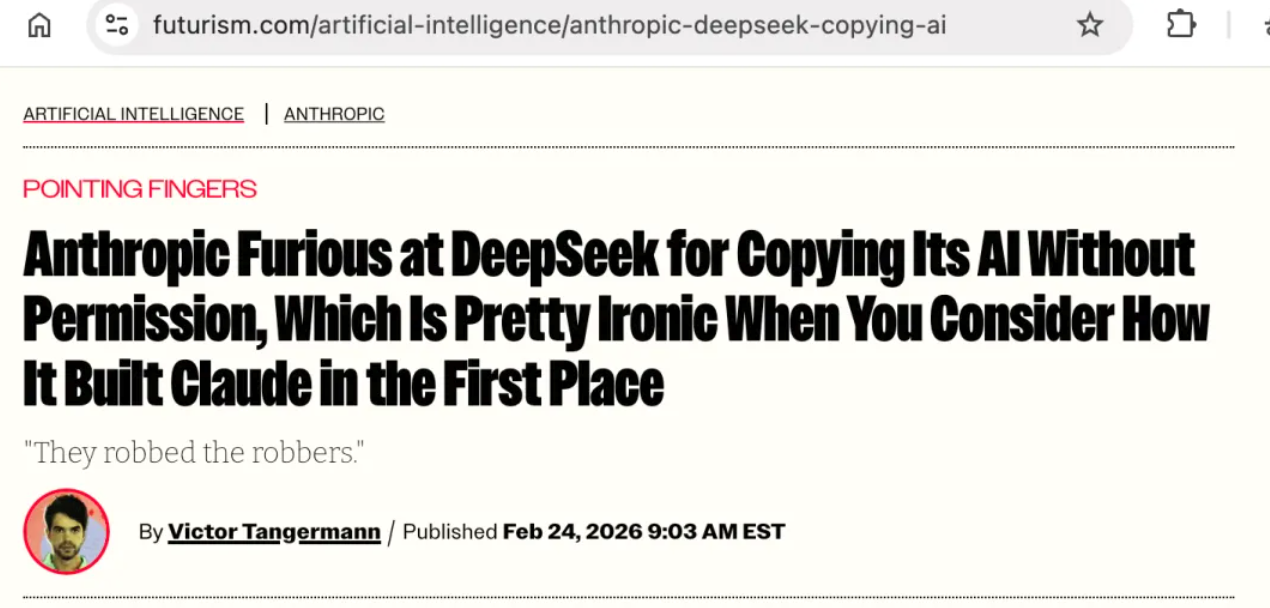
Futurism 的标题写得很直接:「Anthropic 对 DeepSeek 未经授权复制 AI 大发雷霆——考虑到它是怎么构建 Claude 的,这相当讽刺。」
Musk 在 X 上也补了一刀:「Anthropic 大规模窃取训练数据,还为此支付了数十亿美元的和解金。这是事实。」
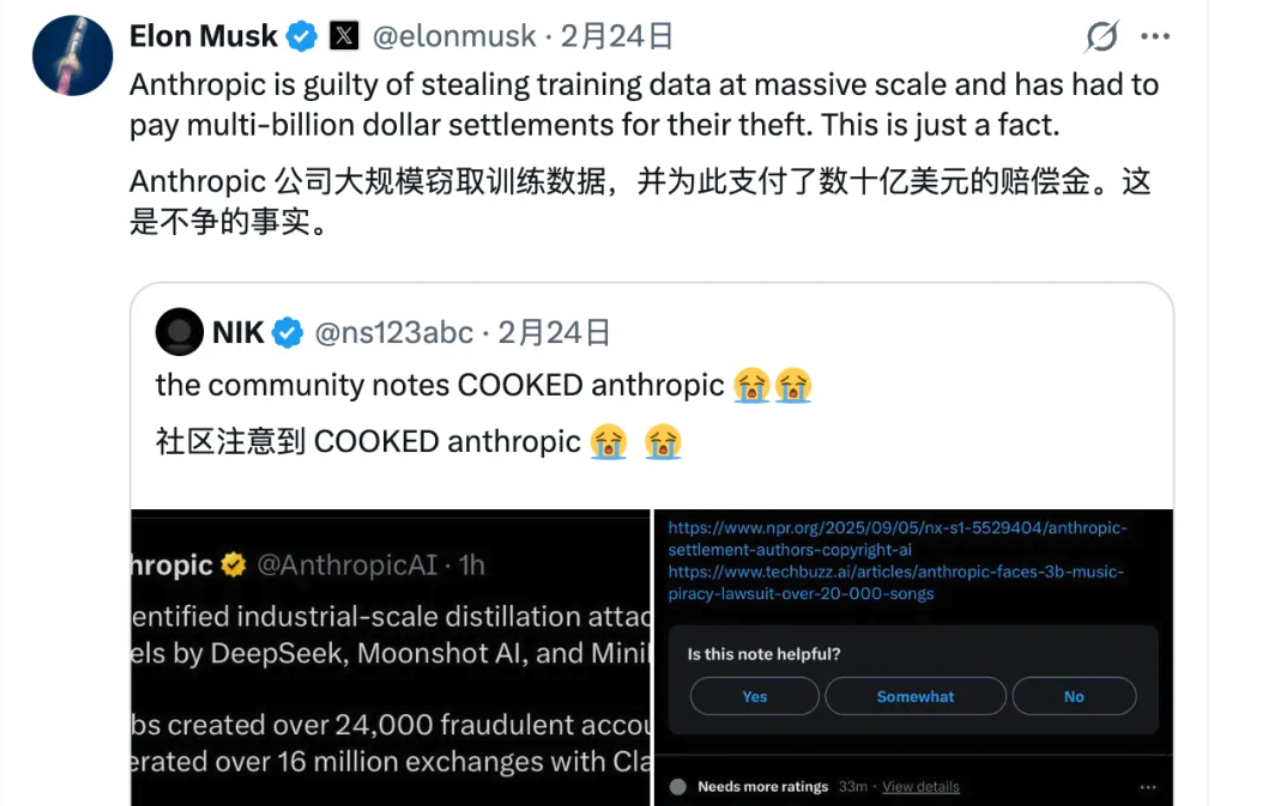
反驳者还有一个更尖锐的逻辑:Anthropic 当年从那些书里拿走的,不仅没付过任何使用费,回头还用于商业行为(Claude 和 Anthropic API 都是付费服务);而从商业角度来看,蒸馏 Claude 的公司至少付了钱……
当然,从法律层面来看,这两件事的性质完全不同。但不论怎样,Anthropic 看起来还是很像个伪善的双标者。
「后蒸馏时代」
最后再强调一遍:蒸馏有用,但没有你们想象的那么有用。
DeepSeek 的 15 万次,按任何合理标准来看都是可以忽略的数字。Moonshot 和 MiniMax 合计 1650 万次,量级是另一回事——但能转化成多少真实能力,取决于他们能不能解决「如何用好这些数据」的技术问题。
考虑到数据分布差异、模型架构差异,以及代理能力的获得本身对于强化学习的重度依赖,蒸馏从来不是「拿来就用」那么简单。
Lambert 还是给了 Anthropic 面子:「快速迭代加上高质量数据可以走很远,让学生模型超越老师也并非不可能。」

但他也明确指出,真正的创新靠的是强化学习,不是蒸馏。从 DeepSeek、月暗、MiniMax 公开的论文来看,它们都用有相当完善的基础设施和优秀的人才,远非只靠小聪明小伎俩企图弯道超车的「小作坊」。
蒸馏能帮你更快入场,但真要打到顶级水平,从来没有捷径。
某种意义上,Anthropic 提出的「蒸馏」争议,本身就是这个 AI 时代缩影。
整个行业打一开始就建立在暧昧不清的规则上:用人类写的东西训练,用别人的开源成果迭代,在法律没有明确禁止的地方快速行动。
现在,规则开始慢慢收紧——先是版权,再是芯片,现在又是 API……谁在制定规则?谁受益于规则?谁一边打着人类的旗号,却滥用规则谋求私利?
这些问题的答案,都越来越清晰。
#欢迎关注爱范儿官方微信公众号:爱范儿(微信号:ifanr),更多精彩内容第一时间为您奉上。


 https://agent.minimaxi.com
https://agent.minimaxi.com