Google DeepMind 發布 Gemma 4 開源模型系列,主打本地端推理與 Agent 工作流
Google DeepMind 於 2026 年 4 月 2 日正式發布 Gemma 4 開源模型系列,一口氣 […]
The post Google DeepMind 發布 Gemma 4 開源模型系列,主打本地端推理與 Agent 工作流 appeared first on 電腦王阿達.

Google DeepMind 於 2026 年 4 月 2 日正式發布 Gemma 4 開源模型系列,一口氣 […]
The post Google DeepMind 發布 Gemma 4 開源模型系列,主打本地端推理與 Agent 工作流 appeared first on 電腦王阿達.

Google 宣布推出 Gemma 4 開源模型家族,首度採用 Apache 2.0 授權,提供四款規格涵蓋手機到工作站,效能可擊敗體積大 20 倍的模型。
繼去年底推出專有大型語言模型Gemini 3 Pro之後,Google進一步宣佈,正式將打造該系列模型的同源技術與研究成果帶給開源社群,推出全新一代「Gemma 4」開源權重模型 (Open-weight models)家族。
值得注意的是,這次Google不僅賦予這系列模型強大的多模態與離線編碼能力,更首度捨棄自家Gemma授權形式,全面改為更自由的Apache 2.0授權協議,大幅提升開發者的佈署彈性。
四款級距全面涵蓋:從智慧型手機到高階工作站
為了滿足不同硬體環境的運算需求,Google這次依照參數規模 (Parameters),一口氣推出四種不同版本的Gemma 4模型:
• 主攻邊緣裝置 (Edge devices):針對智慧型手機等算力與記憶體受限的裝置,Google提供20億 (2B)與40億 (4B)參數規模的「Effective」 (效能)模型。
• 主攻高階工作站與伺服器:針對具備更強大硬體的運算平台,則推出260億 (26B)參數規模的「Mixture of Experts」 (混合專家)系統,以及310億 (31B)參數規模的「Dense」 (密集)系統。
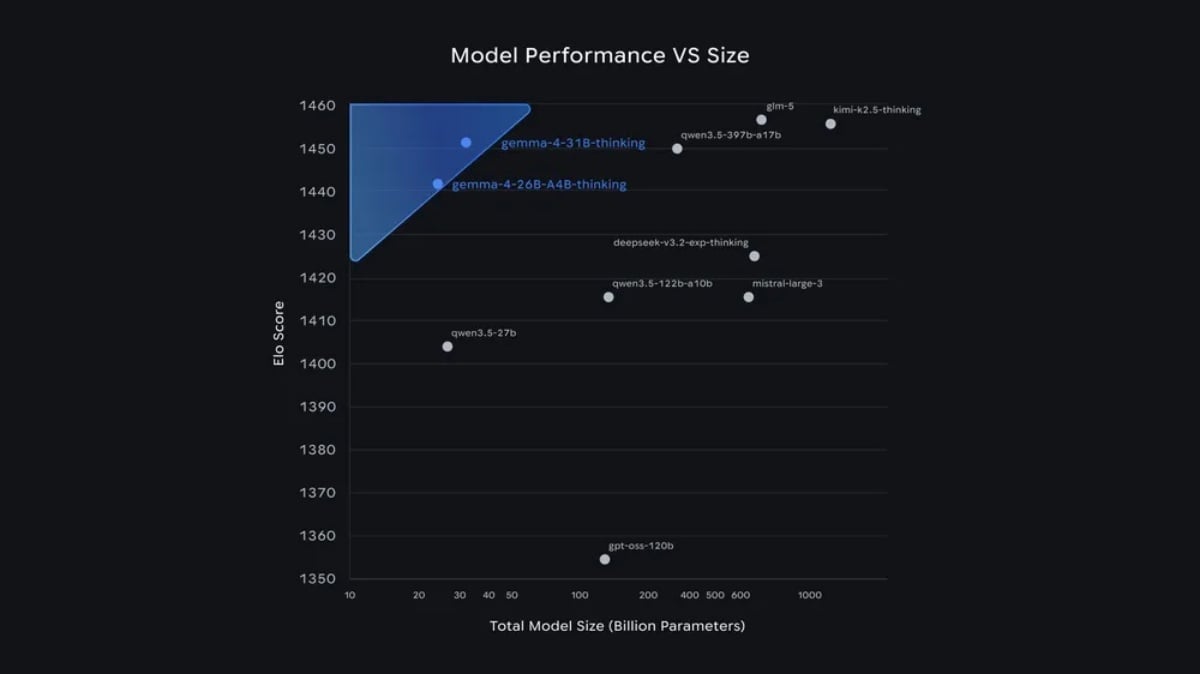
「參數智力比」創紀錄:越級擊敗20倍大模型
Google在聲明中充滿自信地表示,Gemma 4達到「前所未有的單位參數智力水準」 (Intelligence-per-parameter)。
根據Arena AI文字基準測試排行榜,Gemma 4的310億與260億參數版本,分別強勢奪下第三名與第六名的佳績,其表現甚至擊敗體積比它們龐大20倍的巨型模型。
在多模態 (Multimodal)能力方面,Gemma 4全系列模型都具備處理影片與圖像的能力,相當適合用於光學字元辨識 (OCR)等視覺任務。而更令人驚豔的是,兩款體積最小的模型 (2B與4B),竟然同時具備處理音訊輸入與理解語音的能力。
此外,Gemma 4全系列支援超過140種語言,並且能夠進行「離線程式碼生成」,意味開發者可以在完全沒有網路連線的情況下,僅依靠本地算力就能進行Vibe coding (氛圍寫碼)。
擁抱Apache 2.0授權,徹底釋放數位主權
過去,Google的開源模型多半採用自家的「Gemma授權」條款,這在商業使用與修改上仍有部分限制。但這次Gemma 4全面改採業界廣泛認可的Apache 2.0授權。
Google對此解釋:「這項開源授權為開發者的徹底靈活度與『數位主權』 (Digital sovereignty)奠定基礎,賦予開發者對數據、基礎設施與模型的完全控制權」。開發者現在可以更自由地將Gemma 4修改、佈署至地端伺服器 (On-premises)或任何雲端環境中,無須擔憂資安外洩風險。
目前,開發者已經可透過Hugging Face、Kaggle與Ollama等知名開源平台取得Gemma 4的模型權重,並且進行測試。
影視後製業界有一個公開的秘密:從影片中移除一個物體很容易,但讓畫面看起來「它從來不存在」卻極度困難。拿掉畫面中 […]
The post Netflix 開源 AI 模型「VOID」:不只是移除物體,還能「重現物理法則」 appeared first on 電腦王阿達.
