NVIDIA展示神經紋理壓縮技術,可將VRAM用量降至2成以下或使畫質提升

NVIDIA於2023年曾介紹稱為神經紋理壓縮(NTC)的技術,不過迄今還未看到有遊戲開發商進行實作,而在NVIDIA於2026年3月的GTC 2026大會的分組會議影片中,NVIDIA在「Introduction to Neural Rendering」的議程再度介紹神經紋理壓縮技術,強調僅需使用15%記憶體容量即可實現相同的品質,或在相同的記憶體占用大幅提升影像品質。

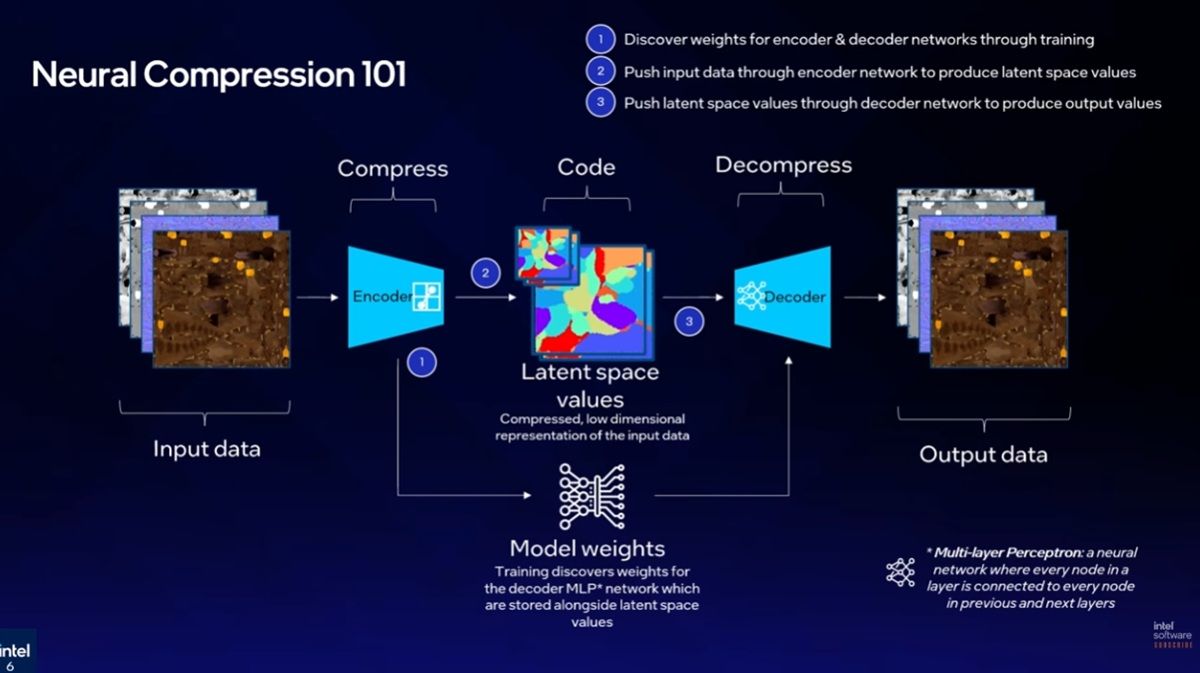
雖然神經紋理壓縮技術結合AI技術,然而並未使用生成式AI,而是透過機器學習、進行具有確定性的紋理解壓縮;神經紋理壓縮不會直接儲存每個紋理元素,而是將紋理壓縮成緊湊、且經過機器學習得到的潛在特徵,在執行神經紋理壓縮時,GPU的小型神經網路可依據這些特徵重建紋理,不須從記憶體載入大型的紋理資訊,且由於這些經過壓縮的特徵是基於機器學習,處理相同的壓縮特徵資料只會得到相同的結果,與具有不確定性的生成式AI截然不同。
神經紋理壓縮包含兩個元件,包括將原始素材極小化的潛在紋理,以及位置編碼;潛在紋理是把紋理元素視為描述材質屬性的特徵向量,而位置編碼則是把UV座標傳遞至解碼器前提供高頻空間資訊、協助神經網路重建原本在壓縮表欠缺的清晰細節與重複圖案;神經網路紋理壓縮技術的訓練則如同標準神經最佳化循環,由神經網路接收位置編碼的UV座標與潛在紋理進行重建,並將結果與原始紋理比對計算重建耗損,以此收斂至神經網路足以達到原始素材品質為止。
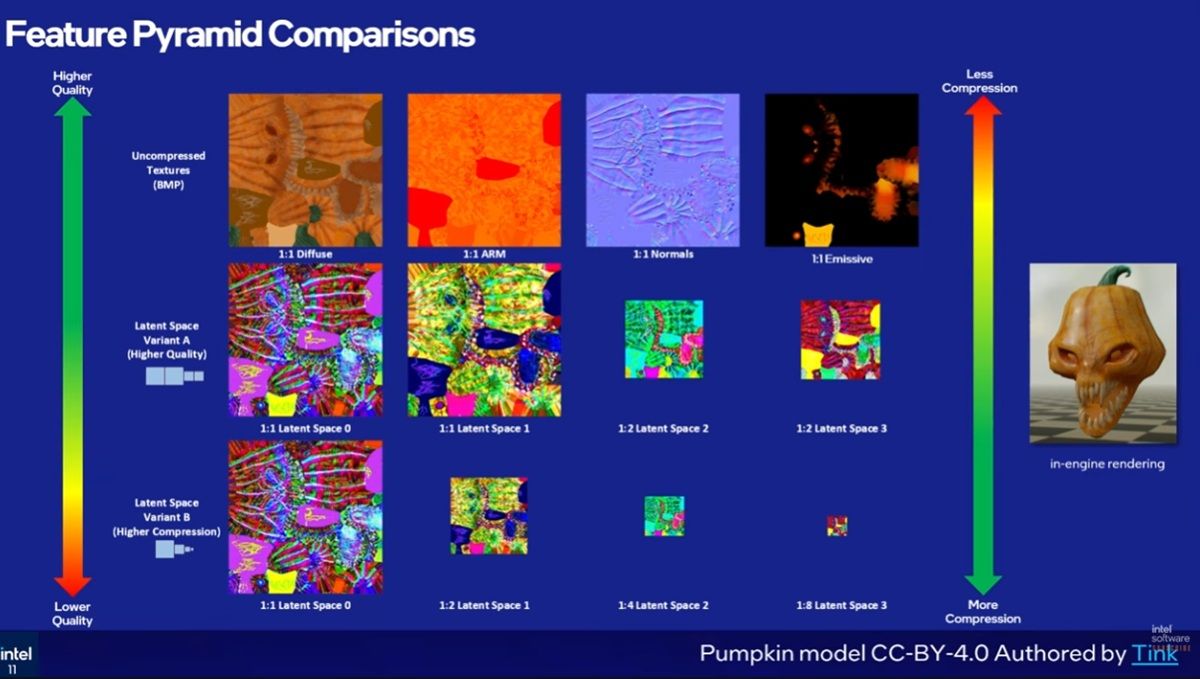
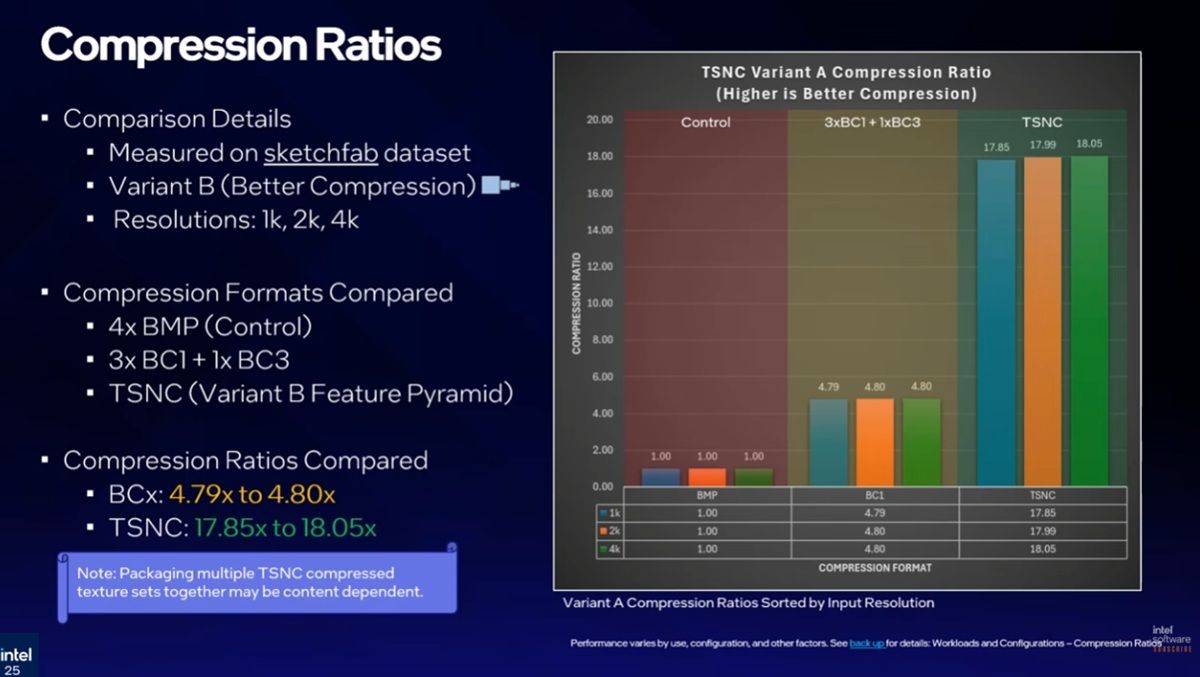
神經紋理壓縮相較傳統紋理壓縮技術可帶來三種好處,一是顯著提高紋理材質的壓縮比、使相同的VRAM容納更多紋理,此外不須拆分或減化資料即可將許多複雜的壓縮材質通道進行壓縮,也由於紋理壓縮資料變小,可減少硬碟占用使檔案縮小、下載更快。


NVIDIA在展演影片舉了兩個案例,一個是Tuscan Villa,在這個示範若使用傳統的BCn紋理壓縮,將佔用高達6.5GB的VRAM,倘若改用神經紋理壓縮僅需970MB;另一個示範是餐桌,在同樣使用970MB的壓縮檔案,使用神經紋理壓縮不僅可提升紋理的品質,還可避免傳統BCn紋理壓縮技術造成的偽影。


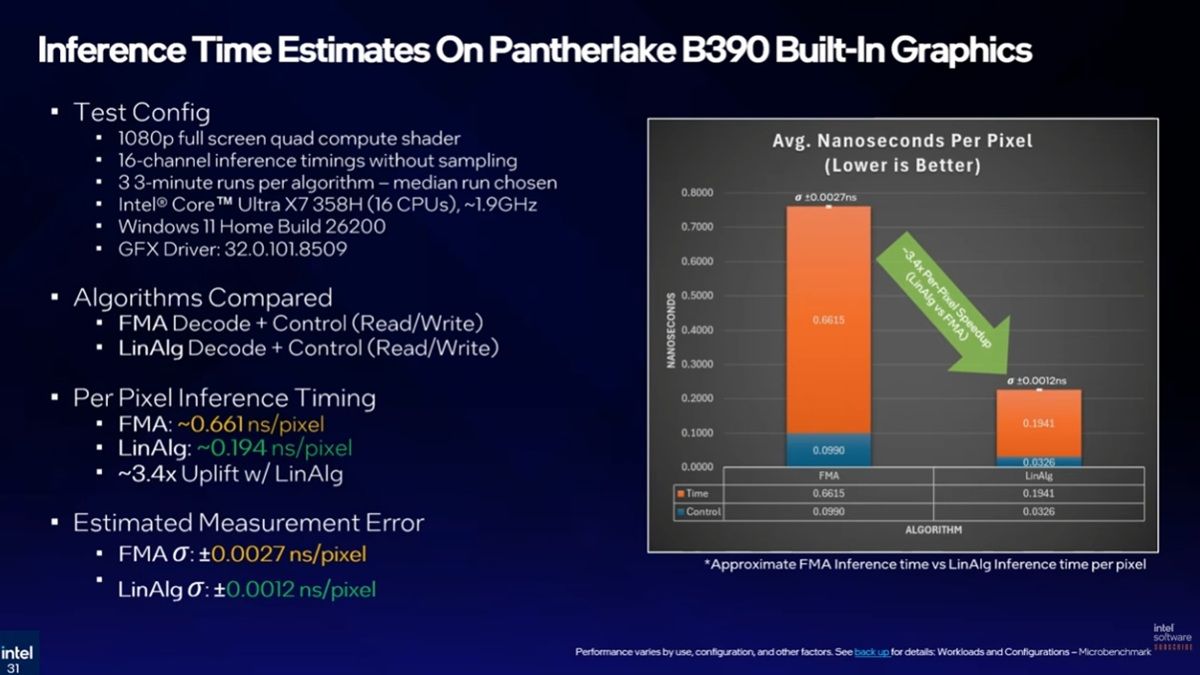
雖然這項技術是由NVIDIA提出,但畢竟採用的是機器學習技術,只要GPU本身有辦法處理機器學習,無論是AMD、Intel的GPU都能導入這項技術,而且AMD與Intel確實都在強化其GPU的AI加速器技術;尤其隨著預期記憶體報價與供應短時間無法回到常軌,預期主流顯示卡的VRAM將會維持好一段時間不會增加的前提下,加上SSD價格也同樣飆升,有著可降低VRAM使用、遊戲檔案大小的優勢,應該也會促使神經紋理壓縮被許多AAA級遊戲開發商採納。