NVIDIA推出黑科技NTC神經紋理壓縮技術:VRAM佔用爆降85%, 遊戲容量也將大減
現代 3A 遊戲的材質紋理越來越精細、HDR 與光追等功能相繼上線,也讓傳統顯示卡的 VRAM(顯示記憶體)不 […]
The post NVIDIA推出黑科技NTC神經紋理壓縮技術:VRAM佔用爆降85%, 遊戲容量也將大減 appeared first on 電腦王阿達.

現代 3A 遊戲的材質紋理越來越精細、HDR 與光追等功能相繼上線,也讓傳統顯示卡的 VRAM(顯示記憶體)不 […]
The post NVIDIA推出黑科技NTC神經紋理壓縮技術:VRAM佔用爆降85%, 遊戲容量也將大減 appeared first on 電腦王阿達.

OpenAI 因能源成本高昂與監管問題複雜,宣布暫停英國 Stargate UK 計畫,此舉恐影響全球主權 AI 擴張策略。
根據彭博新聞報導指稱,OpenAI已經決定暫停其在英國推動的巨型AI基礎設施專案「Stargate UK」。這項原先預計攜手NVIDIA共同協助英國建立「主權AI」 (Sovereign AI)運算能力的重大投資,因為當地高昂能源成本與複雜的監管問題而被迫踩下煞車。這不僅為英國的AI發展願景增加變數,更凸顯AI巨頭在全球擴張算力基礎設施時,所面臨的現實物理資源與地緣法規挑戰。
Stargate UK:打造「主權AI」的關鍵拼圖
OpenAI在去年9月正式對外公開Stargate UK計畫,這項專案建立在該公司幾個月前與英國政府達成的戰略合作基礎之上。
Stargate UK計畫的核心目標,是透過與NVIDIA合作,在英國境內建立強大的資料中心基礎設施。這將使英國政府與當地企業能夠在「本地端」運行頂級的AI模型。對於那些極度重視數據隱私,並且有「資料管轄權」 (Jurisdiction)嚴格要求的特殊政府機關或特定產業應用場景來說,這種將數據與算力留在國內的「主權運算」 (Sovereign computing)能力極為重要。
理想敵不過現實:能源與法規成兩大絆腳石
不過,這項宏大的計畫如今卻宣告停擺。OpenAI在提供給媒體的聲明中坦言,暫停專案的主要阻礙在於「高昂的能源成本」及「監管問題」。
OpenAI強調,他們依然非常看好英國在AI領域發展的巨大潛力,也深知「AI運算」是實現該目標的基石。但官方也明確表態:「我們將持續探索Stargate UK的可行性,但必須等到合適的條件——例如法規環境與能源成本,能夠支持長期的基礎設施投資時,才會繼續推進此專案」。
全球擴張戰略「OpenAI for Countries」是否受阻?
在公布Stargate UK計畫時,OpenAI曾公開表示,他們願意將相同的合作模式提供給其他渴望擴張主權AI能力的國家。這項名為「OpenAI for Countries」的全球倡議,目前正與澳洲、希臘、阿拉伯聯合大公國 (UAE)、斯洛伐克與哈薩克等國家地區進行合作洽談與推動。
目前尚不清楚英國專案的暫停,是否會引發骨牌效應進而影響到上述其他地區的基礎設施佈局,但這確實為這項全球倡議蒙上了一層不確定性。

Meta 與 AI 雲端基礎設施供應商 CoreWeave 簽署新協議,追加 210 億美元訂單至 2032 年,同步自建資料中心,以雙軌戰略支撐新款大型語言模型開發。
面對人工智慧領域深不見底的算力需求,Meta再次以龐大的資本展現其在這場軍備競賽中不落人後的決心。根據最新消息指出,Meta承諾向AI雲端基礎設施供應商CoreWeave追加高達210億美元的訂單。這筆自2027年一路延伸至2032年的新合約,將疊加在先前已公布的142億美元協議之上。
儘管Meta本身也斥巨資自建資料中心,但在剛發表全新「Muse Spark」模型的關鍵節點上,對外租用搭載巨量NVIDIA晶片的算力農場,顯然已經成為科技巨頭們分散風險、確保研發動能不可或缺的「雙軌」戰略。
自建與外租並行:Meta的算力雙軌戰略
這份稍早公布的新協議,明確界定Meta與CoreWeave之間從2027年至2032年的深度合作關係;而雙方在去年9月達成的142億美元合作協議,則將持續履行至2031年。
CoreWeave作為近年來迅速崛起的AI雲端新星,其資料中心內佈署數以十萬計的NVIDIA GPU,專為AI模型的訓練與推論提供基礎設施。
有趣的是,Meta並非沒有自建能力。就在今年3月,Meta才剛宣布將砸下100億美元在美國德州興建一座超大型資料中心。對此,CoreWeave執行長Mike Intrator接受CNBC採訪時表示:「他們當然可以自己買算力硬體。然而,不知何故,這些有能力自己買晶片的人,依然覺得有必要向我們購買服務,這歸功於我們所交付的產品品質」
資本支出翻倍狂飆,全為支撐「Muse Spark」願景
Meta大舉搜刮算力的背後,是其不斷膨脹的AI研發野心與資本支出。
根據Meta先前公布的財報預測,該公司計畫在今年投入高達1150億至1350億美元的資本支出。這個數字不僅遠超華爾街預期,更幾乎是2025年的兩倍之多。
儘管Meta的核心廣告業務已經從AI技術中獲得實質收益,但在最前沿的基礎模型領域,他們仍面臨來自OpenAI、Anthropic與Google的激烈競爭。為了彎道超車,Meta不僅重金打造Superintelligence Labs團隊,更在稍早才剛風光發表備受矚目的全新大型語言模型「Muse Spark」。
Mike Intrator在受訪時指出,Meta從業界四處網羅頂尖AI人才,而這些熟悉各種基礎設施的專家,最終都認為CoreWeave的環境能讓他們更有效率地發揮實力。
CoreWeave的戰略紅利:擺脫對單一巨頭的過度依賴
對於去年剛完成IPO上市的CoreWeave而言,Meta這張210億美元的超級大單,除了帶來豐厚的營收預期,更重要的戰略意義在於「客戶結構的健康化」。
在2024年,微軟一家客戶就佔據CoreWeave高達62%的營收來源。Mike Intrator強調,在拿下Meta的新合約後,未來將不再有任何單一客戶佔據公司總營收的35%以上。
目前,CoreWeave正處於高速擴張的資本密集期。截至2025年底,其資產負債表上背負210億美元的債務,並且在今年3月為了應付新合約所需的基礎設施,又額外借貸85億美元。儘管槓桿極高,但市場似乎仍買單其商業模式,CoreWeave今年的股價已累計上漲約24%,表現優於大盤。

RISC-V 處理器 IP 龍頭 SiFive 完成 G 輪融資,估值達 36.5 億美元,將投入代理型 AI 晶片開發,力圖打破 x86 與 Arm 架構壟斷。
在人工智慧算力需求持續迭代的浪潮下,開源指令集架構RISC-V正迎來史無前例的爆發契機。而RISC-V處理器IP龍頭企業SiFive於美國時間4月9日宣佈,已經成功完成高達4億美元的G輪超額認購融資,一舉將公司估值推升至36.5億美元 (約合新台幣1180億元)。本輪融資不僅吸引Atreides Management領投,更赫見AI晶片霸主NVIDIA與多家華爾街頂級投資機構入局。
SiFive執行長Patrick Little毫不諱言地指出,隨著雲端巨頭對客製化晶片的渴望,以及「代理型AI」 (Agentic AI)工作負載的興起,SiFive將加倍投資資料中心領域,誓言打破傳統專有架構的長期壟斷。
超大型雲端供應商的集體焦慮:渴望擁有「絕對控制權」的CPU IP
長久以來,資料中心的CPU市場一直被x86架構 (Intel、AMD),以及近年強勢崛起的Arm架構所瓜分。然而,隨著AI基礎設施的規模呈指數級擴張,這些「專有指令集架構」 (Proprietary ISAs)高昂授權費與相對僵化的設計限制,已經逐漸無法滿足超大型雲端供應商 (Hyperscale customers)的需求。
SiFive執行長Patrick Little指出當前市場痛點:「超大型雲端供應商已經明確表態,現在正是引進『開放標準替代方案』的時候。他們共同的訴求,是獲得以IP形式提供、具備高度客製化能力的CPU解決方案」。
相較於購買現成晶片或受限於嚴格授權條款的架構,RISC-V提供更高彈性。它允許雲端巨頭根據自身AI工作負載的特殊需求,自由添加、刪減或修改指令集,進而在競爭激烈的雲端算力大戰中打出差異化。
「代理型AI」崛起,高能效CPU重新成為算力樞紐
這次融資聲明中,SiFive反覆提及一個關鍵詞:「代理型AI」 (Agentic AI)。
過去幾年,生成式AI的訓練與推論主要依賴GPU進行龐大的平行運算。當AI模型演進至代理式AI階段時,系統需要處理更複雜的多步驟任務規劃、工具調用,以及系統級的協調。這類需要高度循序漸進與邏輯判斷的任務,正是GPU與專用加速器的弱項,卻是CPU的強項。
在現有的功耗極限下,若繼續採用複雜且耗電的傳統CPU架構來支撐代理式AI,資料中心的電力系統將面臨極度挑戰。SiFive憑藉RISC-V原生具備的低功耗優勢,並且將純量 (Scalar)、向量 (Vector)和矩陣 (Matrix)運算完美整合至單一標準介面中,成為解決「每瓦效能」瓶頸的最佳解決方案。
雖然Arm架構目前也強調有更高的每瓦效能表現,甚至日前也針對廣泛的代理式AI推出旗下首款CPU產品「AGI CPU」,但其背後的指令集授權費用卻仍會讓整體持有成本疊加。而RISC-V架構則採開源形式,讓實際應用處理器產品能以更合理價格提供。
4億美元銀彈到位:完備軟體生態與NVLink深度整合
在獲得4億美元的資金挹注後,SiFive預計將大幅擴張其全球工程團隊,並將資金精準投入以下三大發展方向:
• 先進硬體研發:加速擴展其高效能的RISC-V CPU、加速器,以及系統IP的產品路線圖,全面滿足資料中心等級的運算需求。
• 軟體生態系建構:過去RISC-V最被詬病的軟體支援問題,目前正在被迅速解決。SiFive將基於目前已有的CUDA、RedHat和Ubuntu移植基礎,加速資料中心軟體的開發與相容性測試。
• 客戶賦能與生態系串聯:緊密配合產業領軍企業的技術標準,特別提及將加速支援NVIDIA NVLink Fusion技術,意味未來的SiFive CPU將能以極高頻寬與NVIDIA GPU進行無縫互連,大幅縮短客戶在AI伺服器叢集上的佈署時間。
在阿正老師的Top 5 瀏覽器懶人包文章結尾,我偷偷提到自己同時在用 Chrome、Firefox、Edge、 […]
這篇文章 不想用 Chrome 了嗎?7 款非主流但超好用的瀏覽器,Vivaldi、Brave、Dia 都在這! 最早出現於 軟體玩家。

在生成式人工智慧(Generative AI)算力競賽進入白熱化的今日,HBM(高頻寬記憶體)的規格升級始終被 […]
The post 郭明錤揭秘解構「記憶體之牆」:從硬體到演算法,AI 巨頭如何多維度緩解記憶體瓶頸 appeared first on 電腦王阿達.
稀宇科技近日開源的 Minimax M2.7 模型,很多人一定都想玩玩看,不僅支援 Agent、工具調用和多任務,更具備「自我演化(Self-Evolution)」的能力,聽起來就相當強,只不過 229B 這麼大的參數量,絕大多數人的電腦一定跑不動。而這篇就要來告訴你一個好消息,NVIDIA 的免費 API 就能呼叫這款 Minimax M2.7 模型,而且是完全免費用,無需填寫信用卡,實測可用於 OpenClaw 龍蝦,下面就來教你怎麼做到。
The post NVIDIA API 讓你完全免費呼叫 Minimax M2.7 模型,也能用在 OpenClaw 龍蝦 appeared first on 電腦王阿達.

雖然GPU擅長的通用加速運算與量子電腦的量子運算是兩回事,不過在目前量子運算仍未達到商用化的階段,GPU卻能透過模擬協助開發量子處理器、量子運算應用以及作為量子校準及糾錯,NVIDIA亦針對量子運算釋出多款專業工具;隨著AI技術發展,NVIDIA宣布推出全球首款應用於量子電腦開發的AI模型Ising,利用AI為量子處理器的校準及量子錯誤修正解碼帶來突破性的表現,同時Ising亦是一款開源模型,可幫助全球量子企業、學術機構與實驗室加速量子處理器開發。
NVIDIA已將NVIDIA Ising納入NVIDIA開源模型產品組合,可自GitHub、Hugging Face與build.nvidia.com取得相關開放資料。
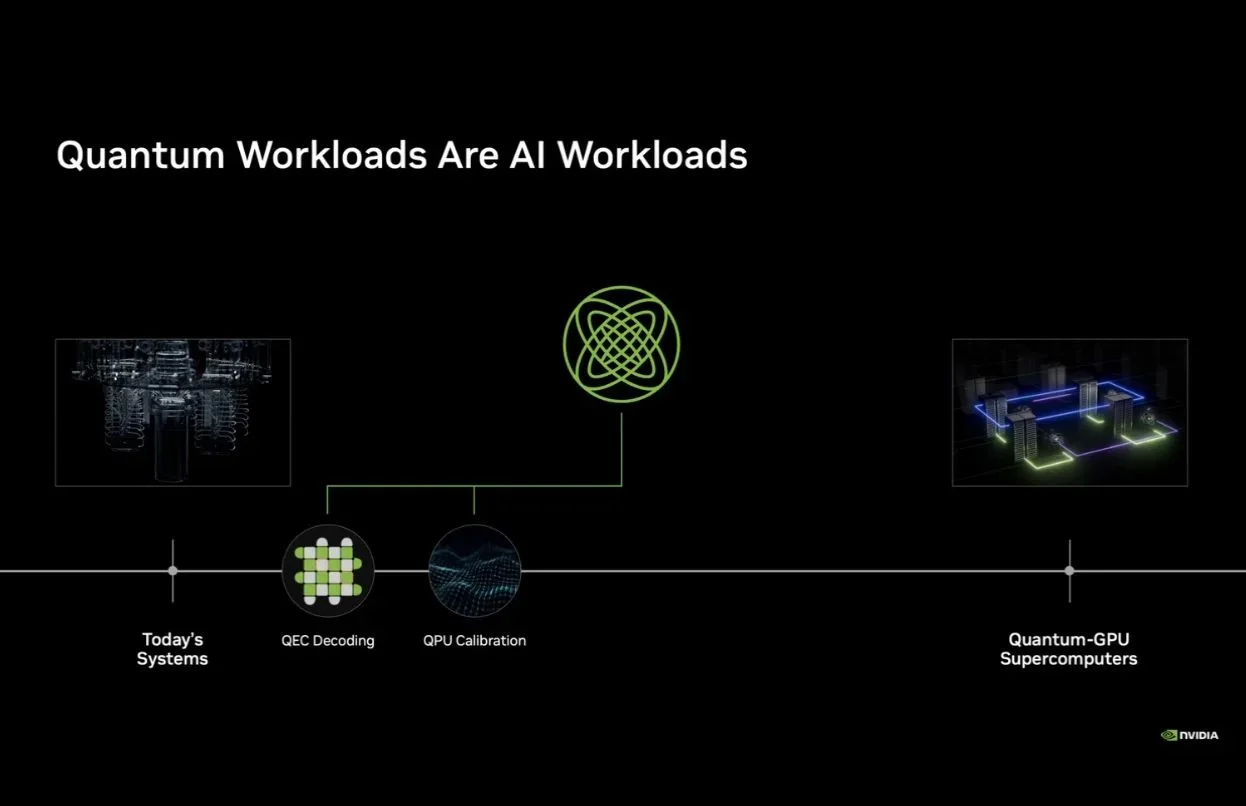
NVIDIA指出量子運算邁向大規模商用,量子處理器的校準與量子錯誤修正必須有重大的突破,而AI技術將會成為這兩項關鍵因素獲得顯著提升的關鍵,NVIDIA希冀透過開源的Ising幫助開發者在完全掌控其資料與基礎設施的同時鍵夠高效能AI。
同時NVIDIA也提供包括量子運算工作流程與訓練資料的實作指南,並可搭配NVIDIA NIM微服務,使開發者可透過最少的設定針對特定硬體架構與使用情境微調模型,並可在研究人員的本地系統執行,不須透過雲端處理,進一步確保資料的保護。
Ising的命名源自大幅簡化對複雜物理系統理解的重要數學模型,透過NVIDIA Ising模型提供高效能且可擴展的工具,能用於量子錯誤修正與校準,解決建構混合量子-經典系統最關鍵的挑戰;NVIDIA Ising模型驅動全球最頂尖的量子處理器校準,使研究人員能活用量子電腦解決更大規模且複雜的問題。
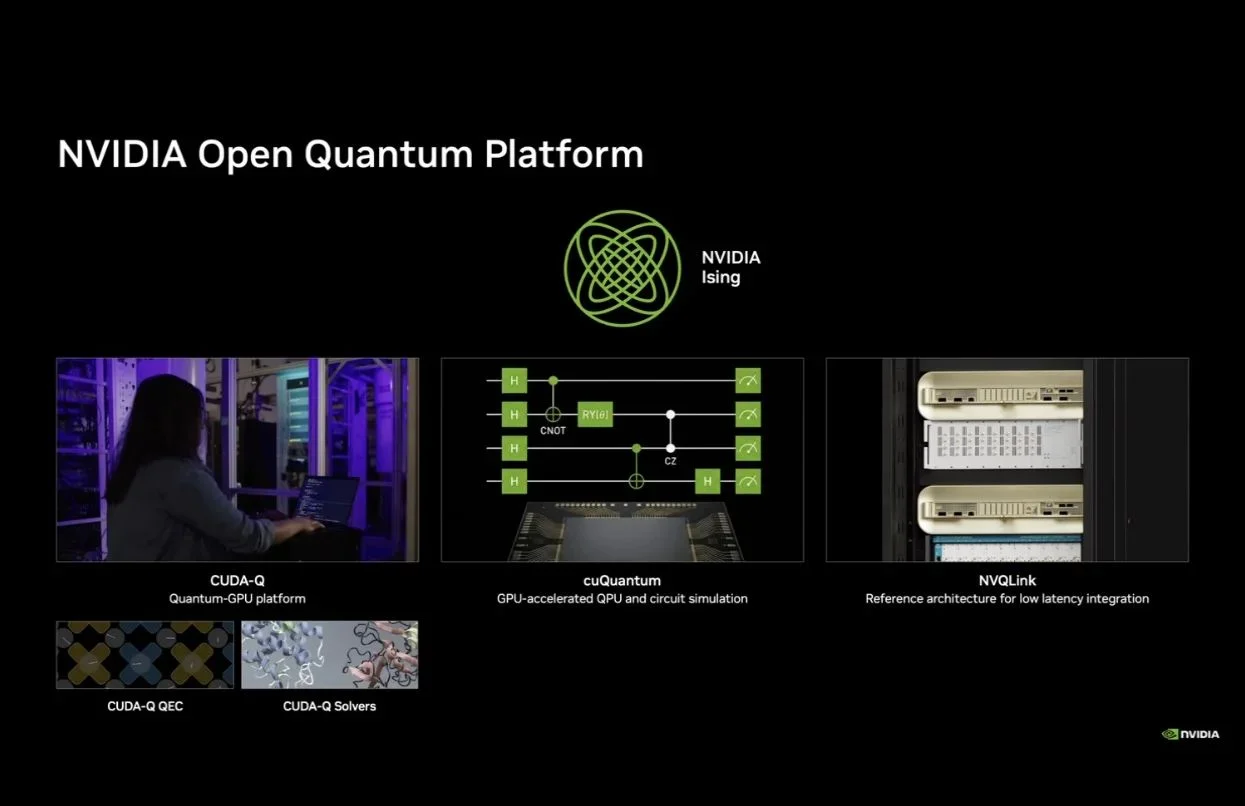
同時NVIDIA Ising與NVIDIA用於混合量子-經典運算的NVIDIA CUDA-Q平台相輔相成,並整合NVDIIA NVQLink、QPU-GPU硬體互連,可支援即時控制與量子錯誤修正,建構一套完善的工具組合。

NVDIA Ising包含兩項關鍵模型:Ising Calibration與Ising Decoding;Ising Calibration是可快速解讀及回應量子處理器測量結果的視覺模型,可透過AI代理自動化執行持續校準,並將所需時間自數天縮短為數小時;Ising Decoding則是一項3D捲積神經模型,透過兩種針對速度或準確度最佳化的版本在執行量子錯誤修正時提供即時解碼。
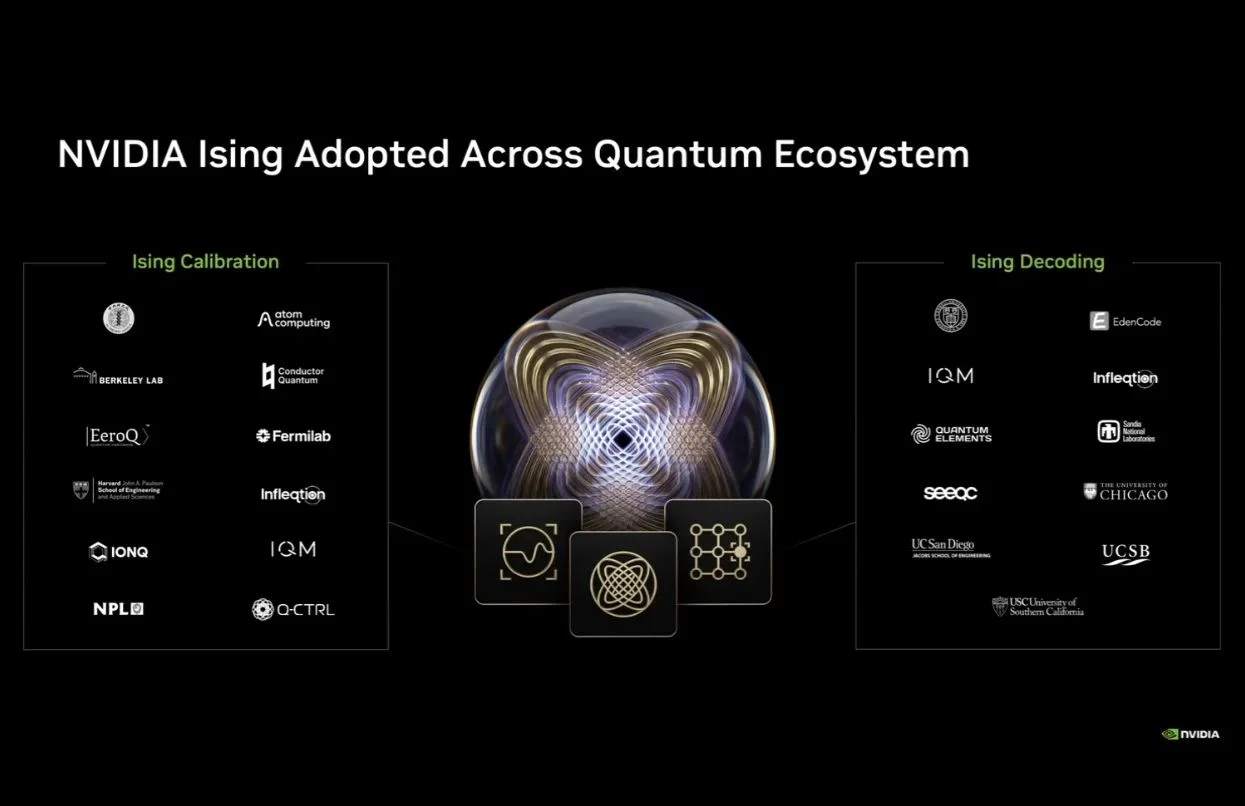
Atom Computing、中央研究院、 EeroQ 、Conductor Quantum、 費米國家加速器實驗室 、哈佛大學約翰.保爾森工程與應用科學學院、Infleqtion、IonQ、IQM Quantum Computers、 勞倫斯伯克利國家實驗室先進量子測試平台 、Q-CTRL以及英國國家物理實驗室(NPL)均已導入Ising Calibration。
Ising Decoding則獲得包括康乃爾大學、 EdenCode 、Infleqtion、IQM Quantum Computers、Quantum Elements、桑迪亞國家實驗室、SEEQC、加州大學聖地牙哥分校、加州大學聖塔芭芭拉分校、芝加哥大學、南加州大學與延世大學導入。

NVIDIA 於世界量子日宣布推出全球首款開源量子 AI 模型系列「NVIDIA Ising」,透過 AI 技術解決量子校準與錯誤更正問題,將校準時間從數天縮短至數小時。
為了響應世界量子日 (World Quantum Day),NVIDIA今日 (4/17)宣布推出全球首款專為建構量子處理器 (QPU) 所設計的開源人工智慧模型系列——「NVIDIA Ising」。NVIDIA強調,量子運算要邁向百萬級量子位元 (Qubit)的實用化階段,最大的挑戰在於解決量子雜訊問題,而量子工作負載本質上就是「AI工作負載」,因此必須仰賴AI來驅動解碼、控制與錯誤更正。
突破人工校準瓶頸:Ising Calibration (量子硬體校準)
現今的量子位元極度容易受到雜訊干擾,加上物理特性並不穩定。傳統上,即便只是校準50到100個量子位元,依然需要物理專家耗費數天的時間進行手動微調,這在擴展至數千或數百萬個量子位元時是完全不切實際的。
為了解決這個問題,NVIDIA推出名為「Ising Calibration」開源模型。
• 視覺語言模型架構:這是一款參數規模達350億的視覺語言模型 (VLM),能夠直接讀取QPU的測量數據,並且自動進行校準。
• 輕量且高效:相較於現有替代方案,其模型體積縮小15倍,卻能在包含6項指標的校準基準測試中達到世界最佳效能表現。
• 大幅縮短時間:能將原本需要人類專家花費「數天」的校準時間,大幅壓縮至「數小時」內完成。
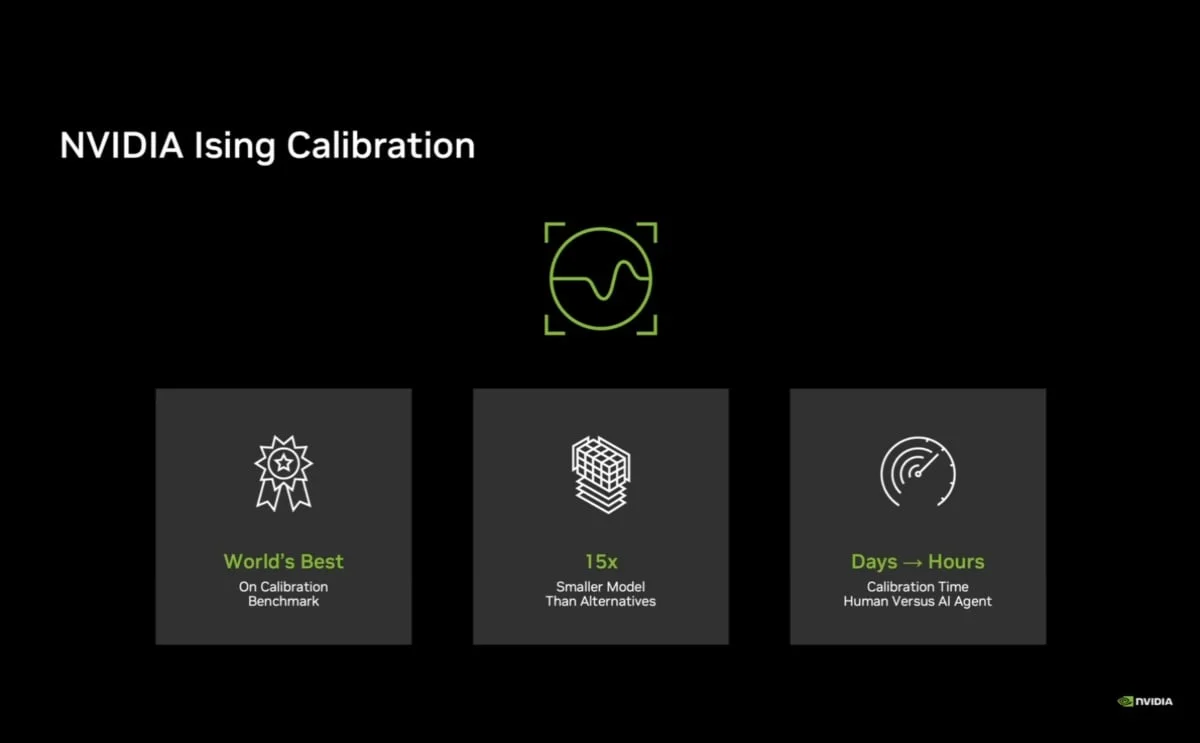 ▲NVIDIA推出名為「Ising Calibration」開源模型,能將原本需要人類專家花費「數天」的量子校準時間,大幅壓縮至「數小時」內完成
▲NVIDIA推出名為「Ising Calibration」開源模型,能將原本需要人類專家花費「數天」的量子校準時間,大幅壓縮至「數小時」內完成
強化錯誤更正效率:Ising Decoding (量子解碼)
在量子錯誤更正 (QEC) 方面,系統需要在極短的時間內處理高達TB級別的龐大資料,這對運算速度與準確度提出嚴苛的要求。
「Ising Decoding」採用卷積神經網路 (CNN)架構,專為量子錯誤更正而生。NVIDIA針對不同的應用情境提供了兩種變體模型:
• 追求極致速度:針對速度優化的版本,其運作速度比目前的業界標準 (Pine-marten)快上2.5倍。
• 追求極致精準:針對準確度優化的版本,其準確度更是現有標準的3倍。
除此之外,該模型在訓練時所需準備的資料量也大幅減少10倍,這對於資源昂貴的量子研究環境而言是一大福音。
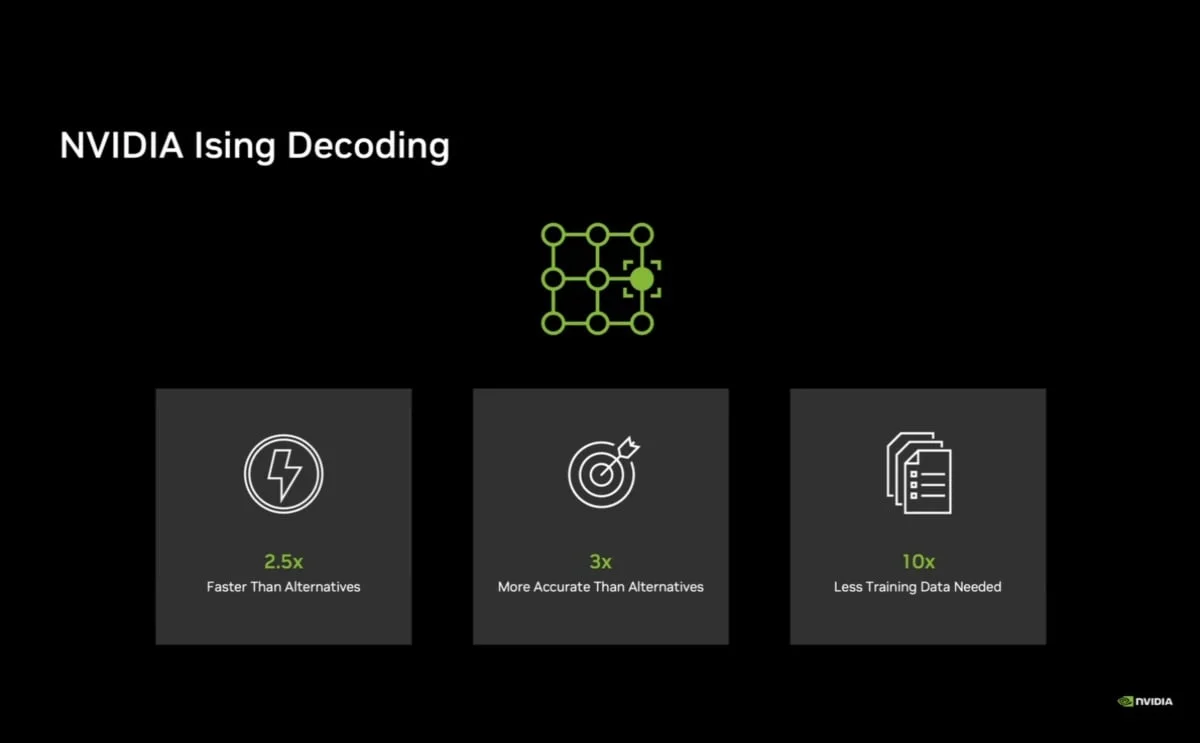 ▲「Ising Decoding」採用卷積神經網路 (CNN)架構,專為量子錯誤更正而生
▲「Ising Decoding」採用卷積神經網路 (CNN)架構,專為量子錯誤更正而生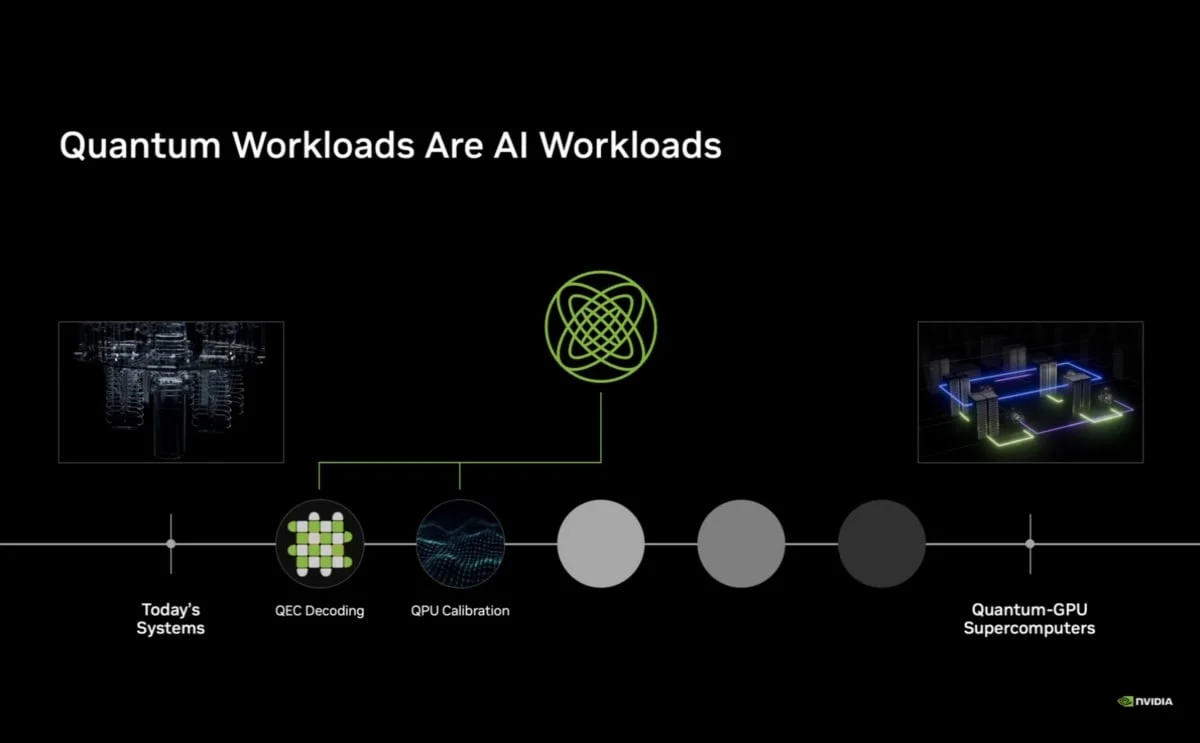 ▲NVIDIA認為量子運算工作流程,實際上與AI運作流程相同
▲NVIDIA認為量子運算工作流程,實際上與AI運作流程相同
擁抱開源生態系,結合NVIDIA既有量子平台
NVIDIA Ising並非封閉系統,而是一個完整的「開源模型家族」。NVIDIA不僅釋出模型本身,還同步提供微調 (Fine-Tuning)、量化 (Quantization)、推論工作流程的指引內容 (Cookbook),以及相關的開源研究論文與基準測試數據,讓生態系夥伴與研究人員能針對各自特製的硬體進行客製化與微調。
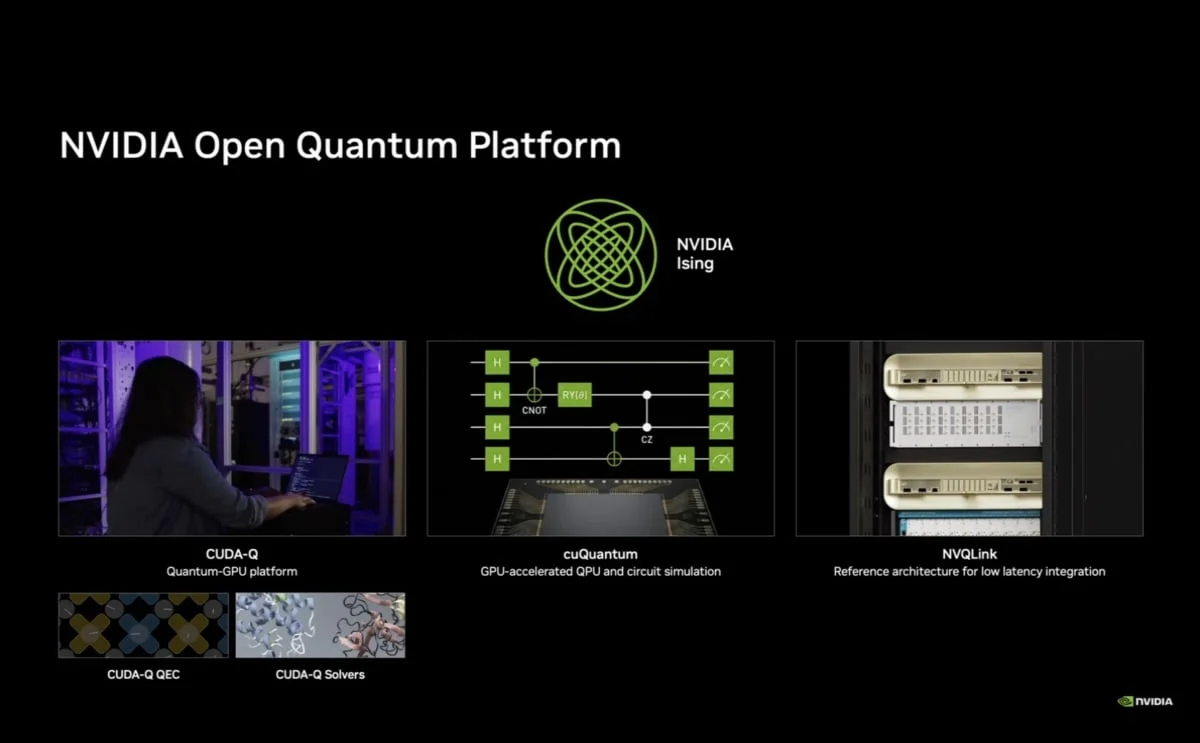 ▲NVIDIA不僅釋出模型本身,還同步提供微調 (Fine-Tuning)、量化 (Quantization)、推論工作流程的指引內容 (Cookbook),以及相關的開源研究論文與基準測試數據,讓生態系夥伴與研究人員能針對各自特製的硬體進行客製化與微調
▲NVIDIA不僅釋出模型本身,還同步提供微調 (Fine-Tuning)、量化 (Quantization)、推論工作流程的指引內容 (Cookbook),以及相關的開源研究論文與基準測試數據,讓生態系夥伴與研究人員能針對各自特製的硬體進行客製化與微調
同時,NVIDIA Ising也深度整合NVIDIA Open Quantum Platform的既有資源,包含Quantum-GPU平台CUDA-Q、提供GPU加速運算的cuQuantum,以及用於低延遲整合的NVQLink參考架構。透過cuQuantum,即便是尚未取得昂貴實體量子硬體的開發者,也能夠過GPU模擬環境來進行合成數據的訓練與開發,進一步實現量子運算的民主化。
目前,NVIDIA Ising已經獲得量子運算生態系的廣泛採用,包含勞倫斯伯克利國家實驗室、哈佛大學、IonQ、IQM、Atom Computing等眾多頂尖研究機構與企業,都已經將Ising模型導入其校準與解碼的研發工作流程中。
小結:NVIDIA正以AI優勢,奠定未來混合超級運算的軟體底層
面對量子運算這項充滿不確定性的前瞻技術,NVIDIA正利用其在AI領域的絕對主導地位,試圖解決量子硬體發展中最棘手的「控制」與「除錯」問題。透過將Ising模型開源,NVIDIA實質上正在為未來的「量子-GPU 混合超級運算」建立一套難以撼動的基礎軟體標準與生態系。
 ▲NVIDIA正利用其在AI領域的絕對主導地位,試圖解決量子硬體發展中最棘手的「控制」與「除錯」問題。透過將Ising模型開源,NVIDIA實質上正在為未來的「量子-GPU 混合超級運算」建立一套難以撼動的基礎軟體標準與生態系
▲NVIDIA正利用其在AI領域的絕對主導地位,試圖解決量子硬體發展中最棘手的「控制」與「除錯」問題。透過將Ising模型開源,NVIDIA實質上正在為未來的「量子-GPU 混合超級運算」建立一套難以撼動的基礎軟體標準與生態系
之前我們曾報導過,NVIDIA 正在準備推出搭載 9GB GDDR7 記憶體的 RTX 5050 新版本,這個記憶體升級看起來不僅限於入門款,根據近日的最新爆料,RTX 5060 Ti 和 RTX 5060 也將推出 9GB GDDR7 記憶體的新版本,而且細節比先前更加明確,包括記憶體配置方式、匯流排寬度的改變,以及預計的推出時程。不過跟 RTX 5050 的情況一樣,雖然多了 1GB,但也有一個不能忽視的缺點:頻寬將縮水。
The post NVIDIA RTX 5060 Ti 與 RTX 5060 傳也將推出 9GB GDDR7 版本,多 1GB 記憶體但頻寬縮水 25% appeared first on 電腦王阿達.

NVIDIA在官網公布於Computex 2026期間同步舉辦NVIDIA GTC Taipei大會,其中主題演講選在2026年6月1日上午11點於台北流行音樂中心,即日起開放民眾報名參與,主題演講座位有限,將依據報名先後順序安排,而GTC Taipei主題演講也將同步在NVIDIA官方社群平台直播。

NVIDIA GTC Taipei將分為大會、大會與實作坊以及僅參與主題演講,僅參加主題演講為免費,參加大會活動為85美金,參加大會與全天實作坊為350美金。活動報名:NVIDIA

NVIDIA GTC Taipei預計於2026年6月1日至6月4日於台北國際會議中心展開,將探索下一代AI技術,其中包括AI工廠與擴充基礎設施、代理與推論AI、科學領域AI、物理AI及機器人等主題,並包含各項動態議程、實作訓練與交流機會。
如果要問 2026 年 AI 產業最關鍵的問題之一是什麼,那大概就是:Nvidia 的護城河到底還能守多久?當 […]
The post Dwarkesh Patel 專訪黃仁勳拆解 Nvidia 護城河,從 TPU 競爭到中國晶片出口管制一次講清楚 appeared first on 電腦王阿達.
