微軟推出 3 款自製 AI 模型 MAI 系列搶市場挑戰 OpenAI
微軟推出語音辨識、語音生成、圖像生成等 3 款 MAI 模型,性能超越 OpenAI 與 Google,定價更便宜一半,小團隊開發創造 AI 產業奇蹟。
由微軟AI執行長Mustafa Suleyman領軍的「超級智慧團隊」 (Superintelligence team),稍早一口氣發表三款完全由微軟內部從零研發的基礎AI模型,分別是語音辨識模型MAI-Transcribe-1、語音生成引擎MAI-Voice-1,以及圖像生成模型MAI-Image-2。這不僅是微軟首度拿出足以在單一領域擊敗Google與OpenAI的自研火力,更透過極具侵略性的定價策略與驚人的硬體執行效率,向華爾街證明其龐大的AI基礎設施投資,已經準備好轉化為實質的獲利武器。
瞄準企業痛點:三劍客齊發,標榜算力減半、效能封頂
這次推出的「MAI」系列模型,精準鎖定企業級AI應用中最具商業價值的三大領域,並且已經同步上架至Microsoft Foundry與全新的MAI Playground:
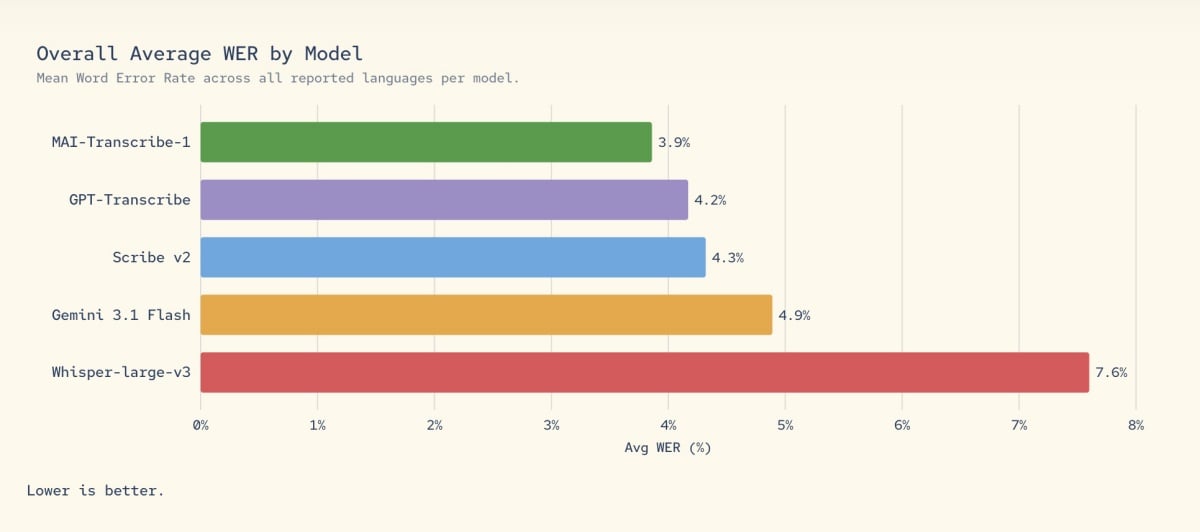
• MAI-Transcribe-1 (語音轉文字):這是本次發布的重頭戲。根據FLEURS基準測試,其在25種主要語言中的平均單字錯誤率 (WER)僅3.8%,不僅全面擊敗OpenAI廣受歡迎的Whisper-large-v3,更在22種語言中碾壓Google的Gemini 3.1 Flash。最驚人的是,Mustafa Suleyman強調該模型「只需競爭對手一半的GPU算力」即可運行,批次轉錄速度更比現有的Azure方案快上2.5倍。
• MAI-Voice-1 (文字轉語音):具備極強的生成效率,能在1秒內生成長達60秒的高自然度語音,並且支援透過短短幾秒的音檔進行客製化聲音複製 (Voice Cloning)。微軟對其開出每百萬字元僅需22美元的極具競爭價格,直接向ElevenLabs等語音新創宣戰。
• MAI-Image-2 (圖像生成):該模型目前已經擠進Arena.ai排行榜前三名,生成速度比前代快上兩倍。微軟已將其整合至Bing與PowerPoint中,並且以每百萬輸入推論字元僅需5美元、輸出則是33美元的破盤價搶市。
重啟談判OpenAI合約,解開「獨立研發」的封印
微軟為何在這個時間點突然端出這些頂尖模型?背後的關鍵,在於一場不為人知的合約重塑。
Mustafa Suleyman坦言,在2019年與OpenAI簽署的原始授權協議中,微軟被合約「明文禁止」獨立開發通用人工智慧 (AGI)。但隨著OpenAI去年開始積極尋求SoftBank等外部算力與資金支援,微軟抓住了機會。
在去年的重新談判中,微軟成功解除了這項限制。雖然雙方的授權合作關係仍將至少延續至2032年,但微軟現在已獲得「完全自由」,能夠不受限制地籌組算力、收購數據,並且研發自家的前沿模型 (Frontier Models)。
不到10人的菁英團隊,重塑AI算力經濟學
這場發布會中最讓業界震撼的內幕,莫過於這些媲美科技巨頭頂級水準的模型,背後的開發團隊規模小得令人難以置信。
Mustafa Suleyman透露,「我們的語音模型只有10個人參與打造,圖像團隊同樣不到10人」。相較Meta砸下數億美元網羅成百上千名研究人員,微軟試圖證明:透過架構的創新與極度乾淨 (Clean lineage)的訓練數據,小團隊也能創造奇蹟。
這套「人本AI」 (Humanist AI)哲學與對訓練資料版權的嚴格把關,正是微軟用來吸引極度重視合規性與資安的企業客戶(如金融、醫療產業)的最大籌碼。
分析觀點
MAI系列模型的誕生,本質上是一場「降本增效」的保衛戰。
藉由在內部產品 (如Microsoft Teams、Copilot)中全面以MAI模型替換掉第三方模型,微軟能以「不到對手一半的GPU消耗」來大幅壓低銷貨成本 (COGS)。而在對外銷售上,Mustafa Suleyman更是毫不掩飾地表示,其定價策略就是要「比亞馬遜和Google等所有雲端巨頭都要便宜」。
而語音和圖像模型終究只是前菜,Mustafa Suleyman已經明確表態,微軟的終極目標是開發出能與GPT-4,以及Gemini正面硬碰硬的「大型語言模型」,以達成徹底的「AI自給自足」。
透過這三款MAI模型的成功試水溫,微軟向市場證明其強大的工程落地能力,接下來的AI大模型之戰,微軟將不再只是OpenAI身後那個只負責出錢和出伺服器的「金主爸爸」。