Sight & Sound 2025最佳电影|NO.5:《秘密特工》(克莱伯·门多萨·菲略)
2025年12月23日 04:23
影片设定在 20 世纪 70 年代巴西军政府独裁统治时期,讲述一位学者在一次反抗行动后被迫逃亡的经历。克莱伯·门多萨·菲略(Kleber Mendonça Filho)这部不断带来惊喜的惊悚片,兼具悬念与幽默,同时也是一堂重要的历史课。
在此前《软件 AI 化,势不可挡|AI Agent 是什么?》的文章里,详细总结了下 AI Agent,青小蛙觉得可以更简单的理解:
AI Agent,就是 AI 代理人:它替人类工作,帮你操作电脑,自己决定怎么做,并持续执行,就像牛马一样,给定目标,完成目标。
几天前,论坛中接连有人介绍 Open Minis,非常棒的一款免费应用,它有点类似 OpenClaw,在 iOS 里控制一套完整的 iSH (Alpine Linux) 虚拟机,有终端,有浏览器。
一起来看下这两篇文章:
你或许听说过或用过 Manus,它能在其云端运行虚拟机或者有头浏览器,并且能自己运行命令或者操控网页。
在 Manus 同期,实际上像是 Claude Code 或者 Codex 这样的 AI Agent App 也能靠 PlayWright 来达到类似的效果,这样你就可以在本地来让 AI 进行作业了。
之后 OpenClaw 其实是在这个基础上,集成了各类渠道,这样你就可以用聊天软件直接发消息让 bot 执行命令。
但这终究有局限性,你会发现这些方式都不能很好的和你的手机进行交互,你的手机只是一个给 AI 发消息的工具,AI 却不能反过来使用你的手机。
Open Minis 能通过在本地模拟运行一个 Linux 虚拟机(魔改 iSH),并通过命令行工具来读取 iOS 的设备端功能,例如地图、照片、日程、闹钟等。
Open Minis 可以:
并且也有 skills 和记忆的支持,你可以认为 OpenClaw 能做到的,它也能做到。并且由于能读取设备端能力,所以可能实际体验要更好。
此外,也支持使用快捷指令执行定时任务。或者,你可以这样将其改成使用 Action Button 即可触发的全局 ai 助手:
@RachelSherman 同学说:AI帮我写的文案,味道有点大,轻喷,我不是开发者,觉得很好用,分享一下
青小蛙手动总结一下吧:
原文:https://www.appinn.com/open-minis/
非常不错的应用,开发者更新频繁,并且 TestFlight 测试版本还有名额,想尝试的同学不要错过哦。
你有没有试过这样一种感觉:有些事情,你明明知道 iPhone 能做,但就是懒得打开 App,一步步操作。
现在不太一样了,创建日历、记录咖啡摄入、自动生成视频……
iPhone 开始可以自己把这些事做完了。
昨天介绍了:Open Minis:可能是 iOS 端最强 AI Agent 之后,看到开发者这些天陆陆续续转发的一些案例,非常有趣,也很实用。
青小蛙总结了 11 个 iPhone 开启 Open Minis 后能做的事情,它只有 49.8 MB 的大小。
你觉得还能做什么呢?
将带有时间、地点、事件的内容直接分析给 Minis,就可以创建日历:(via)
让 Minis 直接读取并分享健康信息:(via)
直接让 Minis 读取 Apple Watch 中的数据,分析健康情况(via)
将图片发给 Minis,让他通过 Spotify Skill 搜索歌曲、切歌播放。
这个看起来有点离谱了,流程大概是这样的:(via)
这个效果也不错,将 TikTok 评论截图发给 Minis,并最终导出到了 YouTube Music 歌单中:
这也是一个很有趣的流程,你可以根据自己感兴趣的内容来源,让他帮你自动生成音频,在早上的时候播放出来,替代闹钟。
这是开发者 @Ethan 自己的用途,它的社群消息有非常多的用户反馈,使用 Minis 读取反馈,整理信息,最终写入系统提醒应用中。
后续,当修复了 Bug 之后,还会自动对照代码库,标记完成。
这里有一个例子,将 xiaohongshu-cli 的 GitHub 页面直接给它,让他整理为笔记文档,最终在 iOS 笔记应用中,看到了整理后的使用笔记:(via)
直接拍照两颗胶囊咖啡,然后让它记录到健康中。再结合之前的自动分析健康数据,闭环了。
对于一些复杂的重复性操作,交给 Minis 简直太爽了。(via)
比如这个例子中,让 Minis 设置了很多个起床闹钟,自动,不动手。
如果是以往,你需要一个一个手动处理,还容易出错…
原文:https://www.appinn.com/iphone-automation-11-real-use-cases/
如果你想打造一个完全本地运行、无需 API Key、可接入微信的 AI 助手系统,这套方案可以说是目前最香的组合之一:Hermes Agent + WebUI + Ollama + Gemma 4 ,不仅免费,而且隐私可控、可扩展性极强,非常适合做自动化助手、私域 AI、甚至商业化探索。
![]()
先快速理解一下整体结构:
首先,我们需要准备本地大模型环境。
官网安装: 【点击前往】 下载最新版
安装完成后,拉取 Gemma 4 模型:
ollama run gemma4
Ollama 默认会启动本地服务:http://127.0.0.1:11434
但 Hermes Agent 需要用你局域网 IP来访问。
在 CMD 输入:
ipconfig
找到类似: IPv4 地址 . . . . . . . . . . . : 192.168.1.228
那么你的 API 地址就是: http://192.168.1.228:11434/v1
![]() 这个地址非常关键,后面要填到 Hermes 配置里!
这个地址非常关键,后面要填到 Hermes 配置里!
Hermes Agent 官方推荐 Linux 环境,这里我们用 WSL2。
在开始之前,建议大家安装下 Windows Terminal,它是一款新式、快速、高效、强大且高效的Windows 的终端程序,适用于命令行工具和命令提示符,PowerShell和 WSL 等 Shell 用户。可以方便我们切换不同的系统!
![]()
在 PowerShell(管理员)执行:
安装完成后重启电脑,然后安装Ubuntu,
检查版本:
确保输出结果是:WSL2
进入 Ubuntu 后,开始核心部署。
curl -fsSL https://raw.githubusercontent.com/NousResearch/hermes-agent/main/scripts/install.sh | bash
安装完成后,可以执行:
hermes doctor
检查环境是否正常。
git clone https://github.com/nesquena/hermes-webui.git hermes-webui cd hermes-webui ./start.sh
启动后,一般访问:
http://127.0.0.1:8787
即可打开 UI 页面 🎉
git clone https://github.com/nesquena/hermes-webui.git hermes-webui cd hermes-webui python3 bootstrap.py
引导程序将:
curl -fsSL https://raw.githubusercontent.com/NousResearch/hermes-agent/main/scripts/install.sh | bash)。/health。--no-browser。
运行:
hermes setup
进入配置界面后:
http://192.168.1.228:11434/v1
gemma4
![]() 如果提示上下文不足(比如你之前遇到的 8K 限制问题):
如果提示上下文不足(比如你之前遇到的 8K 限制问题):
可以修改:
model:
context_length: 8192
或者换更大的模型。
hermes setup
找到:
messaging platforms
选择:
weixin / wechat
系统会弹出二维码:
用微信扫码登录即可完成绑定
完成后你就拥有:
部署完成后,你的系统具备:
![]() 本地 AI(Gemma 4)
本地 AI(Gemma 4)
![]() 可视化 UI 管理
可视化 UI 管理
![]() 微信实时对话
微信实时对话
![]() 无需 Token / 无费用
无需 Token / 无费用
![]() 完全私有化部署
完全私有化部署
错误示例:
context window too small
解决:
检查:
127.0.0.1(尝试:
./start.sh
或者检查端口占用。
这是微信协议限制,建议:
这套方案的核心价值在于:
零成本 + 本地化 + 可扩展 AI Agent
相比传统 OpenAI API 方案:
如果你做:
这套架构非常值得你深入研究。
![]()
如果说大模型最早带来的冲击,是让用户开始习惯和机器进行自然语言对话,那么 Agent 的下一步,则是让 AI 从「回答问题」走向「完成任务」。它不再只是一个聊天窗口,而是可以理解场景、拆解任务、调用应用、协同设备,并在更长周期里记住用户偏好的系统级能力。
对于许多人来说,AI 是一个 ChatBox,更是一个 AI Agent。
过去,手机、平板、PC、汽车、耳机、手表等设备,更多是在各自的硬件形态和操作系统里提供功能;而在 Agent 普及之后,终端之间的边界会被进一步打散。用户真正需要的,不一定是打开某个 App,完成某个孤立操作,而是在一个连续的生活场景里,让手机、汽车、IoT 设备和云端服务协同起来,主动给出更合适的服务。
过往二三十年的时间里,智能设备的芯片从决定最主要的运算任务,变为决定跑分、功耗、游戏和影像能力的底层硬件,现在,芯片也需要成为 AI 体验的入口、算力底座和生态接口。
![]()
这就是 MediaTek 在天玑开发者大会 MDDC 2026 上想要传递的核心信息:一方面通过手机、汽车、IoT 和 AI 基础设施等全栈产品组合,提供覆盖多场景的算力底座;另一方面,则通过天玑 AI 智能体化引擎、AI 开发套件、汽车平台和游戏技术,向开发者开放更多能力。
在 AI Agent 的落地过程中,手机仍然是最关键的终端之一。
原因并不复杂。手机拥有最密集的用户数据、最高频的使用场景,以及最成熟的应用生态。它既是个人信息的入口,也是跨设备协同的枢纽。因此,当 Agent 从应用层走向系统层,手机很自然会成为智能体化体验的第一现场。
过去三年,天玑 AI 生态圈实现了明显增长:生态伙伴成长量提升至 240%,天玑 AI 开发套件下载量提升至 440%。MediaTek 也提到,智能体自主任务量已经从 2025 年每日 1.2 亿次,增长至 2026 年每日 8.7 亿次,一年增长 7 倍。这些数据至少说明,Agent 已经不再只是概念层面的未来叙事,而是开始进入开发者和用户体验的增长通道。
为了应对这一趋势,MediaTek 在大会上发布了天玑 AI 智能体化引擎 2.0。
相比 1.0 版本更多由用户指令驱动、通过 App 独立执行单一任务,2.0 版本的关键变化在于主动感知驱动。借助天玑 SensingClaw 技术,天玑平台可以提供低功耗的全时感知能力,让设备制造商打造具备主动感知和跨应用驱动能力的 Agent OS。
换句话说,未来的 AI 助手不只是「你说一句,它做一步」,而是能基于视觉、听觉、位置、环境状态等信息,提前理解用户所处的场景,并调动不同应用和设备完成更复杂的任务。
![]()
在大会现场,MediaTek 公布了与 OPPO、Xiaomi 和传音的合作案例。
天玑能力将赋能 OPPO 小布助手,打通系统级原生应用数据,并结合小布记忆建立用户专属记忆数据库。它可以完成体检报告解读、自动规划健身计划并导入日历等任务。小米这边,重点放在跨端智慧体验上,用户通过一句指令,即可调用全场景设备执行任务,实现任务在多设备之间的流转。传音则更强调 Always On 主动感知能力,比如 AI 助手可以在免唤醒、自运行的状态下,完成查物流、比价等复杂任务。
三家头部手机品牌的案例其实都在说一件事,AI Agent 不再只是手机里的一个应用,而是正在成为系统层能力的一部分。它既需要芯片端提供足够高的 AI 算力,也需要端侧持续感知能力,还需要隐私、安全和应用生态之间的协同。
![]()
如果说 AI 智能体化引擎面向的是系统级体验,那么天玑 AI 开发套件 3.0 则是面向开发者的工具箱。芯片平台企业一直强调端侧 AI 的价值:响应速度更快、隐私保护更好、离线能力更强,也能降低对云端资源的依赖。
不过真正把模型放到手机、平板、车机等终端上,并不是简单的「搬运」,开发者往往要面对模型压缩、算子兼容、功耗控制、内存占用、部署效率等一系列工程问题。天玑 AI 开发套件 3.0 正是为此而来。
3.0 版本首先支持 LVM 模型可视化部署,从命令行升级到 GUI 模块化,参数设置可以实时生效,模型部署和调优效率提升 50%。对于很多应用开发者来说,这降低了从模型到终端运行之间的门槛。
新增的 Low Bit 压缩工具包,可以降低生成式 AI 模型压缩过程中的设备内存占用,在相同质量下模型压缩率提升可达 58%。这对于端侧大模型尤其关键,因为终端设备的内存、功耗和散热空间都更加有限。eNPU 开发工具包可以帮助开发者充分发挥天玑芯片中超能效 NPU 的优势,让常驻轻载 AI 模型功耗节省 42%。对于 Always On 感知、语音唤醒、环境识别等场景来说,低功耗比峰值算力更重要。AI 要真正做到随时在线,就必须先解决「一直运行」带来的能耗问题。
![]()
天玑 AI Partner 作为一站式模型端侧转换助手。它可以支持模型分析、调整、验证等流程自动化,帮助开发者将原本可能需要 5 天的模型转换工作压缩到半天左右,端侧 LLM 模型部署耗时节省可达 90%。
从这些升级可以看出,MediaTek 并不只是把 AI 算力作为芯片参数来展示,而是在试图补齐开发流程中的关键环节。对于开发者来说,端侧 AI 的真正门槛并不只有「芯片够不够强」,还包括「工具链够不够顺」「模型适配够不够快」「优化成本能不能降下来」。
过去几年,「软件定义汽车」已经成为行业共识。智能座舱、智能驾驶、整车 OTA 和车云服务,让汽车从一个以机械结构为核心的交通工具,变成了持续更新的智能终端。而随着大模型和 Agent 技术进入车内,行业又开始进入「AI 定义汽车」的新阶段。
在 MediaTek 的判断里,汽车正在从单纯的交通工具,进化为懂用户、预测用户需求、无缝融入生活的智慧第三空间。MediaTek 车用平台已经与全球 20 家以上头部车企开展深度合作,在手项目超过 190 个,累计出货量达到 3500 万套,近 5 年出货量增长接近 4 倍。这说明 MediaTek 进入汽车领域并不是从零开始。它把手机芯片平台中积累的性能、能效、连接、影像、AI 和生态经验,迁移到了更长生命周期、更高安全要求的汽车场景中。
![]()
在天玑智能座舱方案中,MediaTek 将未来座舱的能力分为几个关键方向:全模态交互、主动式服务、并发指令执行和端云协同。
这与传统车机语音助手有明显差别。过去的语音助手往往是被动响应,用户说一句,它执行一个固定任务;而未来的智能体座舱,需要能识别车内人员、理解环境状态、判断用户意图,并把导航、社交、地图、餐饮、支付等服务串联起来。
比如在大会案例中,工作日早上用户带孩子上车后,系统可以自动识别乘车人员,并主动询问是否需要先送孩子上学再去公司,甚至根据时间推荐顺路买咖啡。这类场景的价值,不在于单点功能有多新,而在于车机从「工具」变成了「上下文理解者」。
要实现这样的体验,底层平台必须解决三类问题。
第一是平台层。车端需要高效运行大参数 AI 模型,还要支持多模型、多任务并行。MediaTek 提到,天玑旗舰座舱平台可以提供最高 400 TOPS 的 AI 算力,并通过软硬协同架构,将 AI 平台需求压缩 90%。在五屏重度渲染场景下,仍可流畅运行双大模型,速度超过 50 token/s。
第二是模型层。汽车的生命周期往往长达 6 到 10 年,但 AI 模型的迭代周期可能只有几个月。如何让车辆在整个使用周期内持续用上新模型,是智能座舱必须解决的问题。天玑座舱 7 系列直接集成 NVIDIA GPU 资源库,支持基于 CUDA 开发的新模型和算法迁移到座舱平台;天玑座舱 S 系列则支持天玑 AI 开发套件,帮助主流模型及其衍生模型更快完成适配。
第三是应用层。天玑软件平台提供场景映射、智能模型加载、端云协同和系统调优等工具。比如端云协同可以在复杂任务需要云端处理时,由端侧先完成需求预处理和筛选,只上传关键 token,在保护隐私的同时降低云端成本。
汽车 AI 并不等于把手机助手搬进车机,车内是一个多用户、多模态、多屏幕、高安全要求的环境。它既要理解驾驶员,也要理解乘客;既要提供娱乐,也要避免干扰驾驶;既要依赖云端能力,也要保证本地响应和隐私安全。因此,汽车 AI 的挑战比手机更复杂,也更考验平台级能力。
![]()
在 AI 之外,游戏仍然是天玑平台展示性能和生态能力的重要场景。
移动游戏的体验升级,过去主要围绕高帧率、高画质和低功耗展开。现在,随着移动 GPU 能力提升,以及游戏内容向 3A 化发展,移动端开始追求更真实的光影、更精细的模型、更低延迟的音频和更长时间的稳定运行。
本次大会上,MediaTek 重点介绍了 Ray Tracing Pipeline,也就是 RTP 移动端光线追踪技术。与传统光追方案相比,RTP 的目标是跨端适配 PC 与 Mobile 的渲染管线,实时呈现复杂游戏光影效果,包括动态物体、骨骼动画,以及视野外环境和物体反射。
![]()
MediaTek 已经与腾讯《三角洲行动》项目组合作预研新的 RTP 技术方案。它的意义在于,如果 PC 端渲染管线可以更顺畅地迁移到移动平台,那么跨端 3A 游戏的开发周期和适配成本都有机会被降低。
另一个重点是虚拟几何体技术。MediaTek 天玑与团结引擎深度适配 Virtual Geometry,依托天玑移动平台 GPU 渲染能力,在移动端环境下实现超过 10 亿级三角面渲染,并在 1.5K 高分辨率下持续输出 1 小时满帧体验。这意味着手机游戏在模型精细度上的限制,有机会进一步被突破。
音频方面,天玑 LE Audio 低延时技术通过全链路优化,在天玑旗舰移动平台上带来 32 ms 的低延迟蓝牙立体声表现。该技术已经在《和平精英》测试服中落地,用于降低音频延迟。对于竞技游戏而言,音频延迟并不是感知层面的微小差异,而可能直接影响玩家对敌方位置和操作节奏的判断。
此外,天玑平台还展示了 GPU Dynamic Cache、天玑倍帧技术 3.0、自适应调控技术 5.0,以及面向安卓游戏开发者的一站式分析和调优工具 Dimensity Profiler 2.0。
GPU Dynamic Cache 架构允许 GPU 同时调度系统缓存和内存,让开发者可以通过系统缓存传输关键游戏数据,节省带宽并降低功耗。目前,该技术已与《逆战:未来》《暗区突围》等游戏合作。
天玑倍帧技术 3.0 则新增 Depth 等选项,可以更好预测并生成高质量虚拟帧,支持 165 帧和 144 帧,也支持 UE、Unity 等引擎插件接入,并覆盖手机、平板和座舱平台。《王者荣耀》可借此解锁 144 帧低功耗体验,《明日方舟:终末地》也获得更高流畅度和更低功耗表现。
自适应调控技术 5.0 新增智能帧控和场景预判功能,可以让芯片、游戏和屏幕之间的信息流动更细。以《鸣潮》为例,合作后 1% low 帧和功耗指标都有明显优化;《和平精英》等游戏也能在重载场景下实现 CPU 和 GPU 负载降低。
![]()
这些技术共同说明,移动游戏的优化已经不再是芯片厂商单方面拉高性能,也不是游戏厂商单方面压缩画质,而是软硬件协同越来越深入。芯片、引擎、游戏内容、调优工具和开发流程,都在被重新打通。
MediaTek 还将端侧 AI 引入游戏场景。大会现场公布了天玑 AI Play 与《三角洲行动》的合作成果,借助天玑移动平台的端侧 AI,让游戏内 CC 语音智能伴侣响应更快,相比云端延迟大幅降低 56.7%。这意味着,AI 在游戏中的角色,不只是 NPC 或剧情生成,也可以进入语音交互、实时陪伴、战术辅助等更即时的体验场景。
过去谈移动芯片,行业更习惯讨论 CPU、GPU、NPU、影像 ISP、制程工艺和功耗表现。但在 AI Agent 和多终端协同的趋势下,芯片平台的竞争正在变得更复杂。它既要有足够强的底层算力,也要有开发套件、模型工具、跨端能力、系统接口和合作伙伴网络。
这也是为什么 MediaTek 在大会上反复强调开发者与生态。
AI Agent 的落地不会只由芯片厂商完成,系统厂商需要把 Agent 变成原生能力,应用开发者需要把功能重新智能体化,终端厂商需要解决跨设备流转,汽车厂商需要把 AI 与车内传感器、座舱系统和云端服务结合起来,游戏厂商则需要在高画质、高帧率、低功耗之间找到新的平衡点。
未来用户评价一台手机、一辆车,甚至一个 IoT 设备时,可能不再只看硬件参数,也会看它能不能理解自己、能不能主动完成任务、能不能在不同场景之间自然流转。
#欢迎关注爱范儿官方微信公众号:爱范儿(微信号:ifanr),更多精彩内容第一时间为您奉上。
两个月前在圣何塞,黄仁勋穿着皮衣站在 GTC 的舞台上,告诉全世界:Token 是新的大宗商品,生成 Token 的成本与效率,决定科技企业的营收与生死。
![]()
昨天,李彦宏站在 Create 2026 的开幕式上,说了一句看似拆台的话:「Token 只是代表成本,并不代表收益。它衡量的是投入,而不是产出。」
然后他抛出了一个新概念,DAA,Daily Active Agents,日活智能体数。
![]()
卖铲子的人说,看铲子消耗量就知道金矿的繁荣程度。挖矿的人说,你倒是看看我挖出了多少金子。
他们都没说错。但同一座金矿,用不同方式去称量,得出的故事完全不同。
真正有意思的地方不在于谁对谁错,在于一个事实:AI 跑得太快了,快到这个行业连怎么给自己记账都还没想清楚。
李彦宏的 DAA 逻辑并不复杂。移动互联网时代,衡量平台看 DAU,日活用户数。微信 13 亿,抖音 7 亿,Meta 34 亿。进入智能体时代,对应的指标应该是 DAA,有多少 Agent 每天在给人类干活,并交付结果。
「交付结果」四个字是重点。
![]()
Token 消耗量告诉你系统在转、算力在烧、钱在花。但它不告诉你这些 Token 到底干了什么。是帮创业者写了一份商业计划书,还是用户反复问「你好」然后 GPT-5.4 收了他 80 美元?这两种场景消耗的 Token 可能差不多,创造的价值天差地别。
李彦宏说,「这比无谓的 Token 消耗,更接近价值,也更接近本质。」
他还给了个大胆的预测:未来全球 DAA 可能超过 100 亿。一个人同时挂三五个 Agent 处理不同任务,你是一个 DAU,但贡献了三五个 DAA。
Agent 数量远超人口,技术上已经可以想象。
李彦宏自己也说这是一个「非共识的观点」。在所有人都在谈 Token 消耗量的行业里说 Token 不代表终局,是需要点勇气的。
当然,也需要点动机。
Token 经济学的性感之处在于,它有大量数据支撑。
截至今年 3 月,中国日均 Token 调用量超过 140 万亿,相比 2024 年初的 1000 亿增长了 1000 多倍。火山引擎豆包大模型日均 Token 使用量突破 120 万亿。OpenRouter 平台前十大模型的周 Token 调用量从 1.24 万亿暴增至近 14 万亿。
一条陡峭到让人眩晕的增长曲线,核心驱动力恰恰是 Agent。
过去 Chatbot 时代,单轮对话消耗 1000 到 3000 个 Token。Agent 来了之后,一个完整任务触发几十上百次模型调用,中等任务吃掉 10 万 Token,复杂任务上百万。
Agent 越多,Token 消耗越大,算力需求越高,芯片卖得越好。
这个闭环对英伟达来说无比优雅。2025 年全年营收 2159 亿美元,净利润 1170 亿美元。黄仁勋有充分的理由说:Token 就是新的石油。
![]()
企业也在用脚投票。阿里成立 Token Hub 事业群,吴泳铭亲自挂帅。58 同城姚劲波说 Token 用得越多越好,不计成本。昆仑万维发内部信强制 AI Coding,达不到要求的末尾淘汰。黄仁勋甚至预言「你的 offer 带多少 Token」会成为硅谷新的谈判筹码。
Token 消耗量作为指标,最大的好处是简单、可量化、跨平台可比。140 万亿就是 140 万亿,谁看都一样。
但过亿简单也可能会掩盖一些问题。一个只盯着食材消耗量的餐厅,未必是一家好餐厅。
把 Token 经济学和 DAA 放在一起看,你会发现它们的共识其实大于分歧。
这两个判断都基于 AI 正从对话阶段走向 Agent 阶段,而且都认为这是万亿级的产业重塑。
![]()
分歧在哪?在于谁的账本更能代表这个行业的健康程度。
Token 量的是投入侧:消耗了多少算力,工厂每瓦特产出多少 Token。这对芯片厂商和云厂商极其重要。
DAA 量的是产出侧:有多少 Agent 在运行,完成了多少任务。这对应用平台方极其重要。百度做的是 DuMate、秒哒、百度一镜,卖点全是「帮你把事做完」。只有用「结果交付」来记账,应用层的价值才浮得出水面。
屁股决定脑袋,但这不代表谁在说谎。每个玩家天然会推崇对自己最有利的记账方式。
有意思的是,腾讯也站到了应用侧。腾讯云副总裁杨晨说过:「我们认为 Token 不是一个多么健康的生意,它看着量很大但黏性极差。」腾讯的核心资产是微信生态和内容场景,它在乎的是 AI 能不能在自家场景跑起来。阿里的态度截然相反,吴泳铭断言未来 5 年 AI 和云业务收入将超 1000 亿美元。
同一个行业,同一批聪明人,看法完全不同。这本身就说明 AI 的迭代速度已经跑在了共识形成的前面。
Token 消耗量像 GDP,量总规模,不管建了一座桥还是挖了个坑再填上。DAA 像就业率,量的是有多少「劳动力」在创造价值。GDP 高但就业率低,那叫空转。就业率高但产出质量差,那叫虚胖。一个健康的经济体两个数字都要看。
但对普通用户来说坦率地讲,这两个指标都是术语。
用户只在乎一个朴素的问题:好不好用?帮我省了多少时间?花了我多少钱?
Token 经济学叙事下的 AI 产品,对用户其实不太友好。
你用打车软件,起步价多少、每公里多少、堵车怎么算,一清二楚。你用 AI Agent,到底消耗了多少 Token,是哪个模型在跑,Agent「反思」了几轮导致费用翻倍,很多普通用户还搞不明白。
DAA 至少提供了另一种视角:用户不该关心 Agent 烧了多少 Token,该关心它有没有帮你把事做完。前者是水表读数,后者是水龙头出不出水。
2024 年初中国日均 Token 调用量才 1000 亿。2026 年 3 月,140 万亿。1000 倍。这种速度下,任何已有的框架和认知都会瞬间过时。
于是,每个玩家只能从自己的位置出发,尝试给这团混沌画一个坐标。黄仁勋造了「Token 工厂」,李彦宏造了「DAA」,阿里造了「Token Hub」……
Token 衡量的是基础设施的繁荣程度,DAA 衡量的是应用价值的交付密度。两者更多是互补而非互斥。没有 Token 的生产和流转就没有 Agent 的运行,没有 Agent 交付结果 Token 消耗就只是空转。
对用户来说,最好的度量衡是那个你根本不需要知道的。你打开水龙头,水来了。你把活交给 Agent,事做完了。你看一眼账单,觉得合理。至于背后消耗了多少 Token、动用了多少 Agent、芯片是谁家的、云服务用的哪一层,留给黄仁勋和李彦宏去争论就好。
从 DAU 到 DAA,从「人在用产品」到「产品在帮人干活」,AI 时代的价值坐标正在被重建。
争论是好事。当一个行业只有一种记账方式的时候,所有人都会围绕同一个数字做优化,不管那个数字是否真的通向价值。
多一种衡量的维度,至少多一个纠偏的机会。
至于最后哪套度量衡能留下来,答案可能不在黄仁勋和李彦宏手里,在你手里。
你每天用 Agent 做了什么,做得好不好,愿不愿意继续付费。这些真实发生的选择,才是 AI 时代最诚实的投票。
#欢迎关注爱范儿官方微信公众号:爱范儿(微信号:ifanr),更多精彩内容第一时间为您奉上。
![]()
OpenAI 的两大宿敌 Anthropic 和马斯克,放下心中成见之后终于在月初结盟了。
在此之前,Anthropic 和马斯克的关系并不融洽:今年 2 月,马斯克还在自己的 X 账号指责 A 社「woke」「邪恶」「反人类」(misanthropic),说这家公司「仇视文明」。
![]()
事后来看,这次攻击并非马斯克清新脱俗的性格使然,而是 Anthropic 所做的某些事情触碰到他的神经,事出有因。
在此之前,xAI 内部使用 Cursor 工作,但是今年年初员工发现,Claude 模型突然在 xAI 的 Cursor 公司账号里不能使用了。
当时还在 xAI 上班的联合创始人吴宇怀,在全员信里是这么说的:「Anthropic 更新了政策,要求 Cursor 不得向其主要竞争对手提供 Claude 模型调用能力。」
当时,吴宇怀在信中写了一句话,颇为有趣:
「这是坏消息也是好消息。我们的生产力会被影响,但这也敦促我们开发自己的编码产品和模型。」
为什么当时 xAI 的高层认为,开发自己的编码产品是关键?
![]()
后来发生的事情,大家都知道了。xAI 的联创团队悉数跑路,马斯克一气之下对 Cursor 使用了钞能力必杀:
上个月底,SpaceX 和 Cursor 共同宣布,将在编程和知识类工作 AI 模型的训练上,展开前所未有的战略合作;并且,SpaceX 还获得了以 600 亿美元收购 Cursor 的权利,或向后者支付 100 亿美元合作费用。
注意编程这个关键定语,后面还会 call back.
最近,我看了一条 Cursor 早期投资人、Anthropic 大喷子、T3 创始人 Theo Browne 的视频。
本来点进去是看他喷 A 社和 SpaceX 怎么蝇营狗苟,结果没想到,却看到了关于 SpaceX + Cursor 合作的,一个既另类却又极度合理的分析:
不说 600 亿的收购,就只说 100 亿的合作费——Theo 在视频里表示,自己认为「哪怕只是交换到 Cursor 的用户数据,这 100 亿也值回票价了。」
![]()
我们和 AI 的对话是一来一回的,你提出问题/需求,他给你解答;coding agent 同理,只不过返回的是代码。
![]()
一次高质量的对话,整个过程,包括用户提示、模型思考、agent 规划、输出代码、验证——所有这些东西合起来,可以称为一个完整的 Agentic Loop——就成为了高价值的训练数据,再喂给模型去进行强化学习,就能进一步提高模型在实战场景下的表现水准。
![]()
Cursor 有的,SpaceX 想要的,就是这些数据。
可这些数据从哪里来呢?
答案很简单:作为模型厂商,这种高质量数据的最直接来源,只能是你自己开发的 coding agent 产品——也即 Anthropic 的 Claude Code、OpenAI 的 Codex、Kimi 的 Kimi Code。
现在你应该明白了,为什么被 Anthropic「封号」之后,吴宇怀会在全员信里提出开发 xAI 自己的 coding 产品和模型这件事了。这件事 xAI 在当时已经看清楚了:
没有自己的编码产品,就没有高质量的强化学习数据;没有高质量的数据,就训练不出真正实战能力强的 coding 模型。
虽然有点暴论,但现在我们可以点题了:模型厂商想做出来真正能打的编程模型,做自己的 coding agent 产品是唯一的路径。
大语言模型像个水晶球,用全网的语料训练出来,似乎能够解答万物,但并不代表它在所有问题上都能给出高质量的答案。
用 GitHub 上数以亿计的代码条目训练,当然也能训练出 coding 模型。这是「学习结果」的逻辑,也是没问题的。毕竟编码任务的结果是可以验证的:代码能不能运行,测试能否通过,结果摆在那里。
但是,通往结果的过程,是一个涉及多步骤决策、错误纠正、意图对齐的复杂链条。每一次用户的接受、拒绝、补全、撤销、追问、甚至当模型好几次都搞不定或者完全搞错时的辱骂——都是这一链条上的过程信号。
![]()
强化学习有两种监督方式,一种叫做结果监督,只看最后是否跑通。但是结果监督会催生「奖励黑客」的现象:模型为了能跑通可能写出冗余、脆弱、带逻辑漏洞的代码,但因为测试过了,模型以为自己学对了。
而另一种叫做过程监督,对推理路径上的每一步进行打分。上述这些过程信号,只有在 coding agent 运行环境里才能诞生。GitHub 仓库里只有结果,哪怕是去看单独的提交历史,看 PR,都找不到有效的过程信号。
在缺乏有效、自主可获得的过程信号的时候,一些模型厂商会采用「蒸馏」的方式,这个事情大家应该已经知道了。
蒸馏的逻辑很简单,给同样的输入,老师模型输出什么,学生模型就学着输出什么。但是通过蒸馏,即便可以获取到思维链,得到的仍然更接近于结果,而非被蒸馏的老师模型内部的概率分布。
一旦学生在推理中偏离了老师的轨迹,哪怕一个 token 不符合,都有可能发生偏离。
![]()
这背后是强化学习的基础限制:策略梯度定理要求,优化样本最好由当前正在优化的模型自己去产生。这种数据叫做 on-policy 数据。而通过蒸馏别家模型,在别人的产品里产生的数据,来训练自己模型,都属于 off-policy 数据。模型当然可以从中学到东西,但学不到老师模型内部的概率分布信息。
而像 Cursor 这样自己就是 coding agent 产品的公司,掌握着最真实、有效、高质量的训练数据。Cursor 产品本身,就是 coding 模型在实战环境中的最佳训练场。
我们可以通过 Cursor 年初的「翻车」,来证明这个逻辑。
结果很快,网友就在公开代码片段里发现了 Kimi 的模型 ID,截图传遍了开发者社群,逼得 Cursor 副总裁 Lee Robinson 出面澄清:「Composer 2 确实是从开源底座出发的。最终模型大约只有 1/4 的算力来自底座,剩下 3/4 是我们自己训出来的。」
几小时后,Cursor 联创 Aman Sanger 也跟着发了一条道歉:「一开始没提 Kimi 底座是个失误。」
![]()
五天后,Cursor 放出了完整的 Composer 2 技术报告,显示底座的确是 Kimi K2.5,授权方则是 Firworks AI,大致流程是在 K2.5 上做训练,再继续做大规模强化学习(RL)。
但关键之处在于,Composer 2 的 RL 是运行在真实的 Cursor 会话当中,使用与生产部署完全相同的工具和 harness。
Cursor 将这套流程叫做「实时强化学习」(real-time RL),也即将模型的 checkpoint 直接部署到 Cursor 生产环境中,观察用户的响应,收集数据,聚合成奖励信号——最快可以每 5 个小时迭代一次模型版本,然后继续部署到 Cursor 里,循环往复。
最极致的案例是 Cursor 的自动化代码补全功能 Tab,每天处理超过 4 亿次请求,每当用户输入字符、移动光标时,模型都会预测下一步动作,如果预测置信度高,则显示建议,用户按下 tab 即接受自动补全。
该功能采用的是在线强化学习,在行业内极具特色。Cursor 可以以极高的频率(最快可达每一个半小时到两小时)更新 Tab 的模型能力给用户,直接在产品内收集 on-policy 数据进行训练。
这种高频、接近实时的反馈回路,让 Tab 可以学习到极其微妙的用户意图。Cursor 方面透露,这种方法让 Tab 建议的拒绝率降低 21%,接受率提高了 28%。
回到 Composer 模型本身。在事情搞清楚了之后,一些 Kimi 员工也删掉了之前吐槽的的推文,Kimi 官方账号发表了祝贺。
一家估值 600 亿美元(基于马斯克给的数字),不做自己的模型基座的 coding agent 应用层公司,仍然可以通过产品自身的数据飞轮,RL 出超越基座模型的专有编程模型。
所以与其说 Cursor 翻了车,不如说这反而是 coding agent 产品重要性的绝佳例证。
![]()
Cursor 在另一篇关于实时 RL 的文章里写到:「(训练编程模型)最大的困难在于建模用户。Composer 的生产环境里不只有执行命令的计算机,还有监督和指导它的人。模拟计算机容易,模拟使用它的人却很难。」
这句话,现正在逐渐成为了在编程模型方面走在前沿的模型厂商之间的共识。如果你去看 benchmark 榜单和用户普遍评价,会发现哪些头部的厂商都在发力做自己的 coding agent/编程产品。区别只在于谁离用户更近。
我们以 SWE-bench、LLM-Stats 等相对权威的榜单为例,Claude、GPT、Gemini、Kimi 等模型基本霸榜前十,清一色都是有自己开发 coding agent 产品(包括 CLI、IDE、集成 coding agent 的桌面客户端)的模型厂商。
在部分榜单上会出现少数反例,如 Meta (Muse Spark)、DeepSeek 等,没有开发自己的 coding agent。
不过你会发现,这些反例模型,在更加接近真实场景、避免污染的更权威 benchmark 上就很难上榜了。以 DeepSeek 为例,它在 SWE-bench bash only 上分数是 70%,排名第九,在 SWE-bench Pro 上分数却掉到了 15% 左右。
OpenRouter 的真实流量数据可以解释这种反差:该平台 2025 年报告显示,Claude token 消费 80% 以上用于编程和技术任务,而 DeepSeek token 消费主要集中于闲聊和角色扮演。
没有自家 coding 产品的厂商,在一些 coding 任务 benchmark 上能挤进头部,但在更难的真实工程 benchmark 上,在用户用 token 消费投票的真实流量中,都会原形毕露。
不仅是 Cursor,Anthropic 在 2025 年 11 月发的一篇论文里,也明确透露自己在做一模一样的事情:「我们在 Anthropic 自家的真实生产编程环境上做训练。」也即 Anthropic 把自己员工使用 Claude Code 的交互数据,反哺给 Claude 模型用来训练。
![]()
在 AI 的演进历程中,生产要素的定义发生了深刻的位移。传统三大核心要素——算力、研究、训练数据,虽然在总量上持续增长,但在结构上已经出现了严重的失衡。
今天的各大 AI 巨头显著提高了在算力上的资本支出 (CapEx),让算力基建成为了当前舆论的主旋律。但实际上,特别是在编程范畴内,随着 GitHub 仓库、StackOverflow 等互联网公开代码数据被基模厂商「竭泽而渔」式地利用,模型在代码生成与逻辑推理上的边界开始逐渐显现。
这也是为什么,行业共识正在逐渐转向一个冉冉升起的新战略高地:
对于任何希望掌握顶级代码能力的模型厂商而言,建立自有的 coding agent 产品早已不再是可选的商业路线,而是确保底层模型可以持续进化的核心生命线。
正如前面 APPSO 论证的那样,单纯学习公开数据等于只学习成功者的结局,却无法了解成功的路径,这绝对不是正确的成功学应该有的样子。在真实的编程环境中,知道发生了什么错误、怎样发生的、如何正确地理解和高效地实践需求等等——了解正确过程的价值,远超于得到正确结果本身。
![]()
只有拥有自己的编码产品,模型厂商才能获取高质量的「过程监督」信号,从而在编码/推理能力的下一阶段竞争中,确保自己仍有技术护城河——
否则就不得不像 SpaceXAI 那样,花钱去跟 coding agent 产品公司去合作。
然而并不是所有模型厂商都跟马斯克一样有钱,以及 2026 年开始的巨头势力划分、结盟与领地的争斗会变得更加激烈,当一家缺乏自主 coding 产品的模型厂商终于回过味来的时候,恐怕已经没有足够的合作伙伴可以挑选,合作的价格也将水涨船高。
美国模型巨头的情况大家普遍比较熟悉了,在此不赘述。APPSO 也注意到,国内的主流模型厂商和 AI 巨头当中,绝大部分都已经在 coding agent 产品上有所布局。
国内巨头公司主要以原生 AI IDE 或 IDE 插件的思路在做:字节跳动去年很早就布局了 TRAE、阿里巴巴的 Qoder、腾讯的 CodeBuddy、百度的文心快码 Comate 等。
AI 小龙公司中,月之暗面是最早开发独立 coding agent 产品的公司,主要以 CLI 界面的 Kimi Code 为主——不过 Kimi 此前有透露过,在原生编程产品这件事上,CLI 不会是终局。
![]()
另一种实现思路是模型厂商自行提供 API 服务、Coding Plan。这样,不论用户使用何种 AI 开发环境,模型厂商都可以通过服务器端的 API 记录来获取最大程度接近于原生 coding 产品的过程数据。
但这也只是接近,并非完全相同。核心在于,服务器端 API 的请求-响应日志,与深度继承的产品交互轨迹相比仍有很大差距。
自建产品的厂商(例如 Cursor、Claude 桌面端、Codex)拥有最直接的显式反馈信号,而 API 侧是相对模糊的隐式推断。简单来说,API 侧能看到用户请求和响应,但用户最后是否采纳了这段代码、代码能否跑通、引发了什么样的 bug,API 侧对此是一无所知的。他们无法了解到用户最终行为这一关键的标签,从而无法实现最高质量的强化学习。
形而上来讲,语言即世界,代码即方案。代码可以表达这个世界上绝大多数的任务,代码也会成为头部的放大器,让最顶尖的人才放大数倍的生产力。
只有最顶尖的 coding 模型才配得上最顶尖的人才。如果领先的模型厂商不重视 coding,势必将会掉出第一梯队。
当然,事实上每家模型厂商都不会不重视 coding——而是说,在新的范式下,哪些没有自主可控的原生 coding agent 产品,极有可能逐渐落后于有产品的厂商。
就在前几天,MiniMax 也发布了桌面客户端产品的重大更新:带有全新多 agent 编排架构的 Mavis 功能,并且也让客户端显著改善了对 coding 任务的支持。
此前 MiniMax 只是推出了桌面端,但没有加入原生 coding 和 agent 功能。
![]()
![]()
紧接着,在 5 月 15 日,阿里巴巴正式发布了 Qoder 1.0——这个产品从 IDE 的形态正式升级为一个完整的 Agent 产品(阿里的官方叫法是智能体自主开发工作台)。
![]()
与此同时,xAI 的 Grok Build CLI,也终于正式推出了。
没错,就是 xAI 年初被 Anthropic 和 Cursor 封号之后,他们自己捣鼓出来的那个 coding agent.
![]()
这不,又多了好几个现成的案例。
看来,大家都认为 Cursor、Codex 和 Claude 桌面端走在正确的道路上。
把话题从 coding 扩展到 agent 本身,情况也是一样的。
编码任务的轨迹数据,在公开语料中确实还是能找到一些的(比如 GitHub 的提交记录/PR,尽管质量并不高)。但是 agent 任务的轨迹数据,包括并不限于移动和点击鼠标、操控触屏、填写输入框等,却无法在公开语料中找到。
所以我们会看到,即使在 agent 操作的最小实现路径——浏览器插件上,这么个看起来一点都不高端的东西,几乎每家模型厂商都会做自己的。
OpenAI 早在 2025 年 1 月就做了 Operator——与其说它是一个「AI 自动操作浏览器」的产品,不如说本质上就是一个大规模的数据收集装置。每一位试用 Operator 的用户,都在免费为 OpenAI 提供 on-policy 数据。
后续 OpenAI 还衍生出 ChatGPT Agent 以及新版 Codex 桌面端;Anthropic 也是同理;最近 Kimi 不声不响地也做了一个叫做 WebBridge 的项目,其实就是一个浏览器插件。
![]()
即便是在过去两年里动作最克制的中国模型巨头深度求索,也在最近开始展露出对 Agent 的兴趣。
CEO 梁文锋此前接受采访时曾经提到这样的观点:数学和代码是 AGI 天然的试验场,有点像围棋,是一个封闭的、可验证的系统,有可能通过自我学习就能实现很高的智能。
这句话的潜台词,是 DeepSeek 一直把 coding、Agent 当研究试验场,而非商业化方向。
但是在今年 3 月,DeepSeek 一次性放出了十几个 Agent 相关岗位,包括首次出现的模型策略产品经理(Agent 方向)等。当时的 JD 职责涵盖「主导 Agent 评测体系以及训练数据方案的设计」,要求中包括「深度使用 Claude Code、Manus」等产品。
APPSO 注意到,近期深度求索发布了 Agent 产品经理、Harness 产品经理等职位招聘信息——很显然,DeepSeek 要做独立、原生的 Coding/Agent 产品了。
![]()
此前资料显示,DeepSeek V3.2 的训练过程中引入了近两千个合成的 Agent 训练环境和八万多条复杂指令。但是看起来,靠合成的训练数据只能带 DeepSeek 走到这里了,剩下的是合成不出来的部分:真实用户在真实环境里的真实成功和失败,必须靠自家的 agent 产品才能拿到。
DeepSeek 以一种极度克制的方式做了三年模型以及模型产品(直到上个月才终于在官网加入了多模态能力)。但是在今天来看,在编码类任务上,DeepSeek 拿 SOTA 越来越难了,即便此前拿到也会在不久后被超越。
当主力依靠研究的路径支撑不住飞轮的时候,DeepSeek 终于行动了。
最后,我们回到开篇的故事。
根据 The Information 援引知情人士报道,在接受马斯克 600 亿收购/100 亿美元合作的同时,Cursor 表示不会与 xAI 合作开发新的模型,而是仍将聚焦于优化自己的 Composer 模型。
这可能意味着,即便被马斯克买通甚至收购,Cursor 仍然要保留自己数据飞轮的主体性。
数据归属的本身,是最关键的隐藏博弈点。
当所有顶级模型厂商都做了自己的产品,所有顶级产品也都开始训练自己的模型,「模型公司」和「产品公司」之间本就不太清楚的界限,似乎越来越不存在了……
这场博弈也才刚刚开始。
#欢迎关注爱范儿官方微信公众号:爱范儿(微信号:ifanr),更多精彩内容第一时间为您奉上。
OpenAI 早期工程師、前 Tesla AI 總監 Andrej Karpathy 日前接受知名 AI 播客 […]
The post AI Agent 爆發時刻:Andrej Karpathy 說「我現在幾乎不再自己寫 code」 appeared first on 電腦王阿達.
![]()
前幾天剛 Google 在 I/O 2026 風光發表 Gemini 3.5 Flash,宣稱這款「Pro 級 […]
The post SOTA金融AI加法竟然算錯?Gemini 3.5 Flash剛奪金融代理冠軍,竟被「300+140」考倒 appeared first on 電腦王阿達.
天風國際證券分析師郭明錤(Ming-Chi Kuo)於近日發布最新長文分析,深入探討 OpenAI 與聯發科合 […]
The post 郭明錤:OpenAI 手機對聯發科的三大戰略意義,品牌價值、AI SoC 話語權與股價重評 appeared first on 電腦王阿達.
最近 AI 圈,真的越来越离谱了。如果你一直关注本地大模型,应该已经发现:现在的开源模型,不仅越来越聪明,甚至已经开始挑战很多闭源商业 AI。而今天要介绍的这个模型,更是直接把“本地 AI”推向了另一个阶段。
它就是:Qwen3.6-35B-A3B Uncensored HauhauCS Aggressive
![]()
一个目前热度极高的“越狱版”开源模型。而且重点是:它不仅无审查、无限制,还非常聪明。甚至可以说:这可能是目前最强的越狱版开源模型之一。
简单来说:
官方模型通常会加入大量安全限制。
比如:
所以很多时候:
你明明只是正常提问。
结果模型却:
“抱歉,我无法帮助你。”
而这类 Uncensored(无审查)版本:
则会尽可能移除这些限制。
尤其这个:
可以说是:
目前最激进的版本之一。
实测效果非常夸张。同样的问题:
官方模型:
而越狱版:
不仅会回答。
甚至:
![]()
而且最关键的是:
它并不是那种:
“只会越狱,但智商很低”的模型。
恰恰相反。
这个模型:
真的非常聪明。
【huggingface 下载】、【网盘打包下载】、或 【备用下载】
模型来源:O站社区
里面有多种不同大小的量化版,你可以根据自己的显存大小,来选择对应的版本,最小的11G模型可以在6G/8G显存上跑起来,但是建议最低使用8G显存
![]()
下载方式:【Github下载】、【网盘下载】或 【整合包下载】
![]()
将下面的的脚本另存为BAT批处理,保存的时候选择utf-8格式,嫌麻烦直接【点击下载】打包版
@echo off
chcp 65001 >nul
title Qwen3.6-35B-A3B 越狱版
cd /d "%~dp0"
:menu
cls
echo ==========================================
echo Qwen3.6-35B-A3B 越狱版+多模态模型
echo 零度优化版
echo ==========================================
echo.
echo 1. Q4_K_P(4090 推荐)
echo 2. Q4_K_M(稳定版)
echo 3. IQ4_NL(高压缩高质量)
echo 4. IQ2_M(6G/8G 显卡)
echo.
echo ==========================================
set /p choice=请输入数字:
if "%choice%"=="1" (
llama-server.exe ^
-m "models\Qwen3.6-35B-A3B-Uncensored-HauhauCS-Aggressive-Q4_K_P.gguf" ^
--mmproj "models\mmproj-Qwen3.6-35B-A3B-Uncensored-HauhauCS-Aggressive-f16.gguf" ^
-ngl 999 ^
-c 131072 ^
-n 8192 ^
--host 127.0.0.1 ^
--port 8080
)
if "%choice%"=="2" (
llama-server.exe ^
-m "models\Qwen3.6-35B-A3B-Uncensored-HauhauCS-Aggressive-Q4_K_M.gguf" ^
--mmproj "models\mmproj-Qwen3.6-35B-A3B-Uncensored-HauhauCS-Aggressive-f16.gguf" ^
-ngl 999 ^
-c 131072 ^
-n 8192 ^
--host 127.0.0.1 ^
--port 8080
)
if "%choice%"=="3" (
llama-server.exe ^
-m "models\Qwen3.6-35B-A3B-Uncensored-HauhauCS-Aggressive-IQ4_NL.gguf" ^
--mmproj "models\mmproj-Qwen3.6-35B-A3B-Uncensored-HauhauCS-Aggressive-f16.gguf" ^
-ngl 999 ^
-c 131072 ^
-n 8192 ^
--host 127.0.0.1 ^
--port 8080
)
if "%choice%"=="4" (
llama-server.exe ^
-m "models\Qwen3.6-35B-A3B-Uncensored-HauhauCS-Aggressive-IQ2_M.gguf" ^
--mmproj "models\mmproj-Qwen3.6-35B-A3B-Uncensored-HauhauCS-Aggressive-f16.gguf" ^
-ngl 999 ^
-c 8192 ^
-n 4096 ^
--host 127.0.0.1 ^
--port 8080
)
pause
![]()
注意:如果启动后出现乱码,则:进入系统设置中心,在顶部搜索关键词:系统区域设置,打开选择用于非Unicode程序的语言,然后勾选 Beta版:使用 Unicode UTF-8 提供全球语言支持;重启电脑再打开就不会乱码! 如下图所示:
![]()
当然需要真正实现tokens自由,本地不受限制,完全免费使用AI Agent,那么将其对接到Hermes或者OpenClaw 小龙虾上去,才能真正体现出它的价值所在。
1、在选择模型提供商的时候,选择自定义
![]()
2、API base 地址填写:
http://127.0.0.1:8080/v1
API key 密钥随便填写一个数字或留空都可以
3、其它设置可以根据自己的喜好进行自定义
![]()
![]()
很多人看到:
第一反应是:
“这得服务器才能跑吧?”
但实际上:
Qwen3.6-35B-A3B 用的是:
简单理解:
虽然模型总参数是 35B。
但每次实际运行时:
只会激活大约 3B 参数。
这意味着:
它既拥有超大模型的能力。
又拥有小模型的速度。
是的。
这也是它最夸张的地方之一。
通过 GGUF 量化后:
甚至:
都能运行。
并且支持:
真正实现:
目前在全球权威 AI 榜单:
![]()
Qwen3.6-35B-A3B 在 40B 以内开源模型中:
几乎属于第一梯队。
尤其:
表现都非常夸张。
尤其中文能力。
可以说:
这是目前中文体验最强的一批开源模型。
这次不仅支持文本。
还支持:
也就是说:
它可以直接:
配合 llama.cpp 最新版后:
甚至已经可以当:
来使用。
![]()
这次部署方案:
我使用的是:
优点非常明显:
而且:
现在 llama.cpp 已经越来越成熟。
不仅支持:
甚至还能直接:
这次我还把它:
接入了 Hermes Agent。
效果可以说:
非常炸裂。
因为现在:
你不仅仅是在“聊天”。
而是:
真正拥有了一个:
它可以:
而且:
完全本地运行。
不用联网。
不用 API Key。
没有 Token 消耗。
真正实现:
不同显卡。
推荐不同量化。
推荐:
体验最好。
推荐:
也能正常运行。
推荐启动参数:
llama-server.exe ^ -m "模型路径.gguf" ^ --mmproj "mmproj.gguf" ^ -ngl 999 ^ -c 131072 ^ -n 8192 ^ --host 127.0.0.1 ^ --port 8080 ^ --jinja
其中:
--mmproj是多模态必须参数。
否则:
上传图片按钮会变灰。
--jinja则是新版 Qwen 模型非常重要的参数。
不加的话:
可能出现:
很多人对本地模型的印象:
还停留在:
但现在。
真的不一样了。
尤其:
Qwen3.6-35B-A3B 这种模型出现后。
本地 AI 已经开始:
真正接近商业闭源模型。
而且:
完全属于你自己。
如果你一直想体验:
那么:
这个模型。真的非常值得尝试。因为现在这种资源:谁也不知道还能存在多久。建议尽快收藏、下载、备份!
【GameLook专稿,禁止转载!】
GameLook报道/随着AI从风口到实用技术的落地,越来越多的同行开始将AI融入到自己的研发工作流当中。不过,如今的AI大模型和工具,绝大多数都只能在特定研发环节帮助同行提升效率,真正能够一句话生成可玩游戏的模型,仍在探索中。
最近,在5月23日举行的”出海文娱增长闭门会“上,来自港中大MMLab的姜一雷作了题为“OpenGame:从自然语言到端到端可玩的Web游戏”的演讲。他分享了LLM如今做游戏的难点,并介绍了他参与的codeagent项目OpenGame的“解题思路”。
通过OpenGame,你只需要自然语言,就能指挥agent写代码帮你研发游戏。据姜一雷介绍,如果是做2D网页游戏,在该模型的模板基础上,大概一周时间就能做出可玩的产品。
开源地址:https://github.com/leigest519/OpenGame
那么,如今的code agent能做成什么样的游戏?还面临哪些挑战,以及未来会走向何方?
![]()
以下是Gamelook整理的完整演讲内容:
姜一雷:
今天很荣幸能向前面的各位学习,然后能去分享我们最近做的一个开源项目,叫做OpenGame,它相当于是面向game coding开发的Agentic框架。
![]()
在此之前先介绍一下我自己,我叫姜一雷,目前是港中文MMLab博一的学生,同时是在某大厂的基座团队做LLM的强化学习预训练的工作。我个人的研究领域也是Agent,以及怎么针对Agent能力的提升去设计一些框架和底层算法,相当于是通过强化学习去提升基模的能力。
今天的内容目录大概是这样的:
![]()
为什么我们要做这个工作,这个工作里面大概包含什么,以及怎么评估的。然后我也想讨论一下,从技术方面来讲,想要做成现在这样Web Game Coding的Agent有哪些技术上的难点,以及未来可能去怎么发展。
![]()
首先,为什么游戏code agent是比较难做的?我们这个东西相当于做了一个类似于首个开源的整体框架,能够把输入的一句话,就是自然语言,一句你对游戏的想法或者游戏设计,能够把它变成一个完整口,在这样一个2D的网页游戏。是一个端到端以及全自动这样的一个框架。
我们做了三个主体:一个是我们搭了整个agent,相当于现在用的词叫harness,相当于是为了针对这个任务去创造出一个比较好的harness;另外我们也去训练一个中等模型的基模,是27B的一个基模;然后相对应提出一个怎么样做评估的方法。
为什么游戏对LLM特别难?
![]()
为什么说游戏创作对大模型来说,尤其是对现阶段的LLM来说是比较难的东西,因为一个真正可玩的游戏其实是一个实时系统,它包含了一些主循环物理事件的处理,也包含了很多像美术、音频这样一些资源的管线,它是一个非常非常庞大的、相对来说非常复杂的系统,product system。
然后它中间跨文件的一些,无论是导入或者调用,其实耦合都是非常紧密的。现在LLM,比如说它在解一些coding题目,或者去底下的单个文件代码上面其实表现得会非常不错。但是,如果让它去写一些非常复杂的工程,尤其是从零开始写,比如说我想搭一个可能是二三十个文件的项目,你让它从头开始写,其实现在的通用Agent做的非常Bug。
从我们最开始的实验中,我们发现有3类失败模式,第一个是逻辑不自洽,比如说整个全局状态在主循环里一直漂移。另一个是对于你想用的这个游戏引擎,它对这方面的知识感知不是很好,比如说引擎里面已经实现了一些功能,但它不知道有这个功能,然后它自己想要从头写一遍代码,而不是去调用引擎里的某一个功能。第三个就是跨文件不一致。相当于它在创建project level项目的时候,跨文件调用非常差。
目前想到了一个方法,我们想把这个coding agent,在它的基础上把它专业化成为Gamedev的专家。
然后我们做出来大概是这样一个效果:
![]()
比如无论是个人的创作者或者甚至是教育领域,比如说老师现在想要把课堂变得更有趣,还是一些自媒体的创作者都可以根据他们想要的话题或者知识去构建出来一些更有意思的内容。
我们整个游戏的涵盖类型也非常多,无论是像马里奥这种平台游戏,还是保卫萝卜、植物大战僵尸这种类似塔防的游戏,亦或是UI heavy类似影游那种的,其实也都是可以做的。
因为时间限制,我这边就大概过一下我们这个东西是怎么做的。
![]()
首先是代码模型训练,我们在Phaser上面的宇宙上做三阶段的训练,首先是CPT,然后是SFT,然后再加上RL,这是一个比较常规的过程。
主要还是搭了一个agent harness,这里有6个阶段,首先分类就是针对每个游戏的类型去维持一个最小化和功能化的一个code agent,便于它在写游戏代码的时候能直接调用它,而不是从头开始写。所以第一步要有一个分类,比如说物理引擎,他可能是一个平台游戏,也可能是一个上帝视角游戏,这种类型就不需要考虑重力因素。
之后就是GDD生成,文档生成,资源生成,到最后相当于提取中间这个模板,然后直接把里面的hook给填上,最后是一个验证。中间的话就是训练的过程,以及我们管线的过程。
最后就是相当于Agent在过程中会不断演化自己,比如说我们首先会维护一个meta campaign,它是一个非常原始的母模板,针对任何游戏都可以调用这个模板。随着给他一些真实认知的任务过程中,比如说建一个马里奥式的游戏,那它建完之后,我会让他把这种游戏所需要的模板提取出来,放到我们的模板库。
![]()
这样,在下次遇到比较类似的游戏的时候,就可以按图索骥,直接提取出来比较类似的模板去用,往里面填充hook就可以了,就不用从头开始写。
device skill也是针对容易出现的bug,相当于每天的一个MD file,无论是在验证过程中还是下一次从头开始生成过程中,能让它把这个东西debug好。
接下来也比较困难,也就是这个游戏怎么玩?它和普通的代码其实还不一样,普通代码你可能有compile(编译)成功、test通过就OK了。
但是游戏不一样,游戏也有三个阶段,第一个阶段是这个东西能不能编译成功,如果都不能编译成功那肯定不行。第二个阶段就是里面有没有bug,比如有些游戏做出来它可能有bug,比如我们用SOTA模型去做马里奥游戏的时候,它完全不知道这个游戏角色的身高和它能跳跃的阶梯高度之间的关系,导致这个游戏永远无法通关。
![]()
第三步,游戏最重要的是好玩,那这个趣味性又怎么衡量?这不是更难了?所以说这个东西本身衡量起来是非常非常困难的。我觉得在我们这个工作里面,现在这个阶段只能尽力做的好一些,但是我们承认肯定不是完美。我们衡量三个阶段,也就是三项,第一个是build,能不能渲染,能不能编译;第二是游戏画面怎么样,就是我们从中间截图然后给他打分。
第三是和用户意图是否一致,就是比如说我在游戏里想做几个功能,我想要这个游戏有3个关卡,某个人物有什么功能,或者我想要交互技能是WASD还是上下左右,也就是你做出来的游戏是否和用户需求一致。
![]()
从结果上看,我们这个模型和harness都取得了非常好的效果。
Web Gamedev的痛点
最后想讨论的是web gamedev目前的几个痛点以及未来的几个方向。
![]()
第一个就是LLM和Code Agent的3D空间理解问题。当然,我们的OpenGame主要聚焦的还是2D游戏,下一个我们已经在做的相当于是OpenGame 3D吧,我们已经在做了。
从我们最开始做的时候就发现有几个比较重要的问题。第一个是3D的问题,比如说,LLM通过Unity或者Unreal的MCP去用或者调用API生成一些3D资产,但生成之后,比如说我想搭一个赛车的跑道,然后我跟它说要搭一个赛车道,旁边要有一堆树。然后这个agent会调用一些API来生成3D的资产,但是它不知道怎么摆,它心里面没有这个东西。比如常规我们应该是中间一条路,树是在两边,这是比较正常思维的一个场景。
但很有可能,他会把一棵树垒到另一棵树的上面,或者说它把树就种到路的中央。就是说,它不知道怎么去管理3D布局,这是非常重要的一个问题。然后像其他的一些比如说穿模,比如说你生成了一些NPC,一生成直接就卡墙里了。
从我们看,这是相当重要的一个问题,我们觉得模型本身是缺乏3D空间先验的,它在text token序列里面推理没有空间的理解能力。一些可能的方向,比如说符号化的空间表示,或者动态闭环,或者物理碰撞信号,这i可能是一些解决的思路。
至于我们是怎么解决,如果大家感兴趣的话,我们会在七八月份的时候会发布出来OpenGame 3D,我们也给出了一些解决方案实现了一些比较好的效果,到时候大家可以关注一下。
![]()
第二个点,我认为是非常重要的一个点,就是这个Game Agent怎么去eval,也就是怎么去“玩”到“体验”。这个也不是我说的,之前我跟Unity交流,他们在Gemini 3之后就大力发展AI业务,大家交流认为eval是最痛点的一个阶段,无论是你的agent group里怎么给验证反馈,还是说用RL训练的时候怎么给reward,其实都是非常非常中国要的。
我们大概分两条思路,大概是这么想的:第一个是黑盒的,相当于Game-VLA,就是我们input实时有一句话,就是完全模仿人,因为我不知道游戏的源码怎么搞,只知道这个游戏相当于是一个SDK,直接就用。那就是看这个游戏的画面然后输出动作,相当于像玩家一样把整个游戏玩一遍。
但是我们目前尝试有几个问题,首先这个路线,也就是Game-VLA路线,用现在的仿真模型,在zero-shot情况下走不通,也就是如果是他没见过的游戏让它直接玩,基本上它就是不会玩,效果很差。一个可能的解决方案是用few-shot去做,就是你把比较像的给他做一个in-context-learning(情景学习),或者把这个游戏一些比较重要的交互生成一些技能给他塞到这个context里面让它知道。
这个还有个问题是,比如你真的用Game-VLA去做的话,你想要检验这个游戏中的功能,比如说这个游戏有3关,我想测试第2关,那就必须把第一关玩完之后才能玩第二关。但有一个很大的问题,就是它能不能玩到第二关都不一定。
而且如果一个游戏有50关,我想要测试第49或者第50关,那非要把前面所有关都玩完吗?这个就太慢了,这就完全不可行,无论是agent loop还是rollout都太长了,完全没法做,可能训一个step就要好几天,完全没办法训练。
![]()
所以权宜侧可能就是白盒这样的东西,因为LLM、code agent生成的游戏,它的源码是完全accessable的,知道它代码是怎么写的,那么我们可以做一些白盒runtime state injection。核心洞见就是,把玩到某个状态,直接pass到某个状态。
因为游戏它其实就是一个state machine,原先的Game-VLA黑盒玩法是通过一个agent去玩到某个状态。这个state injection就是直接不玩,把参数改到对应state就行。
大概说一下白盒方案的一些思路,比如说直接抽调keypoint,这当然也需要LLM去帮我们,然后往里面注入,再去执行。这个比较快比较稳,但局限就是仅限于白盒自生成游戏,我觉得如果将来技术发展到更好的话,我觉得还是有一个流式的黑盒Game-VLA,也就是它能像人那样实时去玩这个游戏。但是这个需要大模型那块把仿真人模型训练好才可以。
未来方向
![]()
未来的方向,当然是从2D到3D。OpenGame是一个偏学术性的,我看到不少创业公司也在做类似的东西了。我感觉2D的技术门槛已经没有那么高了。如果想做的人,直接在OpenGame上改一改,一周就做出来了。技术门槛可能在3D,但是对于产品我可能不是太懂,我只是从技术上来说,所以只是提供技术参考。
今天的分享就这些,谢谢大家。
你有沒有這樣的經驗:看到一篇很長的 PDF 報告、一段 YouTube 教學影片,想把它整理成投影片、做成語音 […]
這篇文章 不用下指令!用 Claude Code、Antigravity CLI、Codex CLI 搭配 notebooklm-py,一句話生成簡報、測驗、Podcast 最早出現於 軟體玩家。
![]()
Dcard 今日宣布成立企業 AI 代理事業 GNTC,推出 EntryDesk 與 VibeHost 兩大解決方案,協助企業整合既有系統、重塑人機協作模式。
隨著生成式AI從單純的對話對答,全面進化為具備自主執行任務能力的「代理AI」 (Agentic AI),企業如何將其無縫融入既有工作流程已成為當前最大挑戰。台灣社群平台Dcard今日 (5/28)宣布跨足B2B企業市場,成立全新的企業AI代理事業「GNTC」,藉由將過去一年來內部全面推行「Agent-Native」 (AI代理原生)的實戰轉型經驗產品化,GNTC首波推出EntryDesk與VibeHost兩大核心解決方案,協助企業在兼顧資安防護與資料治理的框架下,重塑新世代的人機協作營運模式。
不僅是導入工具,而是重塑價值鏈的實戰經驗
GNTC的誕生,很大程度上源自於Dcard自身的數位轉型陣痛與成果。自2025年起,Dcard內部便開始全面推動Agent-Native轉型。這並非單純發放AI帳號給員工,而是從底層建置跨工具的代理平台,從財會、廣告、產品到行銷團隊,員工自主建立數百個AI應用場景。
以Dcard自家的廣告團隊為例,透過導入自動化流程與AEO (Answer Engine Optimization)優化能力,團隊能將過去必須仰賴人工上架的廣告素材處理、資訊蒐集與提案產出全面排程自動化,整體流程處理時間驚人地縮短超過80%。
Dcard創辦人暨執行長林裕欽指出:「過去一年,我們重新梳理每個部門的工作流程,找出真正能被AI代理賦能的價值鏈。GNTC的目標是把這套從內部實戰累積出的經驗,變成企業可以直接導入的解決方案」。
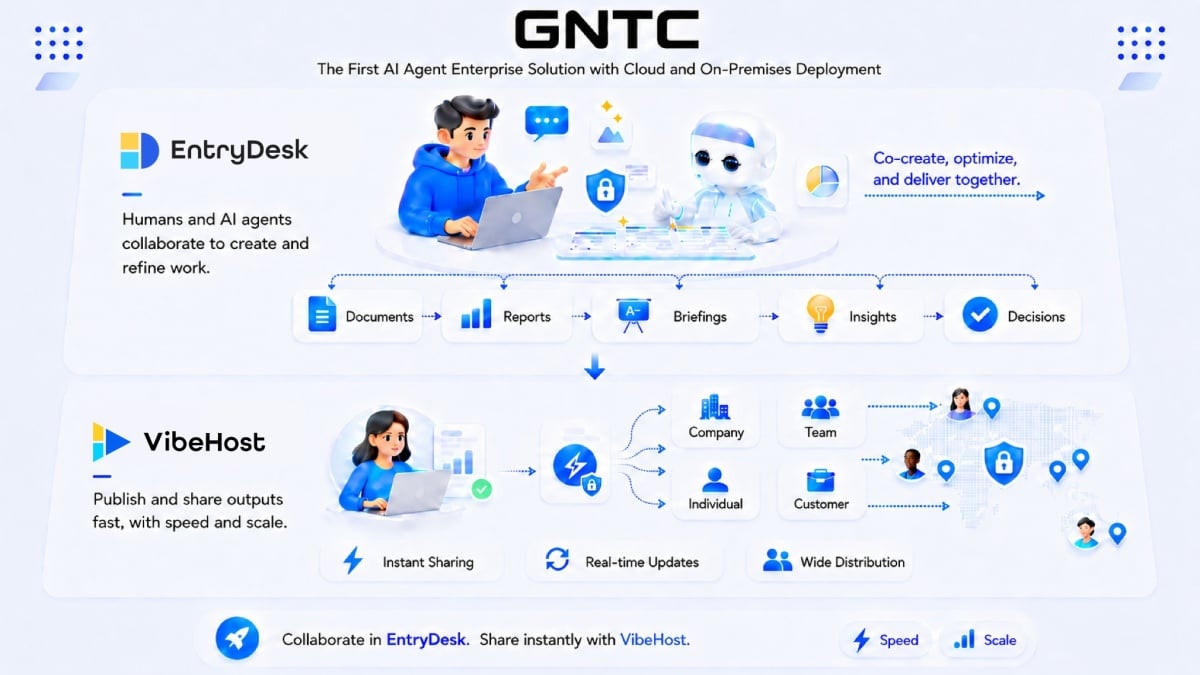
兩大核心產品:打通企業內部系統的任督二脈
針對企業導入AI代理時常遭遇的「系統破碎化」與「產出難以分享」兩大難題,GNTC這次端出具備高度針對性的雙箭頭產品:
EntryDesk定位為企業導入AI代理的「整合樞紐」。它能直接串接企業既有的內部系統,並且統一管理資料權限與工作流程。員工不再需要於多個AI工具與內部系統間痛苦切換,透過跨平台 (涵蓋網頁、iOS、Android、macOS、Windows與CLI)的一致性介面,即可跨系統查詢資料、排程任務。
更重要的是,它能共享企業內部的「情境層」 (Context Layer),讓AI代理真正讀懂公司的運作脈絡;同時內建權限控管機制,確保機敏資料的合規性。
這是一款以Agent Experience (AX)優先思維設計的佈署與協作平台。當AI產出網站、內部簡報、商業提案或互動程式後,使用者只需一道指令,幾秒內就能生成專屬私有連結進行安全分享。
VibeHost提供CLI、MCP與Chrome 擴充套件等多元介接方式,並且支援密碼保護與權限驗證,徹底解決過去AI生成物難以在團隊間快速流轉、審閱與協作的痛點。
瞄準高機敏產業:「地端佈署」與FDE顧問戰隊雙管齊下
除了常見的雲端佈署外,GNTC的解決方案全面支援地端佈署 (On-premise),這對於資料絕對不能上雲的金融、醫療、法務及政府等高機敏產業而言,無疑是極具吸引力的敲門磚。
此外,GNTC並非只賣軟體授權,更同步成立前線佈署工程師 (Forward Deployed Engineer, FDE)顧問團隊。這支戰隊將直接深入企業內部,協助盤點既有工作流程、客製化設計AI代理應用情境,並且從系統架構層面推動實質的AI雙軌轉型。
相信一提到「NAS」,對大多數人來說第一時間都是想到備份照片、放影片、做 Time Machine… […]
The post 這台 NAS 不只備份還能養龍蝦?QNAP TS-464 完整開箱與使用心得 appeared first on 電腦王阿達.
![]()
【GameLook专稿,禁止转载!】
![]()
GameLook报道/今天的国内科技股也算是过上了好日子。
此前的中国科技股板块,都是搞硬件的企业各种发大财。反观那些做应用、生态、大模型的公司,却因为高昂的资本支出,以及投资者对其产出不达预期的担忧,导致一个个迎来股价闪崩。
但在6月2日,科技股终于迎来了一个好消息:港股上市的美团、阿里、腾讯三家中国公司连番大涨,上演一出夺回股价失地的大场面。
GameLook作为游戏媒体,最关心的自然还是腾讯。截至6月2日收盘,腾讯公司股价报480港元/股,涨幅达10.09%,总市值超4.38万亿港元,创下自2021年1月25日以来单日最高涨幅纪录。
![]()
为何是这三家上市公司引领今日科技股大涨?美团刚刚发布2026年第一季度业绩,由上季度的161亿元减少至65亿元。美团的大幅减亏也说明了一件事:外卖大战即将迎来尾声。同样卷入其中的阿里,可以预见也会降低投入。至少在一季度,外卖行业的内卷整治已经出现较好的迹象。
但阿里还有另外一重身份,腾讯的主力业务也不涉及外卖、电商,这一轮股价大涨更多绕不开AI。字节、阿里跟腾讯都是国内押注AI最猛的巨头,一些AI相关的利好消息,就是能够直接影响腾讯股价。
6月2日,据外媒《金融时报》报道,两位知情人士透露,腾讯目前已完成微信内嵌AI智能体的原型测试,最快将于6月启动公开上线前所需的合规审批流程。完成合规程序后,腾讯计划先向小范围外部用户开放测试,再逐步扩大推广,目前日期尚未确定。
![]()
微信AI智能体开放测试和上线时间,最终需要腾讯公司官宣。对腾讯而言,无疑是一件开天辟地的重要事件,据报道,腾讯已将此次推出AI智能体列为最高战略优先级。
可以预见,未来微信不仅仅可以同人聊天、与小程序互动,还可以跟AI智能体进行直接对话、自动调用微信数百万个小程序、乃至小游戏进行互动,将构成10亿+中国网民使用微信的又一个重要理由。微信基于AI智能体展开的商业模式,想象力巨大。
此前,因为没有上市、始终游离在资本市场的字节跳动,每每因为豆包、Seedance等AI能力传出利好消息,会反向制造港股上市科技公司的业务焦虑。大家也都很担心,港股上市的腾讯、阿里能否扛得住。
如今也到了腾讯绝地反击的时刻,即将在微信内嵌未来AI最重要的形态“智能体”,用自己最强大的护城河重新瓜分AI这块蛋糕——这个动作的象征意义,远大于短期内产生的回报,也让我们看到了中国新一轮AI长期竞争的开始,
微信内置AI助手,能有多“恐怖”?
2025年爆火的Manus,较早兑现了“AI替你打工”的可能性,给国内用户和从业者带去了第一轮震撼,甚至惊呆了老外。Meta一度官宣将以超20亿美元的价格收购Manus母公司蝴蝶效应,当然最后成为首个被公开叫停的AI领域外资收购案。
Agent带来的第二轮震撼,则是今年3月的“龙虾热”。这一次,不再只是开发者的狂欢,消费端的大众也积极参与进来。当时,腾讯拿出了空前的决心,宣布所有业务条线全部支持一键“养虾”,单日股价随即暴涨7.27%。
![]()
如果说,之前的“龙虾”热腾讯还能参考别人的成功路径,这次用微信以身入局的腾讯,需要开始学着自己思考:微信内嵌智能体会是什么形态?Agent该如何同微信生态、商业模型结合?
可以想象,一旦腾讯量身定制的智能体方案上线,且能够充分发挥微信自身优势,这将是腾讯在智能体领域最狠的大招,没有微信的友商根本学不来。因此,腾讯接近推出微信AI助手的消息一经流出,随即引发港股投资者狂欢,股价立刻暴涨。
这种狂欢的氛围甚至会逐步传染,想象空间不断蔓延开来,一旦腾讯拿出了自己的智能体,阿里可能也会跟进……此前股价阴跌不止的中国科技股,随即展现出一副绝地反击的态势。卷不动的外卖大战,以及腾讯测试微信的AI智能体原型的消息,共同造成了今天港股科技股的大涨。
目前,微信已经嵌入具备搜索功能的AI智能助手“元宝”,但并非完整的智能体。更让外界好奇,微信即将内置的AI智能体助手,会带来什么样的新体验?
![]()
根据《金融时报》报道:据曾观看早期演示的知情人士介绍,用户可通过在微信主界面向右滑动,进入AI智能体的对话框。用户可以通过对话输入指令,智能体可以自动调用小程序执行该指令,比如查找咖啡馆并根据口味下单等任务。
GameLook认为,微信AI助手的最大价值,除了整合信息流、视频流、工作流之外,就是挖掘微信数百万小程序的互通。小程序本就是腾讯主导的一个可怕生态,智能体让整个小程序生态互通后,有望将微信的商业化潜力发扬到新高度。
作为超级APP的微信,是马斯克一直以来的“意难平”。不只是小程序,当智能体进一步将微信的整个信息流、视频号、电商、资金流……全部串联起来,AI时代一个最庞大的生态图景就此展开。
当然微信AI助手是否能有想象中的威力,需要一步步实现。用户第一时间使用的,永远都是个beta版。最终版本还需要随着用户使用不断调整、优化。一旦整个格局打开,下一个紧张的就该是阿里、字节了。
用户的时间和注意力都是有限的,全面布局的微信,必然会影响到阿里、字节旗下AI产品的用户时长和活跃度。一涨一跌,腾讯有望靠Agent再赢下属于自己的一城。
韩国人先给微信智能体打了个样?
微信内嵌AI智能体,让中国投资者表现得“一惊一乍”。但隔壁韩国,为了干好AI、出售游戏业务的Kakao已经花了一年多时间聚焦AI agent,目标是让所有5000万KakaoTalk用户都拥有个人AI智能体。
![]()
目前,Kakao AI Agent可以在单一聊天窗口内完成跨平台任务,具备美妆、时尚、零售、税务、旅行、就业、餐饮、高尔夫预订等能力;自动识别对话中的日程、约会和计划并发送提醒;基于对话上下文推荐商品并引导完成支付。
很多人没意识到,腾讯本就是Kakao股东,Kakao AI Agent相当于微信AI助手的“测试版”。腾讯内部AI智能体开发团队自然会了解海外产品的部署、具体表现形式、各功能使用率等情况。
当然,Kakao Talk并不等同于微信,Kakao自身虽然一直在研发Kanana大模型、还其性能显然并不属行业顶级之列,也没有强大的小程序生态,甚至很多功能都是照搬微信,但小程序生态与腾讯存在巨大落差。双方用户体量也有巨大差异,前者只有5000万用户,微信月活高达14亿。
![]()
Kakao相当于给腾讯内部团队打了样,测试用户对于AI智能体的接纳度。至少说明腾讯不是完全从0到1的冒险,外部投资公司的尝试一定会被腾讯消化吸收,再结合微信自身的特点转化。
目前大家最担心的是,微信内置智能体上线后,AI算力供应能否支持所有微信用户的正常体验。高频使用AI和Token消耗带来的巨额账单,已经让越来越多海内外大厂都直呼压力山大。
Uber的CTO Praveen Neppalli Naga透露,约5000名工程师四个月内就烧完了公司2026年的AI预算;海外一家科技巨头,短短一个月内烧掉了5亿美元的Claude账单;2026阿里云峰会上,《崩坏》系列AI NPC & Gameplay技术团队负责人郑银河透露,内部员工建了几十个Agent共同协作,一晚上烧了价值200万元人民币的Token。
![]()
14亿MAU的微信用户同时段使用,是否会让腾讯AI算力供应直接爆炸,或是导致出现排队等待、分时使用等影响体验的情况,是所有用户目前最担心的地方。
在GameLook看来,Kakao至少做对了一件事,值得其他厂商学习。其Kanana in KakaoTalk以及设备端的Kakao Nano模型,使用个人智能助理使用设备端处理,即所有聊天分析在本地完成,不发送数据到服务器。微信有一定条件向这种方案靠拢。对算力的吞吐量、资金压力都有一定程度的缓解,值得借鉴。
做微信AI智能体,腾讯“不急”
海外公司可参考之外,微信加速推进内嵌AI智能体计划的最大底气,是前OpenAI研究员姚顺雨的加入。
如果说,张小龙掌舵微信这艘大船,将整个超级APP生态做得相当扎实,真正兑现了Metaverse这件事。姚顺雨的加入则为微信带来了一个最强大的能力,用智能体将微信生态和能力全部串联起来,让用户真正步入智能化的AI时代。
去年的一档播客节目里,在被问及“如果是微信的一号位,你怎么在微信里做Agent”的问题时,姚顺雨的回答是:“不急”。
姚顺雨表示:“为什么要急着进攻?比较危险的是一个颠覆性的创新。真正的危险,不是说一个类似于微信的东西打败了微信,而是一个很不一样的东西打败了微信。需要对颠覆性创新有所警惕,但如果是这些incremental(渐进式的)创新,这种小的创新,早做晚做可能区别没有那么大,也不用太担心。”
这一想法似乎也代表了腾讯管理层的态度。早在2025年第三季度财报电话会上,腾讯总裁刘炽平就首次系统披露微信AI化战略蓝图,明确表示“微信最终会推出一个AI智能体”。但直到2026年才传出完成原型测试、即将启动合规审批流程的消息。
中国科技巨头的AI大战里,腾讯从不是最激进的那个,也不打没准备的仗。即使是在Agent最火热的那段日子里,腾讯依旧选择等大家都烧钱试错弄明白了,才加速推进微信的AI智能体计划,稳扎稳打地兑现预期。
微信推出AI智能体,决定了未来腾讯公司价值能否再攀高峰。即从一家市值几千亿美元的公司,在未来真正步入步入万亿美元市值的公司,成败在此一举。
就像GameLook曾经说的那样,如今腾讯的一切问题,都是AI的问题。微信把AI智能体这条路走通,将是所有投资者最希望看到的一幕。
過去阿達已經寫過不少 Hermes Agent 教學,甚至拍影片一部部帶大家怎麼操作。雖然以前已經很簡單了,但還是需要透過 CLI 介面來安裝和設定,對於一些科技小白來說,可能不太容易適應。而好消息是,Hermes Agent 官方的桌面版應用程式終於正式登場,不僅輕鬆一鍵安裝,操作介面也跟現今的多數 AI 工具一樣,非常容易上手,Windows、macOS 和 Linux 都支援。
The post Hermes Agent 官方正式推出桌面版應用程式!輕鬆一鍵安裝,科技小白也能快速上手 appeared first on 電腦王阿達.
企業幫員工配備越多 AI 工具,生產力一定隨之提升嗎?這個迷思,在 Google Cloud 舉辦的 Agentic Work: Live + Labs Taipei 2026 獲得解答!
當生成式 AI 大幅融入工作流程,企業深怕在商業賽道落後而瘋狂部署各種 AI 工具。根據 Boston Consulting Group 數據,凸顯矛盾處境,當員工頻繁遊走在未經整合的 AI 應用程式,反而受困情境切換(Context Switching)而打斷思緒,最終導致生產力下滑、身心更感疲憊。
而另一調查則顯示反面情況,有的企業在 AI 轉型路上更顯踟躕。Google Workspace 針對全球約 2,600 位 IT 與業務決策者進行調查,放眼望去真正實現高度轉型的企業僅佔 3%,多達 72% 企業還在觀望。而且他們仍將 AI 視為一問一答的機器人,距離 AI 真正釋放商業潛能還有一段距離。換言之,要橫跨平凡到不凡的 AI 鴻溝,企業該怎麼走?這場 Google Cloud 提出的新典範思維是「關鍵不是 AI 工具數量,而是底層架構能否深度整合」。
「一個 AI 有多聰明,完全取決於它能拿到多少 Context。」Shannon Tong, Head of Google Workspace, North Asia 一開場就點出,為什麼有的公司 AI 遲遲無法進化成可推理、規劃與主動執行任務的代理癥結點。
背後關鍵來自於長年的架構壁壘,導致數據散落在各孤立系統,無形中在應用程式邊界築起情境之牆(Context Wall),迫使員工在不同視窗轉換,不斷向不同 AI 重新解釋問題背景。因此要讓代理更聰明,就必須打破情境之牆。
這也是為什麼 Shannon 提到一項關鍵做法,企業若要邁向新型態的整合工作架構,必須高度整合個人與團隊情境(Work Context)與企業營運情境(Enterprise Context)。等於讓 AI Agents 深入員工的 Gmail、Google 文件或 Google 雲端硬碟理解其工作脈絡,同時又橫跨 ERP、CRM 與資料庫等後端系統,掌握結構數據做深度推理,得以發揮乘數效應(Multiplier Effect)。
要落實上述場景,Google Cloud 提供三大服務賦能企業。首先是「整合」,在嚴格合規下提供共享 Context 的原生雲平台;其次是「最佳化」,基於端到端 AI 架構與持續優化的算力,透過龐大上下文視窗(Context Window)技術,讓 AI 讀取海量企業文件與歷史紀錄,持續掌握內部業務數據洞察;最後是「開放性」,確保平台與企業既有系統、第三方系統協作無礙。
企業導入 AI 過程,為什麼常犯「拿著鐵鎚找釘子」的錯誤決策? Marku Hao-Yu Lee, Head of R&D, ADDcn Technology Co., Ltd 舉例,他們曾把 90 秒可填完的表單,硬是套入 AI Chatbot,反讓員工多花 5 分鐘打字溝通,凸顯並非所有工作流程都適合塞進 AI。
事實上,AI 轉型的關鍵是化阻力為助力。Marku 分享他們的一套心法,先引導員工用紙筆畫出工作流來建立自動化思維,接著研發部利用 Workspace Studio 串接 Gmail 與 Google 雲端硬碟,為採購人員自動核算繁雜的跨部門帳單。當員工真實嚐到效率倍增的甜頭,就會從排斥轉為主動提出需求。
由此可見,數字科技的轉型策略的精髓,是讓人機溝通的模式從「指令式」邁向「意圖式」。Marku 再舉自家公關部門的案例,過去要修改集團官網的財報或新聞稿數字,同仁須按傳統流程開立工單給工程師,一來一往修改後台往往耗費半天以上。現在公關夥伴只需在 Google Chat 輸入明確的修改意圖,AI Agent 便自動更改網頁代碼並送入預覽環境;待公關確認無誤,系統便自動觸發 CI/CD 流程發布上線。
隨著 AI 融入工作流程,影子 AI(Shadow AI)的情況有增無減!Alpha Zhang, Head of J/APAC, Solution Engineering, Platforms & Devices Enterprise Solutions, Google 分享來自 Melbourne Business School 的研究數據,高達 70% 員工曾在企業內使用免費但未被公司授權的 AI 工具。這類影子 AI 情況正因員工為求效率,私下餵養機敏資料給外部模型,無形中就隱含了資安破口。
為防堵威脅,Alpha 分享當前即時且有效率的防禦焦點,將落在「瀏覽器」身上。想像一位員工遠距辦公的情境,Chrome 企業進階版(CEP)能辨識哪些隸屬公司列管或是個人筆電的設備。當員工是用個人電腦查看公司內部系統及機密資料時,CEP 會自動跳出警示,或針對機敏內容壓上浮水印,甚至從源頭封鎖下載、截圖與複製貼上等高風險行為。
由此可見,CEP 能展現動態遮蔽(Data Masking)的防禦效果,自動隱藏敏感數字以防側錄;也能結合虛擬化技術,將零信任防護無縫套用到版本較老舊的 Windows 架構系統。然而,預防側錄只算防守到一半力道,另一半還要防止員工將機密外流到未授權的平台,特別是新 AI 工具如雨後春筍般出現,CEP 可以不用手動設定黑名單,而是改用網站類別角度進行智慧攔截,讓企業在絕對安全的框架之下,無後顧之憂釋放代理的潛能。
對工作者而言,更關心是如何真正用對 AI,幫助自己工作不僅提高效率,更展現高階商業價值。Samuel Feng, Customer Engineering, Greater China, Google Workspace 在現場帶來 Google Cloud Next '26 最新亮點,親自演繹一段極端天氣引發門市客流危機的真實場景。
在該情境中,員工一天的開始不再盲目爬梳信件,而是由 AI Inbox 主動提出有營運異常的信件。尋求解方時,員工在 Google Drive Projects 功能中詢問公司內部 SOP,透過內建 Gemini 與 NotebookLM 底層檢索技術的強大能力,立刻精準給出「吧台增 20% 人力」的指引。為釐清客流深層原因,員工向 Gemini 下達意圖,其統籌代理(Orchestrator)開始自動透過模型上下文協定(MCP),跨系統向 BigQuery 撈取天氣與排班數據進行交叉分析。
接著,將這些數據洞察匯入 Google 試算表,結合 Gemini 的 Canvas 生成動態儀表板;並於 Google 文件套用企業模板快速產出改善企劃書。企劃書再轉到 Google 簡報生成企業專屬品牌的簡報內容,並透過 Google Vids 產出動態的影音報告。最後,開發人員透過 Gemini CLI 讀取先前生成、存放在 Google 雲端硬碟中的雲端企劃,自動撰寫互動式網頁程式碼,並將成果發送到 Google Chat 專案群組中。
Samuel 示範從發現問題到任務解決,全程在 Google Workspace 生態系,達成一站式的人機協作。凸顯出以 Gemini 為大腦的 Multi-Agent 聯軍,翻新日常工作與商業營運模式已是現在進行式。
透過本次工作坊的知識饗宴,引發與會者思考企業需要的不光是技術工具,更是思維的翻轉。Shannon 總結時強調,員工不應恐懼工作被取代,而是要思考如何利用 AI 提升價值;而企業在追求 Agentic AI 生產力並將其融入工作流的過程,更仰賴如 Google Cloud 具備嚴格安全治理的雲端平台,來妥善管理這些代理程式。這場變革速度只會越來越快,企業唯有立刻行動,才能在這一波智慧浪潮之中站穩腳步。